 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality at a Glance: An Audit of Web-Crawled Multilingual Datasets
Mar 22, 2021
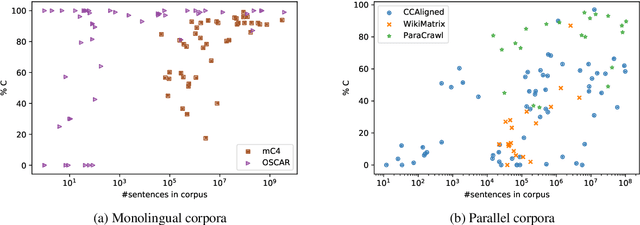

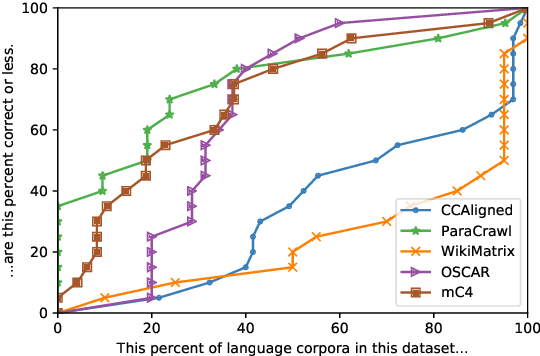
With the success of large-scale pre-training and multilingual modeling in Natural Language Processing (NLP), recent years have seen a proliferation of large, web-mined text datasets covering hundreds of languages. However, to date there has been no systematic analysis of the quality of these publicly available datasets, or whether the datasets actually contain content in the languages they claim to represent. In this work, we manually audit the quality of 205 language-specific corpora released with five major public datasets (CCAligned, ParaCrawl, WikiMatrix, OSCAR, mC4), and audit the correctness of language codes in a sixth (JW300). We find that lower-resource corpora have systematic issues: at least 15 corpora are completely erroneous, and a significant fraction contains less than 50% sentences of acceptable quality. Similarly, we find 82 corpora that are mislabeled or use nonstandard/ambiguous language codes. We demonstrate that these issues are easy to detect even for non-speakers of the languages in question, and supplement the human judgements with automatic analyses. Inspired by our analysis, we recommend techniques to evaluate and improve multilingual corpora and discuss the risks that come with low-quality data releases.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021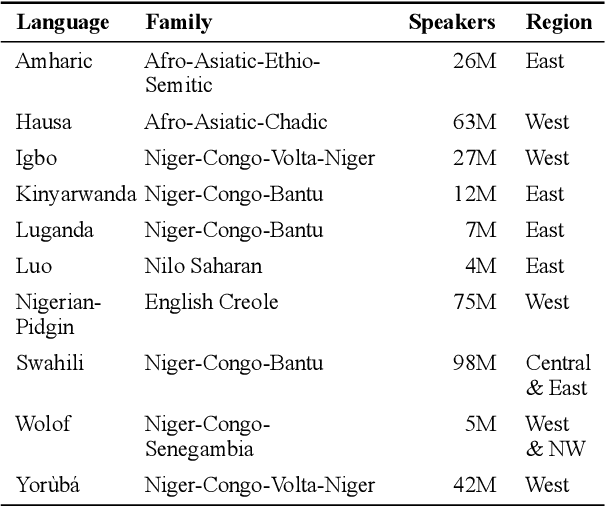

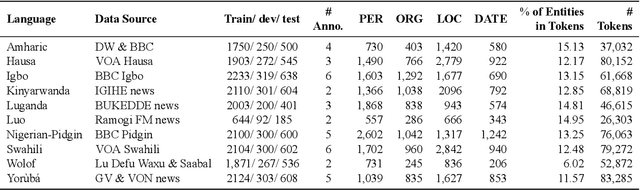
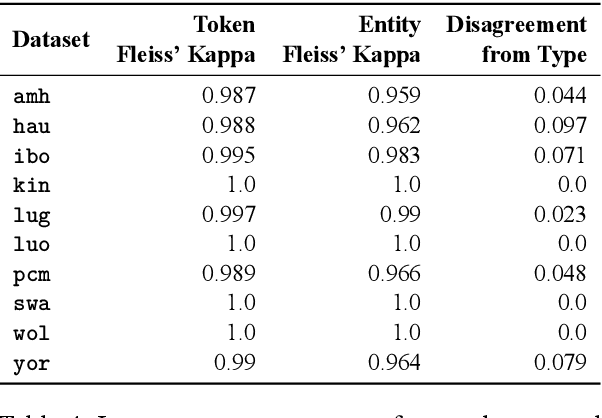
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
KINNEWS and KIRNEWS: Benchmarking Cross-Lingual Text Classification for Kinyarwanda and Kirundi
Oct 23, 2020
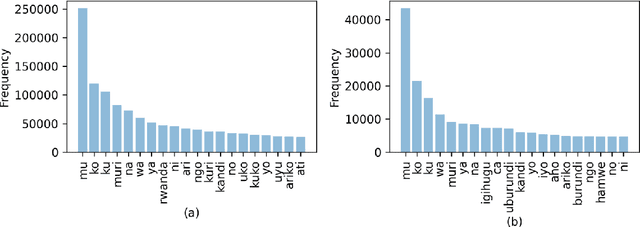

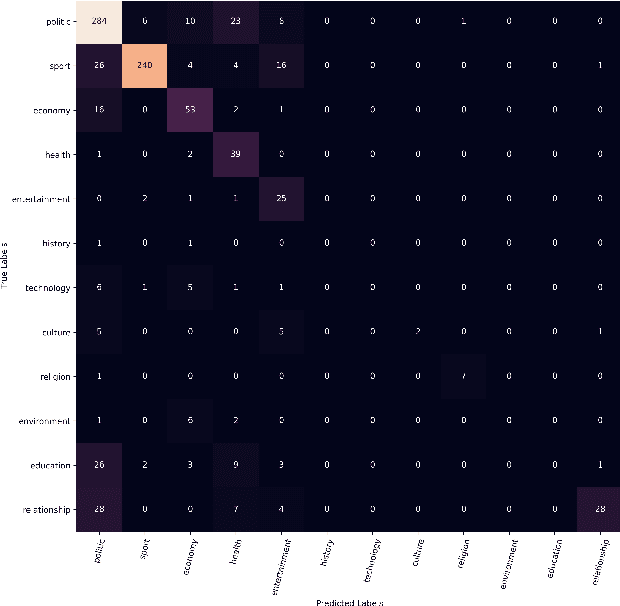
Recent progress in text classification has been focused on high-resource languages such as English and Chinese. For low-resource languages, amongst them most African languages, the lack of well-annotated data and effective preprocessing, is hindering the progress and the transfer of successful methods. In this paper, we introduce two news datasets (KINNEWS and KIRNEWS) for multi-class classification of news articles in Kinyarwanda and Kirundi, two low-resource African languages. The two languages are mutually intelligible, but while Kinyarwanda has been studied in Natural Language Processing (NLP) to some extent, this work constitutes the first study on Kirundi. Along with the datasets, we provide statistics, guidelines for preprocessing, and monolingual and cross-lingual baseline models. Our experiments show that training embeddings on the relatively higher-resourced Kinyarwanda yields successful cross-lingual transfer to Kirundi. In addition, the design of the created datasets allows for a wider use in NLP beyond text classification in future studies, such as representation learning, cross-lingual learning with more distant languages, or as base for new annotations for tasks such as parsing, POS tagging, and NER. The datasets, stopwords, and pre-trained embeddings are publicly available at https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus .
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020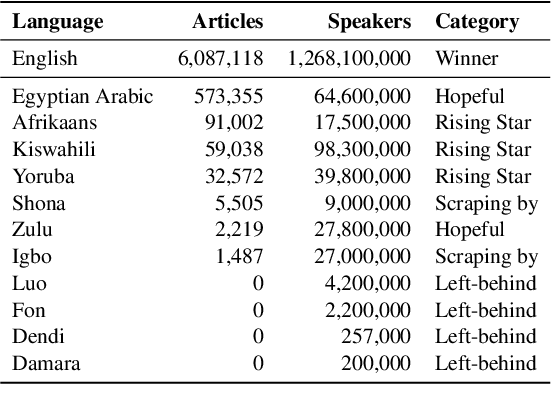
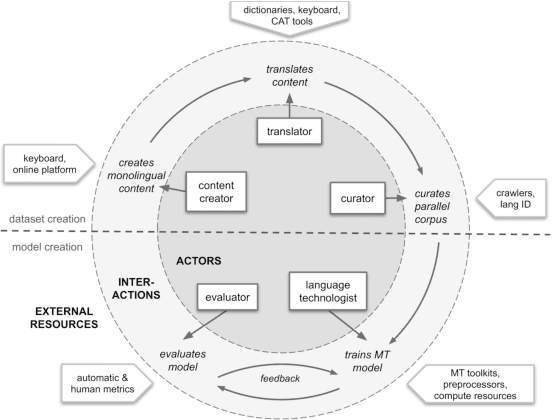
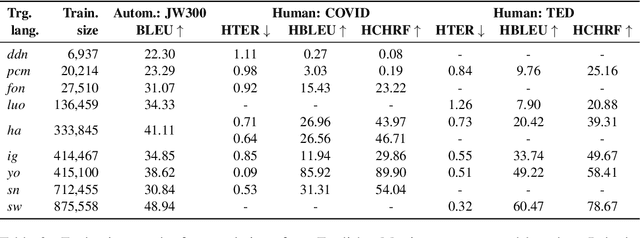
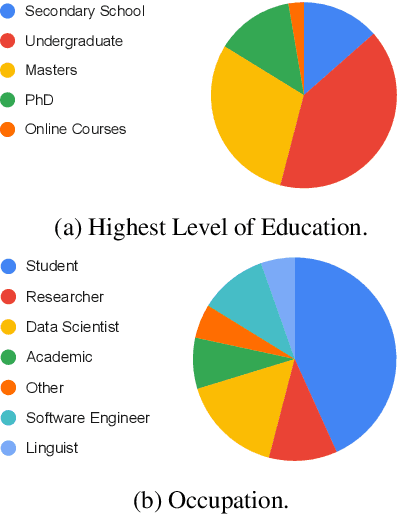
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.