 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-domain Multilingual Sentiment Analysis in Industry: Predicting Aspect-based Opinion Quadruples
May 15, 2025This paper explores the design of an aspect-based sentiment analysis system using large language models (LLMs) for real-world use. We focus on quadruple opinion extraction -- identifying aspect categories, sentiment polarity, targets, and opinion expressions from text data across different domains and languages. Using internal datasets, we investigate whether a single fine-tuned model can effectively handle multiple domain-specific taxonomies simultaneously. We demonstrate that a combined multi-domain model achieves performance comparable to specialized single-domain models while reducing operational complexity. We also share lessons learned for handling non-extractive predictions and evaluating various failure modes when developing LLM-based systems for structured prediction tasks.
A Systematic Review of Reproducibility Research in Natural Language Processing
Mar 21, 2021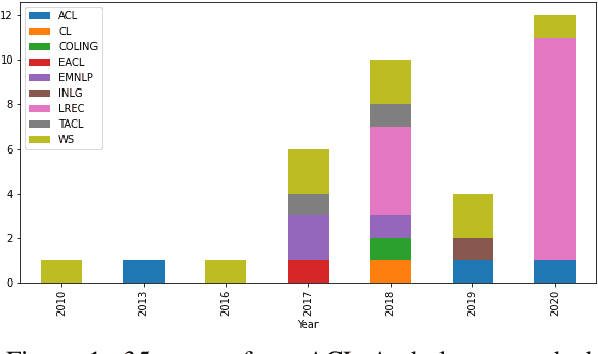
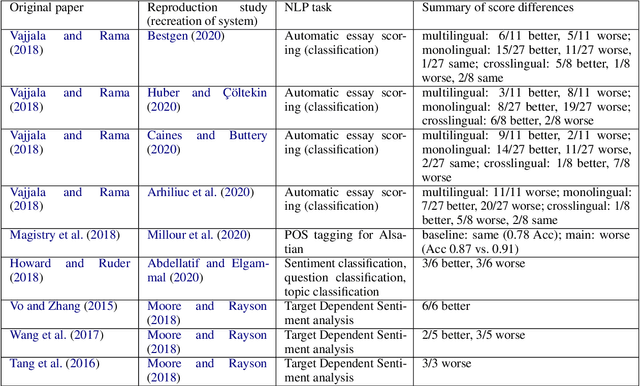
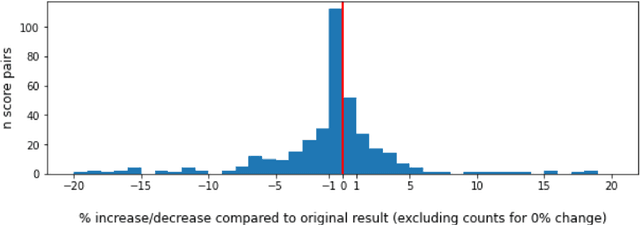
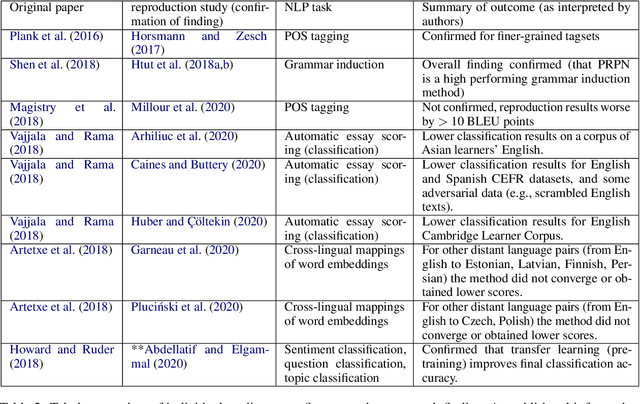
Against the background of what has been termed a reproducibility crisis in science, the NLP field is becoming increasingly interested in, and conscientious about, the reproducibility of its results. The past few years have seen an impressive range of new initiatives, events and active research in the area. However, the field is far from reaching a consensus about how reproducibility should be defined, measured and addressed, with diversity of views currently increasing rather than converging. With this focused contribution, we aim to provide a wide-angle, and as near as possible complete, snapshot of current work on reproducibility in NLP, delineating differences and similarities, and providing pointers to common denominators.
The Human Evaluation Datasheet 1.0: A Template for Recording Details of Human Evaluation Experiments in NLP
Mar 17, 2021This paper introduces the Human Evaluation Datasheet, a template for recording the details of individual human evaluation experiments in Natural Language Processing (NLP). Originally taking inspiration from seminal papers by Bender and Friedman (2018), Mitchell et al. (2019), and Gebru et al. (2020), the Human Evaluation Datasheet is intended to facilitate the recording of properties of human evaluations in sufficient detail, and with sufficient standardisation, to support comparability, meta-evaluation, and reproducibility tests.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Human vs Automatic Metrics: on the Importance of Correlation Design
May 30, 2018
This paper discusses two existing approaches to the correlation analysis between automatic evaluation metrics and human scores in the area of natural language generation. Our experiments show that depending on the usage of a system- or sentence-level correlation analysis, correlation results between automatic scores and human judgments are inconsistent.
Split and Rephrase
Jul 21, 2017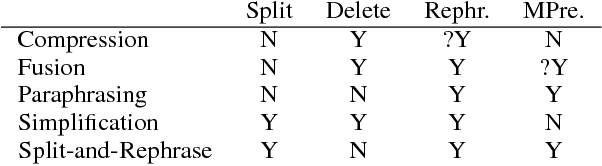


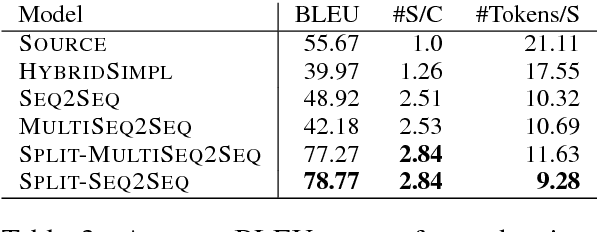
We propose a new sentence simplification task (Split-and-Rephrase) where the aim is to split a complex sentence into a meaning preserving sequence of shorter sentences. Like sentence simplification, splitting-and-rephrasing has the potential of benefiting both natural language processing and societal applications. Because shorter sentences are generally better processed by NLP systems, it could be used as a preprocessing step which facilitates and improves the performance of parsers, semantic role labellers and machine translation systems. It should also be of use for people with reading disabilities because it allows the conversion of longer sentences into shorter ones. This paper makes two contributions towards this new task. First, we create and make available a benchmark consisting of 1,066,115 tuples mapping a single complex sentence to a sequence of sentences expressing the same meaning. Second, we propose five models (vanilla sequence-to-sequence to semantically-motivated models) to understand the difficulty of the proposed task.