 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
Apr 15, 2026Spatial reasoning over three-dimensional scenes is a core capability for embodied intelligence, yet continuous model improvement remains bottlenecked by the cost of geometric annotation. The self-evolving paradigm offers a promising path, but its reliance on model consensus to construct pseudo-labels causes training to reinforce rather than correct the model's own geometric errors. We identify a property unique to 3D spatial reasoning that circumvents this limitation: ground truth is a deterministic consequence of the underlying geometry, computable exactly from point clouds and camera poses without any model involvement. Building on this insight, we present SpatialEvo, a self-evolving framework for 3D spatial reasoning, centered on the Deterministic Geometric Environment (DGE). The DGE formalizes 16 spatial reasoning task categories under explicit geometric validation rules and converts unannotated 3D scenes into zero-noise interactive oracles, replacing model consensus with objective physical feedback. A single shared-parameter policy co-evolves across questioner and solver roles under DGE constraints: the questioner generates physically valid spatial questions grounded in scene observations, while the solver derives precise answers against DGE-verified ground truth. A task-adaptive scheduler endogenously concentrates training on the model's weakest categories, producing a dynamic curriculum without manual design. Experiments across nine benchmarks demonstrate that SpatialEvo achieves the highest average score at both 3B and 7B scales, with consistent gains on spatial reasoning benchmarks and no degradation on general visual understanding.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Structured Labeling Enables Faster Vision-Language Models for End-to-End Autonomous Driving
Jun 05, 2025Vision-Language Models (VLMs) offer a promising approach to end-to-end autonomous driving due to their human-like reasoning capabilities. However, troublesome gaps remains between current VLMs and real-world autonomous driving applications. One major limitation is that existing datasets with loosely formatted language descriptions are not machine-friendly and may introduce redundancy. Additionally, high computational cost and massive scale of VLMs hinder the inference speed and real-world deployment. To bridge the gap, this paper introduces a structured and concise benchmark dataset, NuScenes-S, which is derived from the NuScenes dataset and contains machine-friendly structured representations. Moreover, we present FastDrive, a compact VLM baseline with 0.9B parameters. In contrast to existing VLMs with over 7B parameters and unstructured language processing(e.g., LLaVA-1.5), FastDrive understands structured and concise descriptions and generates machine-friendly driving decisions with high efficiency. Extensive experiments show that FastDrive achieves competitive performance on structured dataset, with approximately 20% accuracy improvement on decision-making tasks, while surpassing massive parameter baseline in inference speed with over 10x speedup. Additionally, ablation studies further focus on the impact of scene annotations (e.g., weather, time of day) on decision-making tasks, demonstrating their importance on decision-making tasks in autonomous driving.
Structured Knowledge Distillation Towards Efficient and Compact Multi-View 3D Detection
Nov 21, 2022Detecting 3D objects from multi-view images is a fundamental problem in 3D computer vision. Recently, significant breakthrough has been made in multi-view 3D detection tasks. However, the unprecedented detection performance of these vision BEV (bird's-eye-view) detection models is accompanied with enormous parameters and computation, which make them unaffordable on edge devices. To address this problem, in this paper, we propose a structured knowledge distillation framework, aiming to improve the efficiency of modern vision-only BEV detection models. The proposed framework mainly includes: (a) spatial-temporal distillation which distills teacher knowledge of information fusion from different timestamps and views, (b) BEV response distillation which distills teacher response to different pillars, and (c) weight-inheriting which solves the problem of inconsistent inputs between students and teacher in modern transformer architectures. Experimental results show that our method leads to an average improvement of 2.16 mAP and 2.27 NDS on the nuScenes benchmark, outperforming multiple baselines by a large margin.
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Jun 21, 2022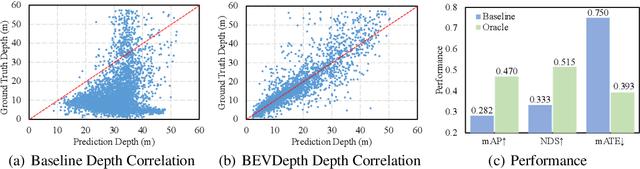
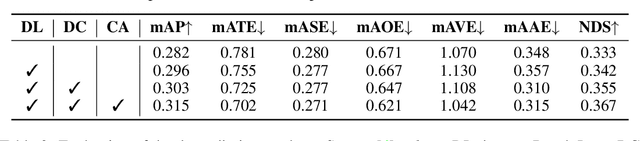
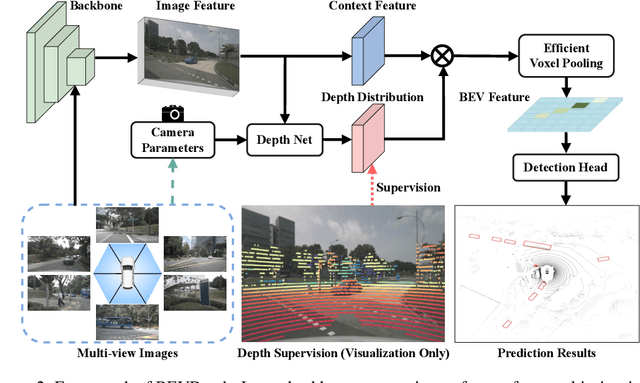
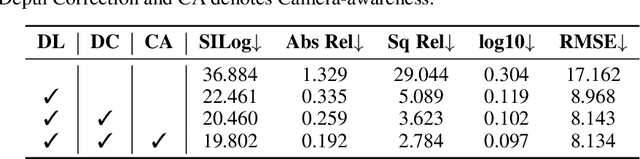
In this research, we propose a new 3D object detector with a trustworthy depth estimation, dubbed BEVDepth, for camera-based Bird's-Eye-View (BEV) 3D object detection. By a thorough analysis of recent approaches, we discover that the depth estimation is implicitly learned without camera information, making it the de-facto fake-depth for creating the following pseudo point cloud. BEVDepth gets explicit depth supervision utilizing encoded intrinsic and extrinsic parameters. A depth correction sub-network is further introduced to counteract projecting-induced disturbances in depth ground truth. To reduce the speed bottleneck while projecting features from image-view into BEV using estimated depth, a quick view-transform operation is also proposed. Besides, our BEVDepth can be easily extended with input from multi-frame. Without any bells and whistles, BEVDepth achieves the new state-of-the-art 60.0% NDS on the challenging nuScenes test set while maintaining high efficiency. For the first time, the performance gap between the camera and LiDAR is largely reduced within 10% NDS.