 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Labeling Enables Faster Vision-Language Models for End-to-End Autonomous Driving
Jun 05, 2025Vision-Language Models (VLMs) offer a promising approach to end-to-end autonomous driving due to their human-like reasoning capabilities. However, troublesome gaps remains between current VLMs and real-world autonomous driving applications. One major limitation is that existing datasets with loosely formatted language descriptions are not machine-friendly and may introduce redundancy. Additionally, high computational cost and massive scale of VLMs hinder the inference speed and real-world deployment. To bridge the gap, this paper introduces a structured and concise benchmark dataset, NuScenes-S, which is derived from the NuScenes dataset and contains machine-friendly structured representations. Moreover, we present FastDrive, a compact VLM baseline with 0.9B parameters. In contrast to existing VLMs with over 7B parameters and unstructured language processing(e.g., LLaVA-1.5), FastDrive understands structured and concise descriptions and generates machine-friendly driving decisions with high efficiency. Extensive experiments show that FastDrive achieves competitive performance on structured dataset, with approximately 20% accuracy improvement on decision-making tasks, while surpassing massive parameter baseline in inference speed with over 10x speedup. Additionally, ablation studies further focus on the impact of scene annotations (e.g., weather, time of day) on decision-making tasks, demonstrating their importance on decision-making tasks in autonomous driving.
STDR: Spatio-Temporal Decoupling for Real-Time Dynamic Scene Rendering
May 28, 2025Although dynamic scene reconstruction has long been a fundamental challenge in 3D vision, the recent emergence of 3D Gaussian Splatting (3DGS) offers a promising direction by enabling high-quality, real-time rendering through explicit Gaussian primitives. However, existing 3DGS-based methods for dynamic reconstruction often suffer from \textit{spatio-temporal incoherence} during initialization, where canonical Gaussians are constructed by aggregating observations from multiple frames without temporal distinction. This results in spatio-temporally entangled representations, making it difficult to model dynamic motion accurately. To overcome this limitation, we propose \textbf{STDR} (Spatio-Temporal Decoupling for Real-time rendering), a plug-and-play module that learns spatio-temporal probability distributions for each Gaussian. STDR introduces a spatio-temporal mask, a separated deformation field, and a consistency regularization to jointly disentangle spatial and temporal patterns. Extensive experiments demonstrate that incorporating our module into existing 3DGS-based dynamic scene reconstruction frameworks leads to notable improvements in both reconstruction quality and spatio-temporal consistency across synthetic and real-world benchmarks.
CiUAV: A Multi-Task 3D Indoor Localization System for UAVs based on Channel State Information
May 27, 2025



Accurate indoor positioning for unmanned aerial vehicles (UAVs) is critical for logistics, surveillance, and emergency response applications, particularly in GPS-denied environments. Existing indoor localization methods, including optical tracking, ultra-wideband, and Bluetooth-based systems, face cost, accuracy, and robustness trade-offs, limiting their practicality for UAV navigation. This paper proposes CiUAV, a novel 3D indoor localization system designed for UAVs, leveraging channel state information (CSI) obtained from low-cost ESP32 IoT-based sensors. The system incorporates a dynamic automatic gain control (AGC) compensation algorithm to mitigate noise and stabilize CSI signals, significantly enhancing the robustness of the measurement. Additionally, a multi-task 3D localization model, Sensor-in-Sample (SiS), is introduced to enhance system robustness by addressing challenges related to incomplete sensor data and limited training samples. SiS achieves this by joint training with varying sensor configurations and sample sizes, ensuring reliable performance even in resource-constrained scenarios. Experiment results demonstrate that CiUAV achieves a LMSE localization error of 0.2629 m in a 3D space, achieving good accuracy and robustness. The proposed system provides a cost-effective and scalable solution, demonstrating its usefulness for UAV applications in resource-constrained indoor environments.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
ProFashion: Prototype-guided Fashion Video Generation with Multiple Reference Images
May 10, 2025



Fashion video generation aims to synthesize temporally consistent videos from reference images of a designated character. Despite significant progress, existing diffusion-based methods only support a single reference image as input, severely limiting their capability to generate view-consistent fashion videos, especially when there are different patterns on the clothes from different perspectives. Moreover, the widely adopted motion module does not sufficiently model human body movement, leading to sub-optimal spatiotemporal consistency. To address these issues, we propose ProFashion, a fashion video generation framework leveraging multiple reference images to achieve improved view consistency and temporal coherency. To effectively leverage features from multiple reference images while maintaining a reasonable computational cost, we devise a Pose-aware Prototype Aggregator, which selects and aggregates global and fine-grained reference features according to pose information to form frame-wise prototypes, which serve as guidance in the denoising process. To further enhance motion consistency, we introduce a Flow-enhanced Prototype Instantiator, which exploits the human keypoint motion flow to guide an extra spatiotemporal attention process in the denoiser. To demonstrate the effectiveness of ProFashion, we extensively evaluate our method on the MRFashion-7K dataset we collected from the Internet. ProFashion also outperforms previous methods on the UBC Fashion dataset.
Fast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Pinching-Antenna System (PASS) Enhanced Covert Communications
Apr 14, 2025



A Pinching-Antenna SyStem (PASS)-assisted convert communication framework is proposed. PASS utilizes dielectric waveguides with freely positioned pinching antennas (PAs) to establish strong line-of-sight links. Capitalizing on this high reconfigurable flexibility of antennas, the potential of PASS for covert communications is investigated. 1)~For the single-waveguide single-PA (SWSP) scenario, a closed-form optimal PA position that maximizes the covert rate is first derived. Subsequently, a one-dimensional power search is employed to enable low-complexity optimization for covert communications. With antenna mobility on a scale of meters, PASS can deal with the challenging situation of the eavesdropper enjoying better channel conditions than the legal user. 2)~For the multi-waveguide multi-PA (MWMP) scenario, the positions of multiple PAs are optimized to enable effective pinching beamforming, thereby enhancing the covert rate. To address the resultant multimodal joint transmit and pinching beamforming problem, a twin particle swarm optimization (TwinPSO) approach is proposed. Numerical results demonstrate that: i)~the proposed approaches can effectively resolve the optimization problems; ii)~PASS achieves a higher covert rate than conventional fixed-position antenna architectures; and iii)~with enhanced flexibility, the MWMP setup outperforms the SWSP counterpart.
Boosting MLLM Reasoning with Text-Debiased Hint-GRPO
Mar 31, 2025MLLM reasoning has drawn widespread research for its excellent problem-solving capability. Current reasoning methods fall into two types: PRM, which supervises the intermediate reasoning steps, and ORM, which supervises the final results. Recently, DeepSeek-R1 has challenged the traditional view that PRM outperforms ORM, which demonstrates strong generalization performance using an ORM method (i.e., GRPO). However, current MLLM's GRPO algorithms still struggle to handle challenging and complex multimodal reasoning tasks (e.g., mathematical reasoning). In this work, we reveal two problems that impede the performance of GRPO on the MLLM: Low data utilization and Text-bias. Low data utilization refers to that GRPO cannot acquire positive rewards to update the MLLM on difficult samples, and text-bias is a phenomenon that the MLLM bypasses image condition and solely relies on text condition for generation after GRPO training. To tackle these problems, this work proposes Hint-GRPO that improves data utilization by adaptively providing hints for samples of varying difficulty, and text-bias calibration that mitigates text-bias by calibrating the token prediction logits with image condition in test-time. Experiment results on three base MLLMs across eleven datasets demonstrate that our proposed methods advance the reasoning capability of original MLLM by a large margin, exhibiting superior performance to existing MLLM reasoning methods. Our code is available at https://github.com/hqhQAQ/Hint-GRPO.
SED-MVS: Segmentation-Driven and Edge-Aligned Deformation Multi-View Stereo with Depth Restoration and Occlusion Constraint
Mar 17, 2025
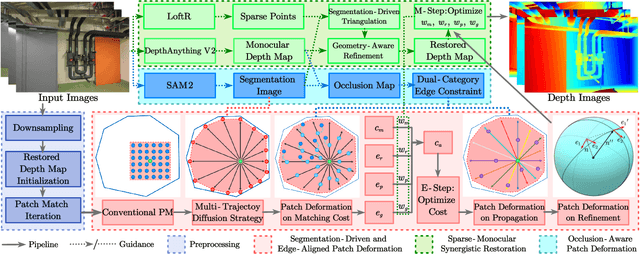


Recently, patch-deformation methods have exhibited significant effectiveness in multi-view stereo owing to the deformable and expandable patches in reconstructing textureless areas. However, such methods primarily emphasize broadening the receptive field in textureless areas, while neglecting deformation instability caused by easily overlooked edge-skipping, potentially leading to matching distortions. To address this, we propose SED-MVS, which adopts panoptic segmentation and multi-trajectory diffusion strategy for segmentation-driven and edge-aligned patch deformation. Specifically, to prevent unanticipated edge-skipping, we first employ SAM2 for panoptic segmentation as depth-edge guidance to guide patch deformation, followed by multi-trajectory diffusion strategy to ensure patches are comprehensively aligned with depth edges. Moreover, to avoid potential inaccuracy of random initialization, we combine both sparse points from LoFTR and monocular depth map from DepthAnything V2 to restore reliable and realistic depth map for initialization and supervised guidance. Finally, we integrate segmentation image with monocular depth map to exploit inter-instance occlusion relationship, then further regard them as occlusion map to implement two distinct edge constraint, thereby facilitating occlusion-aware patch deformation. Extensive results on ETH3D, Tanks & Temples, BlendedMVS and Strecha datasets validate the state-of-the-art performance and robust generalization capability of our proposed method.