 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Making Scalable Meta Learning Practical
Oct 23, 2023



Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
Regularizing Self-training for Unsupervised Domain Adaptation via Structural Constraints
Apr 29, 2023



Self-training based on pseudo-labels has emerged as a dominant approach for addressing conditional distribution shifts in unsupervised domain adaptation (UDA) for semantic segmentation problems. A notable drawback, however, is that this family of approaches is susceptible to erroneous pseudo labels that arise from confirmation biases in the source domain and that manifest as nuisance factors in the target domain. A possible source for this mismatch is the reliance on only photometric cues provided by RGB image inputs, which may ultimately lead to sub-optimal adaptation. To mitigate the effect of mismatched pseudo-labels, we propose to incorporate structural cues from auxiliary modalities, such as depth, to regularise conventional self-training objectives. Specifically, we introduce a contrastive pixel-level objectness constraint that pulls the pixel representations within a region of an object instance closer, while pushing those from different object categories apart. To obtain object regions consistent with the true underlying object, we extract information from both depth maps and RGB-images in the form of multimodal clustering. Crucially, the objectness constraint is agnostic to the ground-truth semantic labels and, hence, appropriate for unsupervised domain adaptation. In this work, we show that our regularizer significantly improves top performing self-training methods (by up to $2$ points) in various UDA benchmarks for semantic segmentation. We include all code in the supplementary.
DSI++: Updating Transformer Memory with New Documents
Dec 19, 2022



Differentiable Search Indices (DSIs) encode a corpus of documents in the parameters of a model and use the same model to map queries directly to relevant document identifiers. Despite the strong performance of DSI models, deploying them in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model. In this work, we introduce DSI++, a continual learning challenge for DSI to incrementally index new documents while being able to answer queries related to both previously and newly indexed documents. Across different model scales and document identifier representations, we show that continual indexing of new documents leads to considerable forgetting of previously indexed documents. We also hypothesize and verify that the model experiences forgetting events during training, leading to unstable learning. To mitigate these issues, we investigate two approaches. The first focuses on modifying the training dynamics. Flatter minima implicitly alleviate forgetting, so we optimize for flatter loss basins and show that the model stably memorizes more documents (+12\%). Next, we introduce a generative memory to sample pseudo-queries for documents and supplement them during continual indexing to prevent forgetting for the retrieval task. Extensive experiments on novel continual indexing benchmarks based on Natural Questions (NQ) and MS MARCO demonstrate that our proposed solution mitigates forgetting by a significant margin. Concretely, it improves the average Hits@10 by $+21.1\%$ over competitive baselines for NQ and requires $6$ times fewer model updates compared to re-training the DSI model for incrementally indexing five corpora in a sequence.
An Introduction to Lifelong Supervised Learning
Jul 12, 2022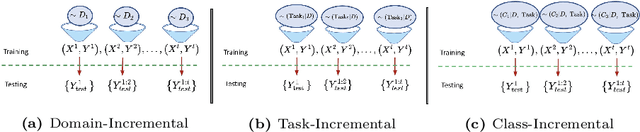
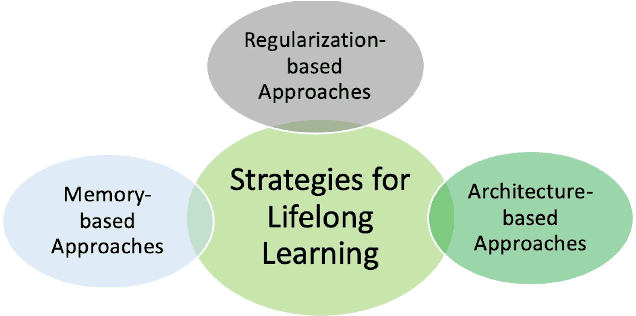
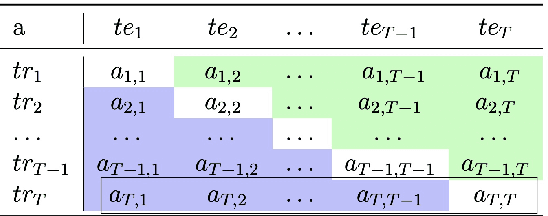
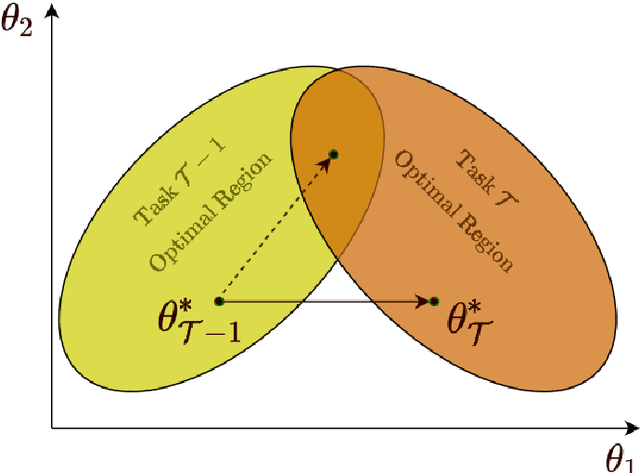
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
Train Flat, Then Compress: Sharpness-Aware Minimization Learns More Compressible Models
May 25, 2022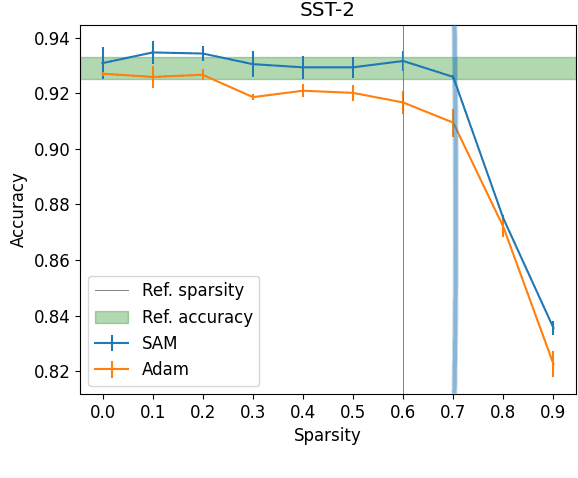
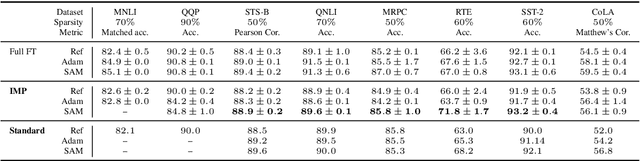
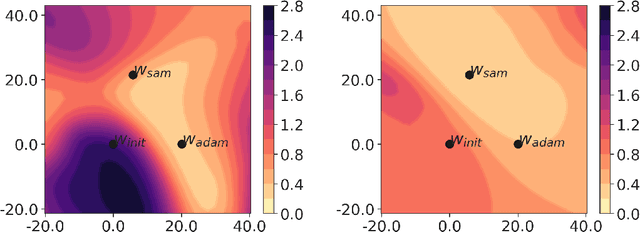
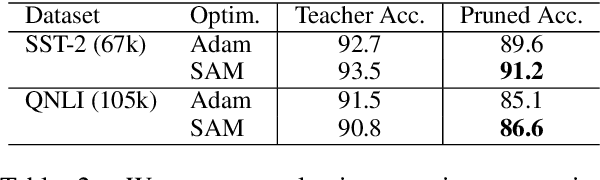
Model compression by way of parameter pruning, quantization, or distillation has recently gained popularity as an approach for reducing the computational requirements of modern deep neural network models for NLP. Pruning unnecessary parameters has emerged as a simple and effective method for compressing large models that is compatible with a wide variety of contemporary off-the-shelf hardware (unlike quantization), and that requires little additional training (unlike distillation). Pruning approaches typically take a large, accurate model as input, then attempt to discover a smaller subnetwork of that model capable of achieving end-task accuracy comparable to the full model. Inspired by previous work suggesting a connection between simpler, more generalizable models and those that lie within flat basins in the loss landscape, we propose to directly optimize for flat minima while performing task-specific pruning, which we hypothesize should lead to simpler parameterizations and thus more compressible models. In experiments combining sharpness-aware minimization with both iterative magnitude pruning and structured pruning approaches, we show that optimizing for flat minima consistently leads to greater compressibility of parameters compared to standard Adam optimization when fine-tuning BERT models, leading to higher rates of compression with little to no loss in accuracy on the GLUE classification benchmark.
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
Dec 16, 2021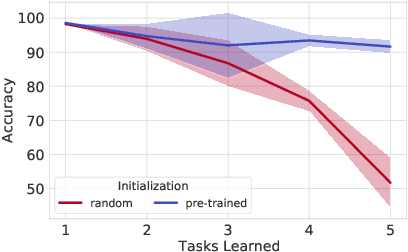
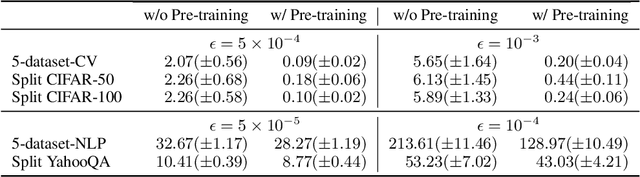
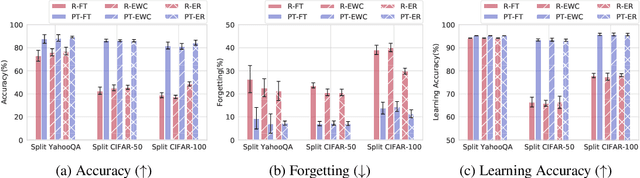
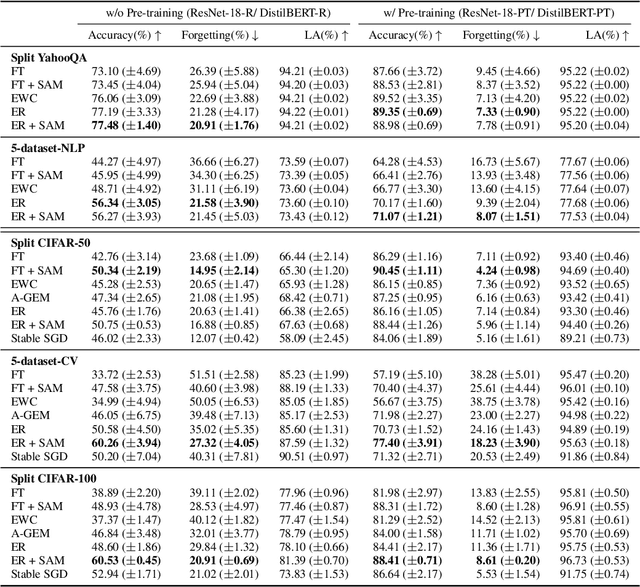
The lifelong learning paradigm in machine learning is an attractive alternative to the more prominent isolated learning scheme not only due to its resemblance to biological learning, but also its potential to reduce energy waste by obviating excessive model re-training. A key challenge to this paradigm is the phenomenon of catastrophic forgetting. With the increasing popularity and success of pre-trained models in machine learning, we pose the question: What role does pre-training play in lifelong learning, specifically with respect to catastrophic forgetting? We investigate existing methods in the context of large, pre-trained models and evaluate their performance on a variety of text and image classification tasks, including a large-scale study using a novel dataset of 15 diverse NLP tasks. Across all settings, we observe that generic pre-training implicitly alleviates the effects of catastrophic forgetting when learning multiple tasks sequentially compared to randomly initialized models. We then further investigate why pre-training alleviates forgetting in this setting. We study this phenomenon by analyzing the loss landscape, finding that pre-trained weights appear to ease forgetting by leading to wider minima. Based on this insight, we propose jointly optimizing for current task loss and loss basin sharpness in order to explicitly encourage wider basins during sequential fine-tuning. We show that this optimization approach leads to performance comparable to the state-of-the-art in task-sequential continual learning across multiple settings, without retaining a memory that scales in size with the number of tasks.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021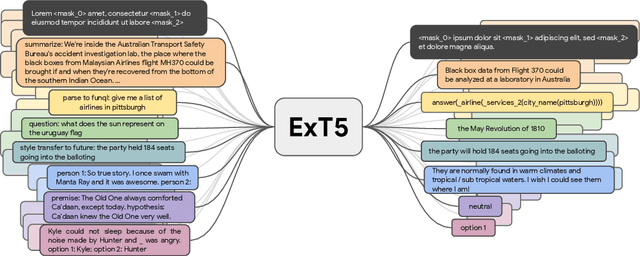
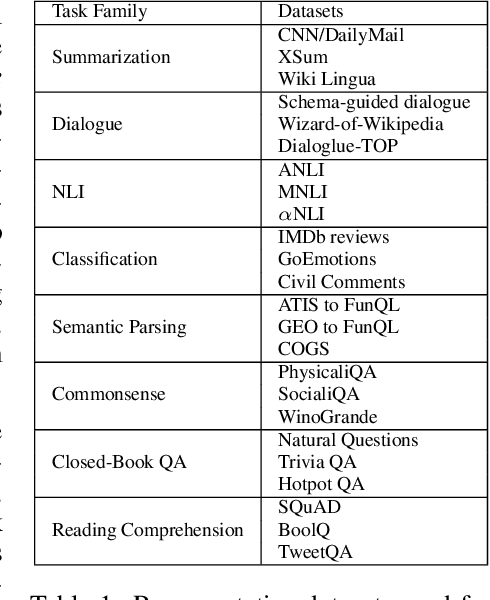
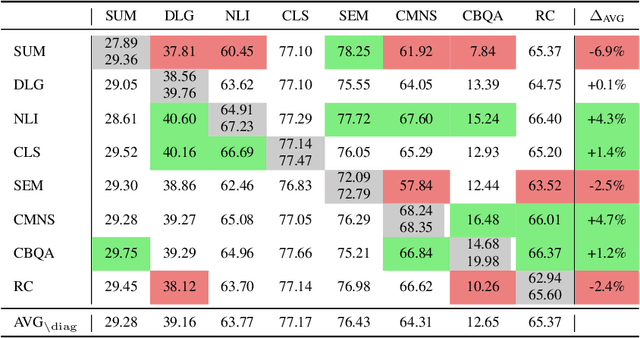
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
Improving Compositional Generalization with Self-Training for Data-to-Text Generation
Oct 16, 2021
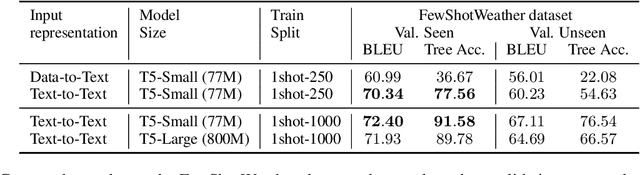


Data-to-text generation focuses on generating fluent natural language responses from structured semantic representations. Such representations are compositional, allowing for the combination of atomic meaning schemata in various ways to express the rich semantics in natural language. Recently, pretrained language models (LMs) have achieved impressive results on data-to-text tasks, though it remains unclear the extent to which these LMs generalize to new semantic representations. In this work, we systematically study the compositional generalization of current state-of-the-art generation models in data-to-text tasks. By simulating structural shifts in the compositional Weather dataset, we show that T5 models fail to generalize to unseen structures. Next, we show that template-based input representations greatly improve the model performance and model scale does not trivially solve the lack of generalization. To further improve the model's performance, we propose an approach based on self-training using finetuned BLEURT for pseudo-response selection. Extensive experiments on the few-shot Weather and multi-domain SGD datasets demonstrate strong gains of our method.
Efficient Meta Lifelong-Learning with Limited Memory
Oct 06, 2020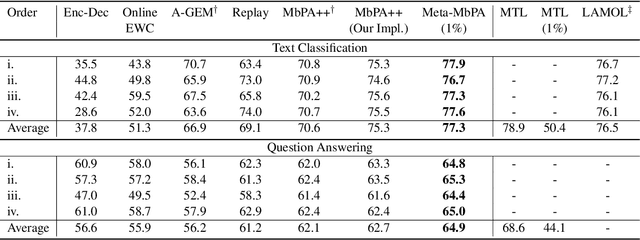
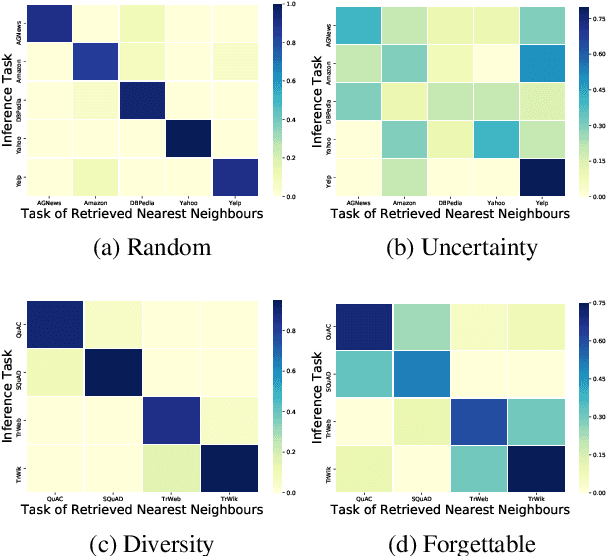
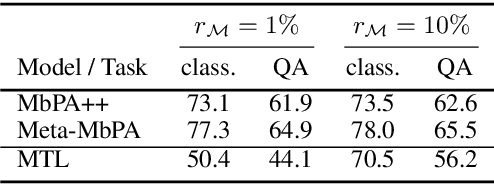
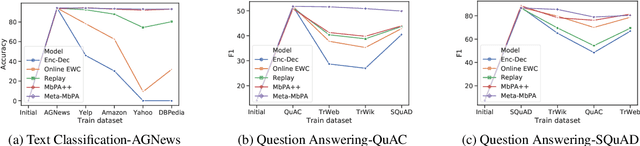
Current natural language processing models work well on a single task, yet they often fail to continuously learn new tasks without forgetting previous ones as they are re-trained throughout their lifetime, a challenge known as lifelong learning. State-of-the-art lifelong language learning methods store past examples in episodic memory and replay them at both training and inference time. However, as we show later in our experiments, there are three significant impediments: (1) needing unrealistically large memory module to achieve good performance, (2) suffering from negative transfer, (3) requiring multiple local adaptation steps for each test example that significantly slows down the inference speed. In this paper, we identify three common principles of lifelong learning methods and propose an efficient meta-lifelong framework that combines them in a synergistic fashion. To achieve sample efficiency, our method trains the model in a manner that it learns a better initialization for local adaptation. Extensive experiments on text classification and question answering benchmarks demonstrate the effectiveness of our framework by achieving state-of-the-art performance using merely 1% memory size and narrowing the gap with multi-task learning. We further show that our method alleviates both catastrophic forgetting and negative transfer at the same time.