 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTELLAR: Scaling 3D Perception Large Models for Autonomous Driving
May 19, 2026Model scaling has demonstrated remarkable success through large-scale training on diverse datasets. It remains an open question whether the same paradigm would apply to autonomous driving perception systems due to unique challenges, such as fusing heterogeneous sensor data and the need for sophisticated 3D spatial understanding. To bridge this gap, we present a comprehensive study on systematically analyzing the impact of scale on these systems. We develop our STELLAR model based on Sparse Window Transformer, by extending the input modalities to include LiDAR, radar, camera, and map prior. We train the model on a large-scale dataset of 50 million driving examples with up to 500 million parameters. Our large-scale experiments reveal empirical scaling trends that connect model performance to model size, data, and compute. The resulting model establishes a new state-of-the-art on the Waymo Open Dataset challenge, outperforming prior arts by a large margin. Our work demonstrates that large-scale training is a highly promising path for advancing the capabilities of perception models for autonomous driving.
SPINE: SParse Interpretable Neural Embeddings
Nov 23, 2017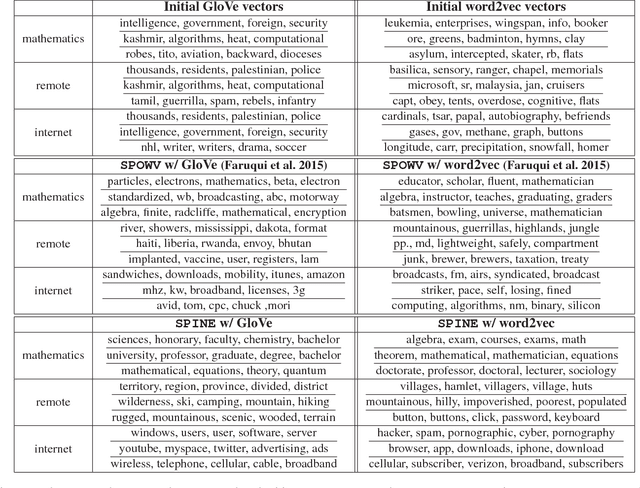
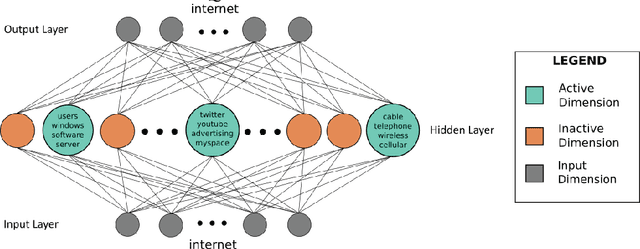


Prediction without justification has limited utility. Much of the success of neural models can be attributed to their ability to learn rich, dense and expressive representations. While these representations capture the underlying complexity and latent trends in the data, they are far from being interpretable. We propose a novel variant of denoising k-sparse autoencoders that generates highly efficient and interpretable distributed word representations (word embeddings), beginning with existing word representations from state-of-the-art methods like GloVe and word2vec. Through large scale human evaluation, we report that our resulting word embedddings are much more interpretable than the original GloVe and word2vec embeddings. Moreover, our embeddings outperform existing popular word embeddings on a diverse suite of benchmark downstream tasks.