 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Models to Generate, Recognize, and Reframe Unhelpful Thoughts
Jul 06, 2023Many cognitive approaches to well-being, such as recognizing and reframing unhelpful thoughts, have received considerable empirical support over the past decades, yet still lack truly widespread adoption in self-help format. A barrier to that adoption is a lack of adequately specific and diverse dedicated practice material. This work examines whether current language models can be leveraged to both produce a virtually unlimited quantity of practice material illustrating standard unhelpful thought patterns matching specific given contexts, and generate suitable positive reframing proposals. We propose PATTERNREFRAME, a novel dataset of about 10k examples of thoughts containing unhelpful thought patterns conditioned on a given persona, accompanied by about 27k positive reframes. By using this dataset to train and/or evaluate current models, we show that existing models can already be powerful tools to help generate an abundance of tailored practice material and hypotheses, with no or minimal additional model training required.
Dancing Between Success and Failure: Edit-level Simplification Evaluation using SALSA
May 23, 2023



Large language models (e.g., GPT-3.5) are uniquely capable of producing highly rated text simplification, yet current human evaluation methods fail to provide a clear understanding of systems' specific strengths and weaknesses. To address this limitation, we introduce SALSA, an edit-based human annotation framework that enables holistic and fine-grained text simplification evaluation. We develop twenty one linguistically grounded edit types, covering the full spectrum of success and failure across dimensions of conceptual, syntactic and lexical simplicity. Using SALSA, we collect 12K edit annotations on 700 simplifications, revealing discrepancies in the distribution of transformation approaches performed by fine-tuned models, few-shot LLMs and humans, and finding GPT-3.5 performs more quality edits than humans, but still exhibits frequent errors. Using our fine-grained annotations, we develop LENS-SALSA, a reference-free automatic simplification metric, trained to predict sentence- and word-level quality simultaneously. Additionally, we introduce word-level quality estimation for simplification and report promising baseline results. Our training material, annotation toolkit, and data are released at http://salsa-eval.com.
LENS: A Learnable Evaluation Metric for Text Simplification
Dec 19, 2022



Training learnable metrics using modern language models has recently emerged as a promising method for the automatic evaluation of machine translation. However, existing human evaluation datasets in text simplification are limited by a lack of annotations, unitary simplification types, and outdated models, making them unsuitable for this approach. To address these issues, we introduce the SIMPEVAL corpus that contains: SIMPEVAL_ASSET, comprising 12K human ratings on 2.4K simplifications of 24 systems, and SIMPEVAL_2022, a challenging simplification benchmark consisting of over 1K human ratings of 360 simplifications including generations from GPT-3.5. Training on SIMPEVAL_ASSET, we present LENS, a Learnable Evaluation Metric for Text Simplification. Extensive empirical results show that LENS correlates better with human judgment than existing metrics, paving the way for future progress in the evaluation of text simplification. To create the SIMPEVAL datasets, we introduce RANK & RATE, a human evaluation framework that rates simplifications from several models in a list-wise manner by leveraging an interactive interface, which ensures both consistency and accuracy in the evaluation process. Our metric, dataset, and annotation toolkit are available at https://github.com/Yao-Dou/LENS.
EntSUM: A Data Set for Entity-Centric Summarization
Apr 05, 2022
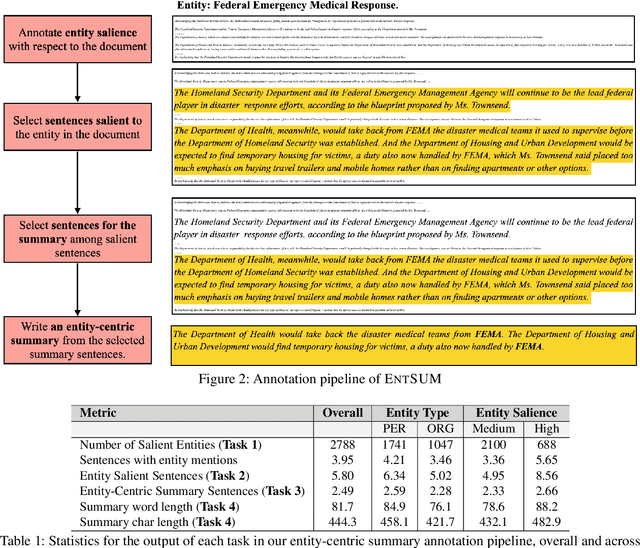

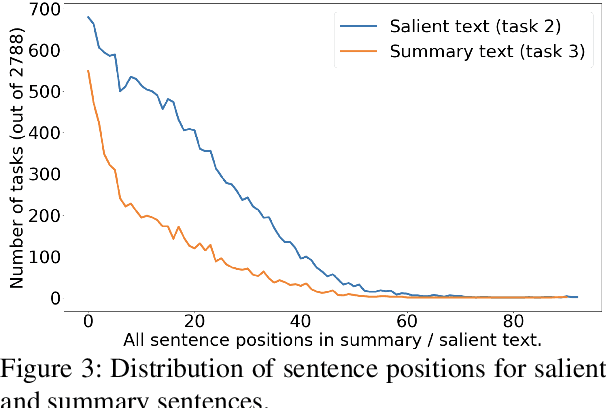
Controllable summarization aims to provide summaries that take into account user-specified aspects and preferences to better assist them with their information need, as opposed to the standard summarization setup which build a single generic summary of a document. We introduce a human-annotated data set EntSUM for controllable summarization with a focus on named entities as the aspects to control. We conduct an extensive quantitative analysis to motivate the task of entity-centric summarization and show that existing methods for controllable summarization fail to generate entity-centric summaries. We propose extensions to state-of-the-art summarization approaches that achieve substantially better results on our data set. Our analysis and results show the challenging nature of this task and of the proposed data set.
BiSECT: Learning to Split and Rephrase Sentences with Bitexts
Sep 10, 2021
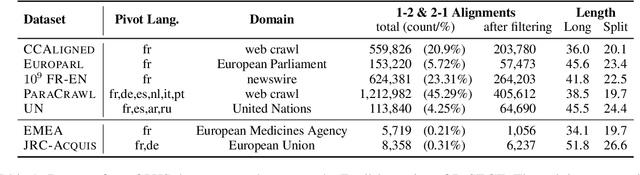
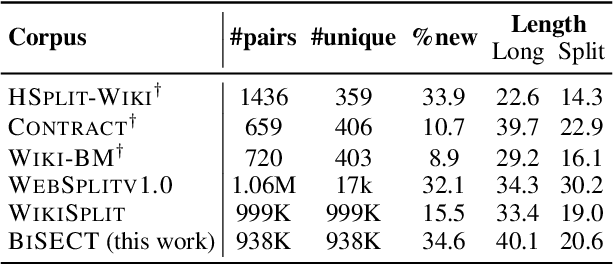
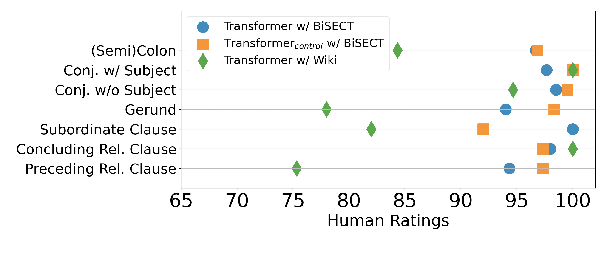
An important task in NLP applications such as sentence simplification is the ability to take a long, complex sentence and split it into shorter sentences, rephrasing as necessary. We introduce a novel dataset and a new model for this `split and rephrase' task. Our BiSECT training data consists of 1 million long English sentences paired with shorter, meaning-equivalent English sentences. We obtain these by extracting 1-2 sentence alignments in bilingual parallel corpora and then using machine translation to convert both sides of the corpus into the same language. BiSECT contains higher quality training examples than previous Split and Rephrase corpora, with sentence splits that require more significant modifications. We categorize examples in our corpus, and use these categories in a novel model that allows us to target specific regions of the input sentence to be split and edited. Moreover, we show that models trained on BiSECT can perform a wider variety of split operations and improve upon previous state-of-the-art approaches in automatic and human evaluations.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Controllable Text Simplification with Explicit Paraphrasing
Oct 21, 2020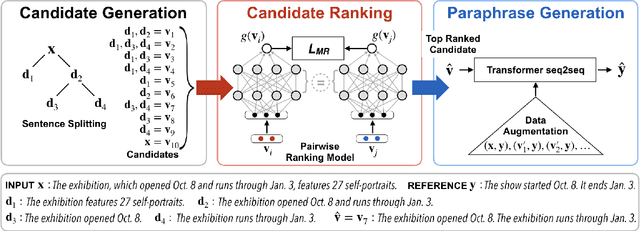
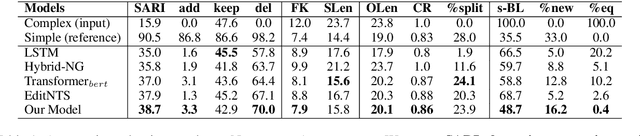
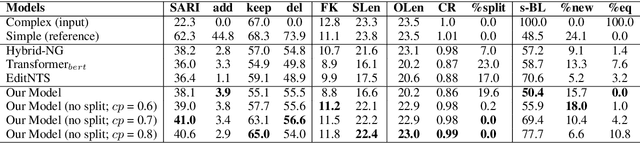
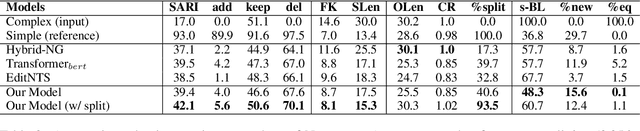
Text Simplification improves the readability of sentences through several rewriting transformations, such as lexical paraphrasing, deletion, and splitting. Current simplification systems are predominantly sequence-to-sequence models that are trained end-to-end to perform all these operations simultaneously. However, such systems limit themselves to mostly deleting words and cannot easily adapt to the requirements of different target audiences. In this paper, we propose a novel hybrid approach that leverages linguistically-motivated rules for splitting and deletion, and couples them with a neural paraphrasing model to produce varied rewriting styles. We introduce a new data augmentation method to improve the paraphrasing capability of our model. Through automatic and manual evaluations, we show that our proposed model establishes a new state-of-the-art for the task, paraphrasing more often than the existing systems, and can control the degree of each simplification operation applied to the input texts.
Neural CRF Model for Sentence Alignment in Text Simplification
May 18, 2020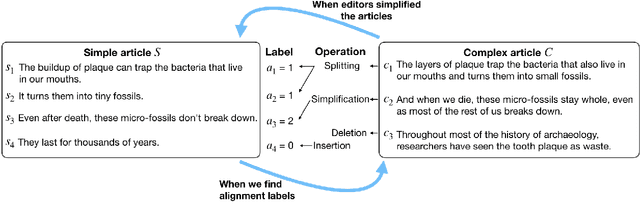
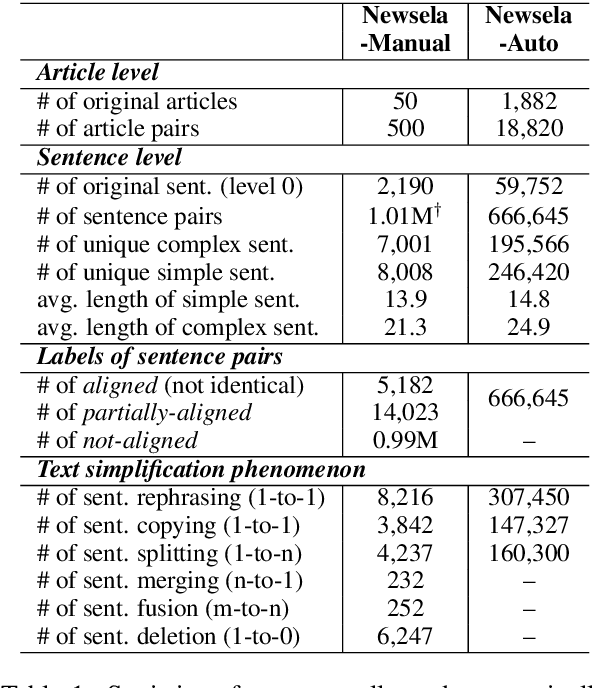
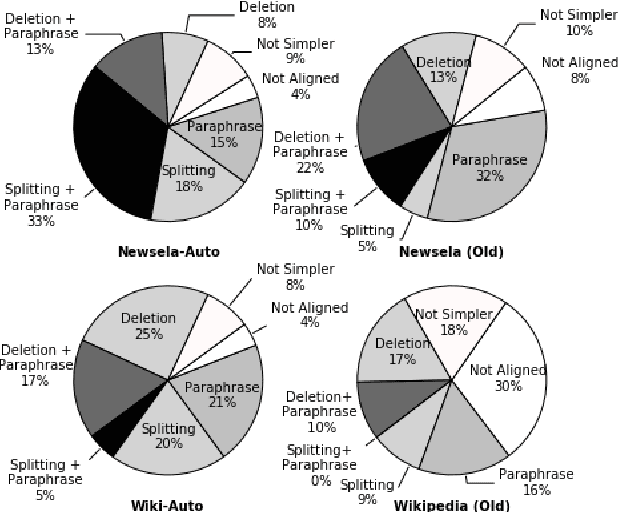
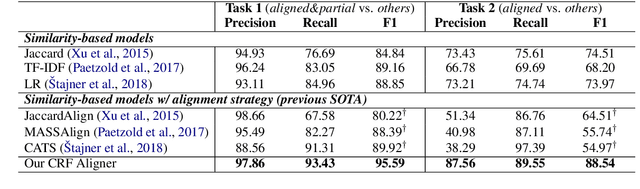
The success of a text simplification system heavily depends on the quality and quantity of complex-simple sentence pairs in the training corpus, which are extracted by aligning sentences between parallel articles. To evaluate and improve sentence alignment quality, we create two manually annotated sentence-aligned datasets from two commonly used text simplification corpora, Newsela and Wikipedia. We propose a novel neural CRF alignment model which not only leverages the sequential nature of sentences in parallel documents but also utilizes a neural sentence pair model to capture semantic similarity. Experiments demonstrate that our proposed approach outperforms all the previous work on monolingual sentence alignment task by more than 5 points in F1. We apply our CRF aligner to construct two new text simplification datasets, Newsela-Auto and Wiki-Auto, which are much larger and of better quality compared to the existing datasets. A Transformer-based seq2seq model trained on our datasets establishes a new state-of-the-art for text simplification in both automatic and human evaluation.
Code and Named Entity Recognition in StackOverflow
May 04, 2020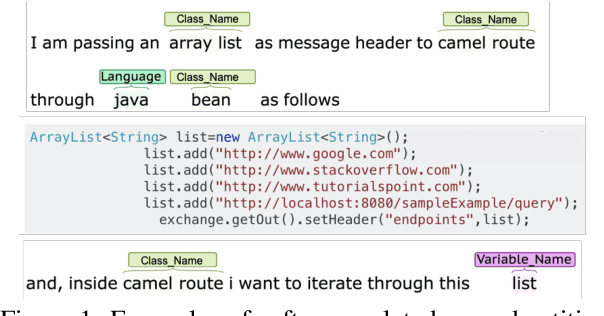
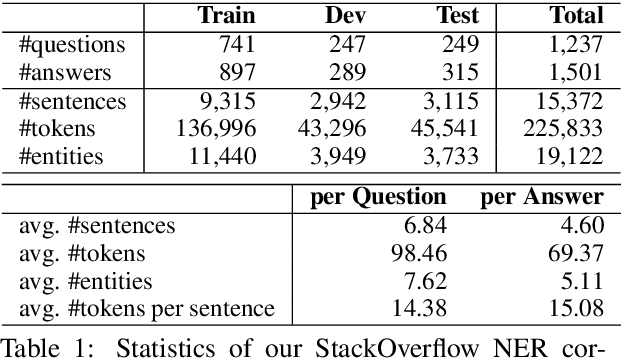
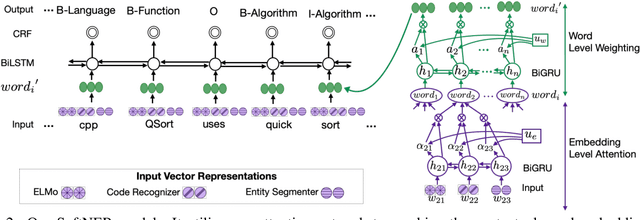
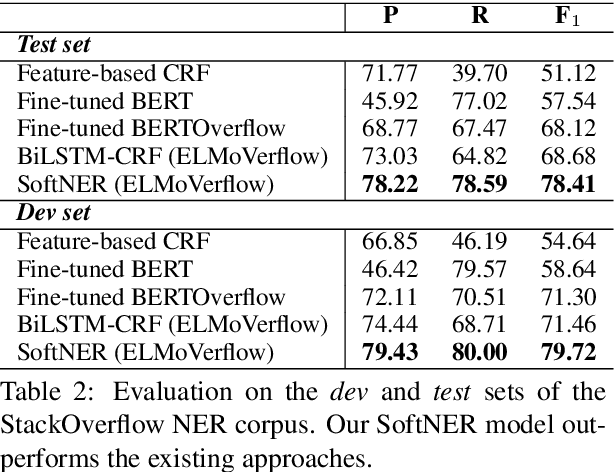
There is an increasing interest in studying natural language and computer code together, as large corpora of programming texts become readily available on the Internet. For example, StackOverflow currently has over 15 million programming related questions written by 8.5 million users. Meanwhile, there is still a lack of fundamental NLP techniques for identifying code tokens or software-related named entities that appear within natural language sentences. In this paper, we introduce a new named entity recognition (NER) corpus for the computer programming domain, consisting of 15,372 sentences annotated with 20 fine-grained entity types. We also present the SoftNER model that combines contextual information with domain specific knowledge using an attention network. The code token recognizer combined with an entity segmentation model we proposed, consistently improves the performance of the named entity tagger. Our proposed SoftNER tagger outperforms the BiLSTM-CRF model with an absolute increase of +9.73 F-1 score on StackOverflow data.
Multi-task Pairwise Neural Ranking for Hashtag Segmentation
Jun 13, 2019
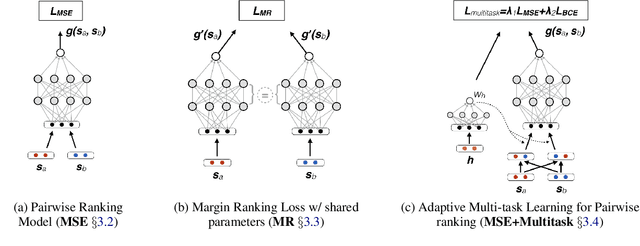


Hashtags are often employed on social media and beyond to add metadata to a textual utterance with the goal of increasing discoverability, aiding search, or providing additional semantics. However, the semantic content of hashtags is not straightforward to infer as these represent ad-hoc conventions which frequently include multiple words joined together and can include abbreviations and unorthodox spellings. We build a dataset of 12,594 hashtags split into individual segments and propose a set of approaches for hashtag segmentation by framing it as a pairwise ranking problem between candidate segmentations. Our novel neural approaches demonstrate 24.6% error reduction in hashtag segmentation accuracy compared to the current state-of-the-art method. Finally, we demonstrate that a deeper understanding of hashtag semantics obtained through segmentation is useful for downstream applications such as sentiment analysis, for which we achieved a 2.6% increase in average recall on the SemEval 2017 sentiment analysis dataset.