 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIREBALL: A Dataset of Dungeons and Dragons Actual-Play with Structured Game State Information
May 08, 2023Dungeons & Dragons (D&D) is a tabletop roleplaying game with complex natural language interactions between players and hidden state information. Recent work has shown that large language models (LLMs) that have access to state information can generate higher quality game turns than LLMs that use dialog history alone. However, previous work used game state information that was heuristically created and was not a true gold standard game state. We present FIREBALL, a large dataset containing nearly 25,000 unique sessions from real D&D gameplay on Discord with true game state info. We recorded game play sessions of players who used the Avrae bot, which was developed to aid people in playing D&D online, capturing language, game commands and underlying game state information. We demonstrate that FIREBALL can improve natural language generation (NLG) by using Avrae state information, improving both automated metrics and human judgments of quality. Additionally, we show that LLMs can generate executable Avrae commands, particularly after finetuning.
Does Putting a Linguist in the Loop Improve NLU Data Collection?
Apr 15, 2021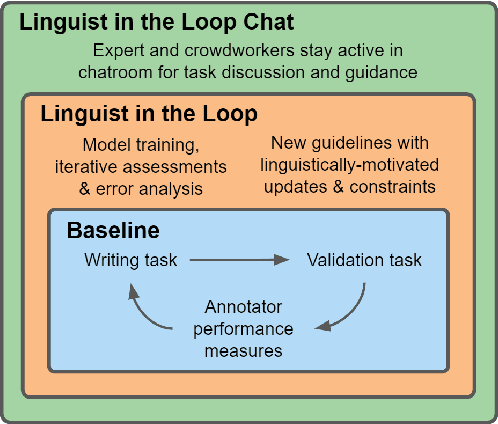
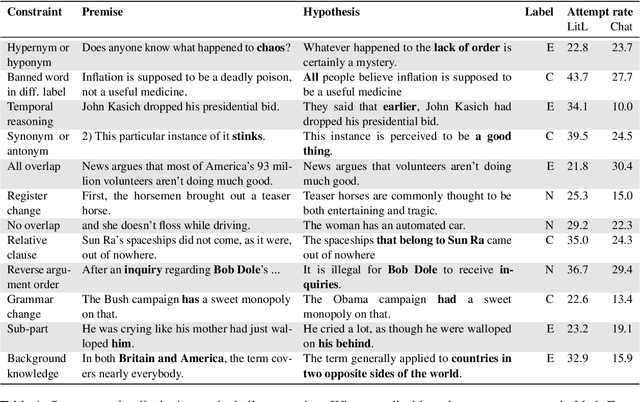

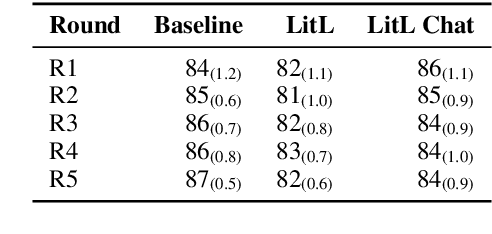
Many crowdsourced NLP datasets contain systematic gaps and biases that are identified only after data collection is complete. Identifying these issues from early data samples during crowdsourcing should make mitigation more efficient, especially when done iteratively. We take natural language inference as a test case and ask whether it is beneficial to put a linguist `in the loop' during data collection to dynamically identify and address gaps in the data by introducing novel constraints on the task. We directly compare three data collection protocols: (i) a baseline protocol, (ii) a linguist-in-the-loop intervention with iteratively-updated constraints on the task, and (iii) an extension of linguist-in-the-loop that provides direct interaction between linguists and crowdworkers via a chatroom. The datasets collected with linguist involvement are more reliably challenging than baseline, without loss of quality. But we see no evidence that using this data in training leads to better out-of-domain model performance, and the addition of a chat platform has no measurable effect on the resulting dataset. We suggest integrating expert analysis \textit{during} data collection so that the expert can dynamically address gaps and biases in the dataset.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.