 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniUncer: Unified Dynamic Static Uncertainty for End to End Driving
Mar 08, 2026End-to-end (E2E) driving has become a cornerstone of both industry deployment and academic research, offering a single learnable pipeline that maps multi-sensor inputs to actions while avoiding hand-engineered modules. However, the reliability of such pipelines strongly depends on how well they handle uncertainty: sensors are noisy, semantics can be ambiguous, and interaction with other road users is inherently stochastic. Uncertainty also appears in multiple forms: classification vs. localization, and, crucially, in both static map elements and dynamic agents. Existing E2E approaches model only static-map uncertainty, leaving planning vulnerable to overconfident and unreliable inputs. We present UniUncer, the first lightweight, unified uncertainty framework that jointly estimates and uses uncertainty for both static and dynamic scene elements inside an E2E planner. Concretely: (1) we convert deterministic heads to probabilistic Laplace regressors that output per-vertex location and scale for vectorized static and dynamic entities; (2) we introduce an uncertainty-fusion module that encodes these parameters and injects them into object/map queries to form uncertainty-aware queries; and (3) we design an uncertainty-aware gate that adaptively modulates reliance on historical inputs (ego status or temporal perception queries) based on current uncertainty levels. The design adds minimal overhead and drops throughput by only $\sim$0.5 FPS while remaining plug-and-play for common E2E backbones. On nuScenes (open-loop), UniUncer reduces average L2 trajectory error by 7\%. On NavsimV2 (pseudo closed-loop), it improves overall EPDMS by 10.8\% and notable stage two gains in challenging, interaction-heavy scenes. Ablations confirm that dynamic-agent uncertainty and the uncertainty-aware gate are both necessary.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
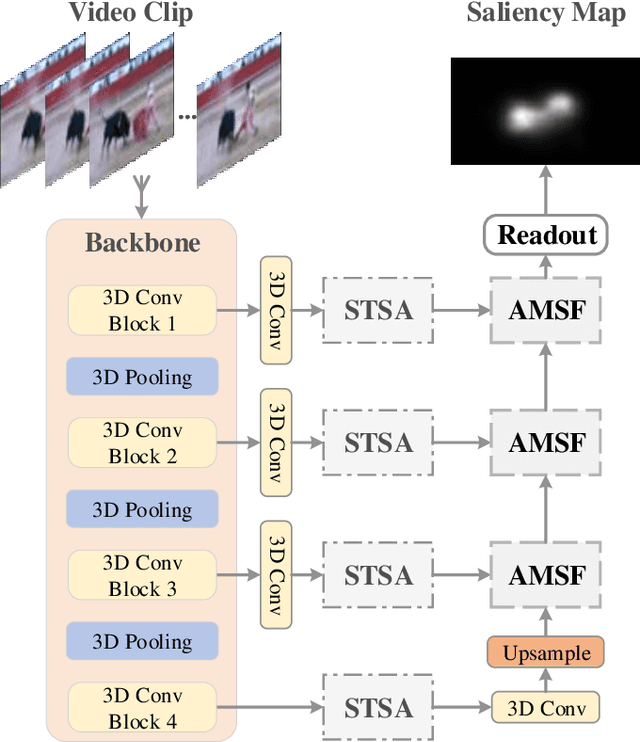
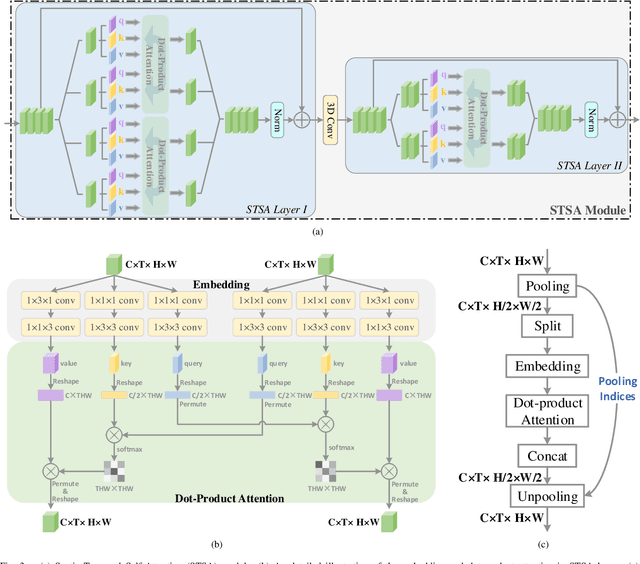
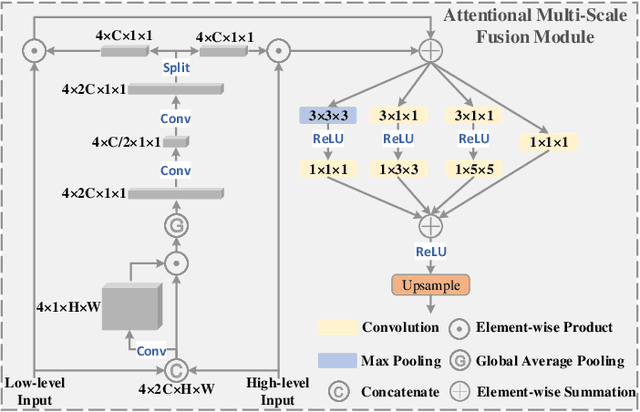
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
Individual Recognition in Schizophrenia using Deep Learning Methods with Random Forest and Voting Classifiers: Insights from Resting State EEG Streams
Jan 17, 2018
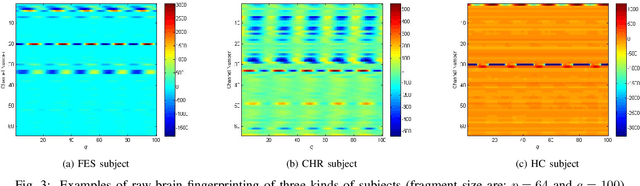
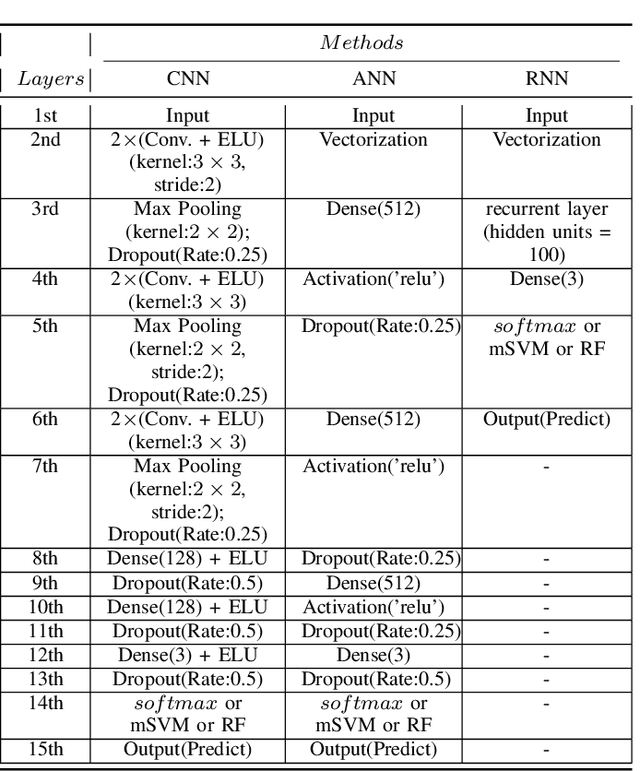
Recently, there has been a growing interest in monitoring brain activity for individual recognition system. So far these works are mainly focussing on single channel data or fragment data collected by some advanced brain monitoring modalities. In this study we propose new individual recognition schemes based on spatio-temporal resting state Electroencephalography (EEG) data. Besides, instead of using features derived from artificially-designed procedures, modified deep learning architectures which aim to automatically extract an individual's unique features are developed to conduct classification. Our designed deep learning frameworks are proved of a small but consistent advantage of replacing the $softmax$ layer with Random Forest. Additionally, a voting layer is added at the top of designed neural networks in order to tackle the classification problem arisen from EEG streams. Lastly, various experiments are implemented to evaluate the performance of the designed deep learning architectures; Results indicate that the proposed EEG-based individual recognition scheme yields a high degree of classification accuracy: $81.6\%$ for characteristics in high risk (CHR) individuals, $96.7\%$ for clinically stable first episode patients with schizophrenia (FES) and $99.2\%$ for healthy controls (HC).