 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional visualization of X-ray micro-CT with large-scale datasets: Efficiency and accuracy for real-time interaction
Jan 21, 2026As Micro-CT technology continues to refine its characterization of material microstructures, industrial CT ultra-precision inspection is generating increasingly large datasets, necessitating solutions to the trade-off between accuracy and efficiency in the 3D characterization of defects during ultra-precise detection. This article provides a unique perspective on recent advances in accurate and efficient 3D visualization using Micro-CT, tracing its evolution from medical imaging to industrial non-destructive testing (NDT). Among the numerous CT reconstruction and volume rendering methods, this article selectively reviews and analyzes approaches that balance accuracy and efficiency, offering a comprehensive analysis to help researchers quickly grasp highly efficient and accurate 3D reconstruction methods for microscopic features. By comparing the principles of computed tomography with advancements in microstructural technology, this article examines the evolution of CT reconstruction algorithms from analytical methods to deep learning techniques, as well as improvements in volume rendering algorithms, acceleration, and data reduction. Additionally, it explores advanced lighting models for high-accuracy, photorealistic, and efficient volume rendering. Furthermore, this article envisions potential directions in CT reconstruction and volume rendering. It aims to guide future research in quickly selecting efficient and precise methods and developing new ideas and approaches for real-time online monitoring of internal material defects through virtual-physical interaction, for applying digital twin model to structural health monitoring (SHM).
TEA: Temporal Adaptive Satellite Image Semantic Segmentation
Jan 08, 2026Crop mapping based on satellite images time-series (SITS) holds substantial economic value in agricultural production settings, in which parcel segmentation is an essential step. Existing approaches have achieved notable advancements in SITS segmentation with predetermined sequence lengths. However, we found that these approaches overlooked the generalization capability of models across scenarios with varying temporal length, leading to markedly poor segmentation results in such cases. To address this issue, we propose TEA, a TEmporal Adaptive SITS semantic segmentation method to enhance the model's resilience under varying sequence lengths. We introduce a teacher model that encapsulates the global sequence knowledge to guide a student model with adaptive temporal input lengths. Specifically, teacher shapes the student's feature space via intermediate embedding, prototypes and soft label perspectives to realize knowledge transfer, while dynamically aggregating student model to mitigate knowledge forgetting. Finally, we introduce full-sequence reconstruction as an auxiliary task to further enhance the quality of representations across inputs of varying temporal lengths. Through extensive experiments, we demonstrate that our method brings remarkable improvements across inputs of different temporal lengths on common benchmarks. Our code will be publicly available.
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025



Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
Jun 11, 2025Reconstructing dynamic 3D scenes from monocular videos remains a fundamental challenge in 3D vision. While 3D Gaussian Splatting (3DGS) achieves real-time rendering in static settings, extending it to dynamic scenes is challenging due to the difficulty of learning structured and temporally consistent motion representations. This challenge often manifests as three limitations in existing methods: redundant Gaussian updates, insufficient motion supervision, and weak modeling of complex non-rigid deformations. These issues collectively hinder coherent and efficient dynamic reconstruction. To address these limitations, we propose HAIF-GS, a unified framework that enables structured and consistent dynamic modeling through sparse anchor-driven deformation. It first identifies motion-relevant regions via an Anchor Filter to suppresses redundant updates in static areas. A self-supervised Induced Flow-Guided Deformation module induces anchor motion using multi-frame feature aggregation, eliminating the need for explicit flow labels. To further handle fine-grained deformations, a Hierarchical Anchor Propagation mechanism increases anchor resolution based on motion complexity and propagates multi-level transformations. Extensive experiments on synthetic and real-world benchmarks validate that HAIF-GS significantly outperforms prior dynamic 3DGS methods in rendering quality, temporal coherence, and reconstruction efficiency.
STDR: Spatio-Temporal Decoupling for Real-Time Dynamic Scene Rendering
May 28, 2025Although dynamic scene reconstruction has long been a fundamental challenge in 3D vision, the recent emergence of 3D Gaussian Splatting (3DGS) offers a promising direction by enabling high-quality, real-time rendering through explicit Gaussian primitives. However, existing 3DGS-based methods for dynamic reconstruction often suffer from \textit{spatio-temporal incoherence} during initialization, where canonical Gaussians are constructed by aggregating observations from multiple frames without temporal distinction. This results in spatio-temporally entangled representations, making it difficult to model dynamic motion accurately. To overcome this limitation, we propose \textbf{STDR} (Spatio-Temporal Decoupling for Real-time rendering), a plug-and-play module that learns spatio-temporal probability distributions for each Gaussian. STDR introduces a spatio-temporal mask, a separated deformation field, and a consistency regularization to jointly disentangle spatial and temporal patterns. Extensive experiments demonstrate that incorporating our module into existing 3DGS-based dynamic scene reconstruction frameworks leads to notable improvements in both reconstruction quality and spatio-temporal consistency across synthetic and real-world benchmarks.
Mlinear: Rethink the Linear Model for Time-series Forecasting
May 08, 2023Recently, significant advancements have been made in time-series forecasting research, with an increasing focus on analyzing the inherent characteristics of time-series data, rather than solely focusing on designing forecasting models.In this paper, we follow this trend and carefully examine previous work to propose an efficient time series forecasting model based on linear models. The model consists of two important core components: (1) the integration of different semantics brought by single-channel and multi-channel data for joint forecasting; (2) the use of a novel loss function that replaces the traditional MSE loss and MAE loss to achieve higher forecasting accuracy.On widely-used benchmark time series datasets, our model not only outperforms the current SOTA, but is also 10 $\times$ speedup and has fewer parameters than the latest SOTA model.
Bringing A Robot Simulator to the SCAMP Vision System
May 21, 2021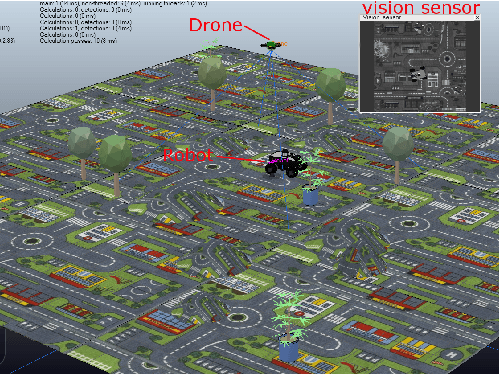
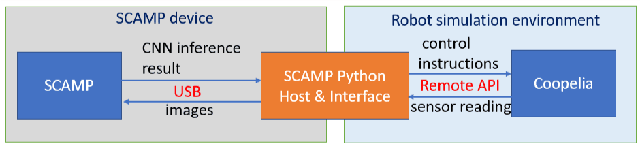

This work develops and demonstrates the integration of the SCAMP-5d vision system into the CoppeliaSim robot simulator, creating a semi-simulated environment. By configuring a camera in the simulator and setting up communication with the SCAMP python host through remote API, sensor images from the simulator can be transferred to the SCAMP vision sensor, where on-sensor image processing such as CNN inference can be performed. SCAMP output is then fed back into CoppeliaSim. This proposed platform integration enables rapid prototyping validations of SCAMP algorithms for robotic systems. We demonstrate a car localisation and tracking task using this proposed semi-simulated platform, with a CNN inference on SCAMP to command the motion of a robot. We made this platform available online.
Agile Reactive Navigation for A Non-Holonomic Mobile Robot Using A Pixel Processor Array
Sep 27, 2020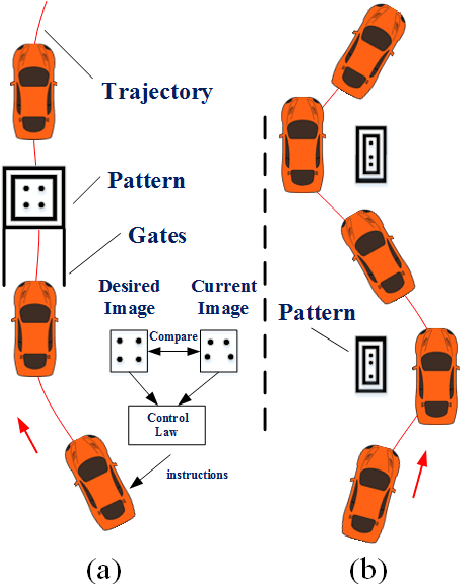

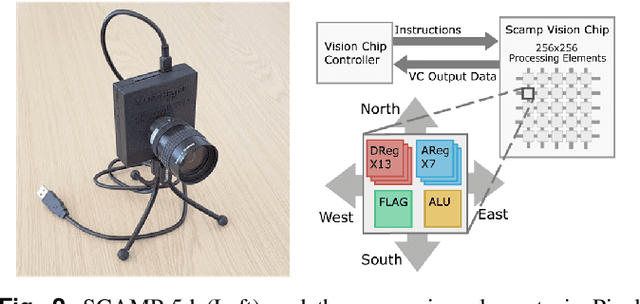
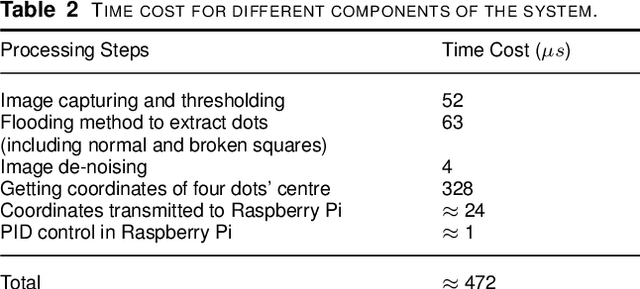
This paper presents an agile reactive navigation strategy for driving a non-holonomic ground vehicle around a preset course of gates in a cluttered environment using a low-cost processor array sensor. This enables machine vision tasks to be performed directly upon the sensor's image plane, rather than using a separate general-purpose computer. We demonstrate a small ground vehicle running through or avoiding multiple gates at high speed using minimal computational resources. To achieve this, target tracking algorithms are developed for the Pixel Processing Array and captured images are then processed directly on the vision sensor acquiring target information for controlling the ground vehicle. The algorithm can run at up to 2000 fps outdoors and 200fps at indoor illumination levels. Conducting image processing at the sensor level avoids the bottleneck of image transfer encountered in conventional sensors. The real-time performance of on-board image processing and robustness is validated through experiments. Experimental results demonstrate that the algorithm's ability to enable a ground vehicle to navigate at an average speed of 2.20 m/s for passing through multiple gates and 3.88 m/s for a 'slalom' task in an environment featuring significant visual clutter.
Fully Embedding Fast Convolutional Networks on Pixel Processor Arrays
Apr 27, 2020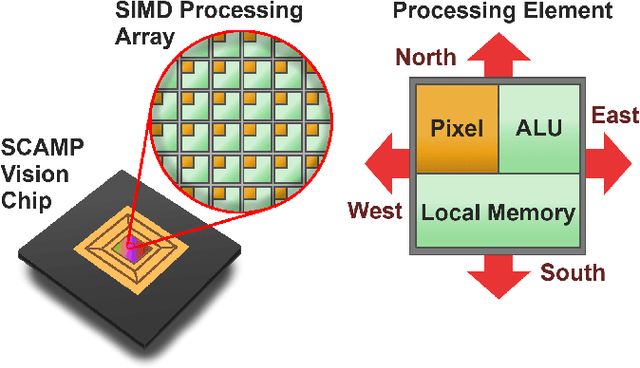
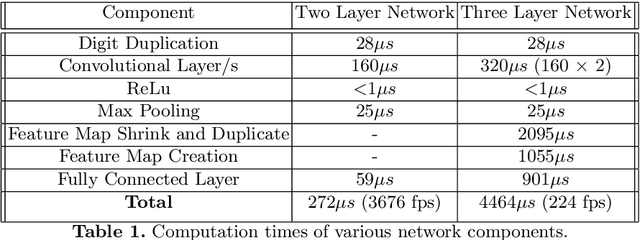
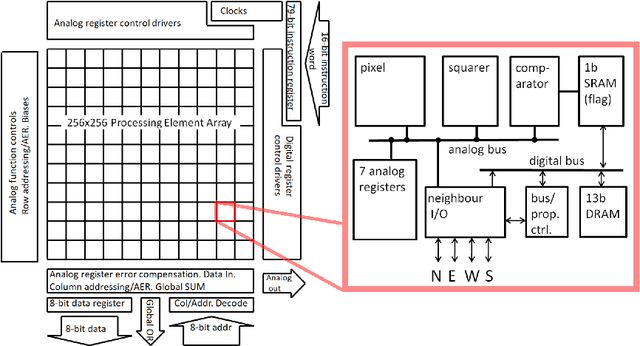
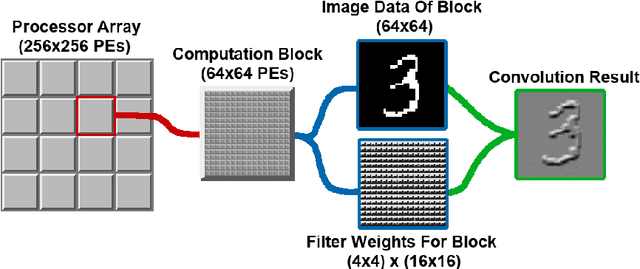
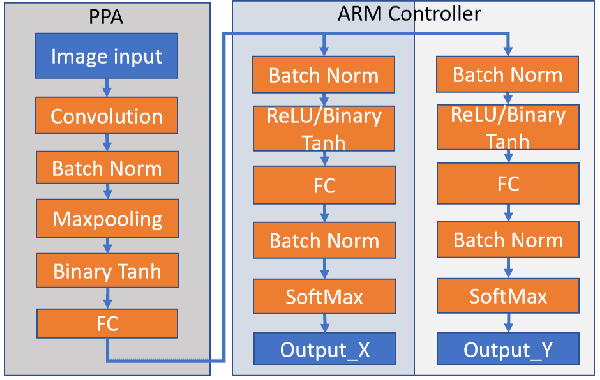
We present a novel method of CNN inference for pixel processor array (PPA) vision sensors, designed to take advantage of their massive parallelism and analog compute capabilities. PPA sensors consist of an array of processing elements (PEs), with each PE capable of light capture, data storage and computation, allowing various computer vision processing to be executed directly upon the sensor device. The key idea behind our approach is storing network weights "in-pixel" within the PEs of the PPA sensor itself to allow various computations, such as multiple different image convolutions, to be carried out in parallel. Our approach can perform convolutional layers, max pooling, ReLu, and a final fully connected layer entirely upon the PPA sensor, while leaving no untapped computational resources. This is in contrast to previous works that only use a sensor-level processing to sequentially compute image convolutions, and must transfer data to an external digital processor to complete the computation. We demonstrate our approach on the SCAMP-5 vision system, performing inference of a MNIST digit classification network at over 3000 frames per second and over 93% classification accuracy. This is the first work demonstrating CNN inference conducted entirely upon the processor array of a PPA vision sensor device, requiring no external processing.
A Camera That CNNs: Towards Embedded Neural Networks on Pixel Processor Arrays
Sep 13, 2019
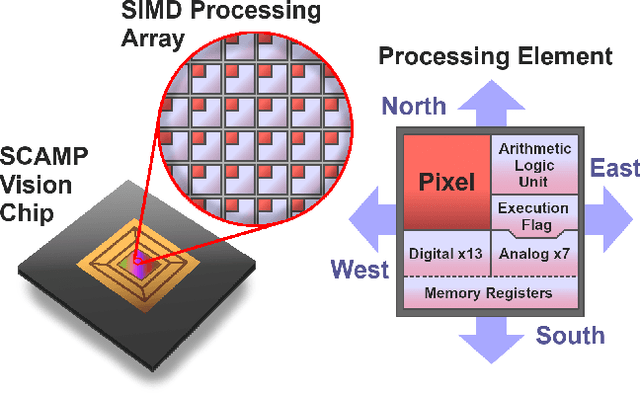
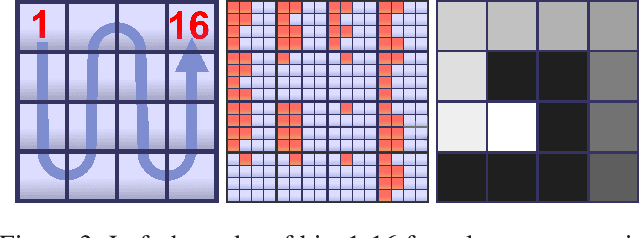

We present a convolutional neural network implementation for pixel processor array (PPA) sensors. PPA hardware consists of a fine-grained array of general-purpose processing elements, each capable of light capture, data storage, program execution, and communication with neighboring elements. This allows images to be stored and manipulated directly at the point of light capture, rather than having to transfer images to external processing hardware. Our CNN approach divides this array up into 4x4 blocks of processing elements, essentially trading-off image resolution for increased local memory capacity per 4x4 "pixel". We implement parallel operations for image addition, subtraction and bit-shifting images in this 4x4 block format. Using these components we formulate how to perform ternary weight convolutions upon these images, compactly store results of such convolutions, perform max-pooling, and transfer the resulting sub-sampled data to an attached micro-controller. We train ternary weight filter CNNs for digit recognition and a simple tracking task, and demonstrate inference of these networks upon the SCAMP5 PPA system. This work represents a first step towards embedding neural network processing capability directly onto the focal plane of a sensor.