 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Map Prior Encoder for Mapping and Planning
May 04, 2026Online mapping and end-to-end (E2E) planning in autonomous driving remain largely sensor-centric, leaving rich map priors, including HD/SD vector maps, rasterized SD maps, and satellite imagery, underused because of heterogeneity, pose drift, and inconsistent availability at test time. We present UMPE, a Unified Map Prior Encoder that can ingest any subset of four priors and fuse them with BEV features for both mapping and planning. UMPE has two branches. The vector encoder pre-aligns HD/SD polylines with a frame-wise SE(2) correction, encodes points via multi-frequency sinusoidal features, and produces polyline tokens with confidence scores. BEV queries then apply cross-attention with confidence bias, followed by normalized channel-wise gating to avoid length imbalance and softly down-weight uncertain sources. The raster encoder shares a ResNet-18 backbone conditioned by FiLM with scaling and shift at every stage, performs SE(2) micro-alignment, and injects priors through zero-initialized residual fusion, so the network starts from a do-no-harm baseline and learns to add only useful prior evidence. A vector-then-raster fusion order reflects the inductive bias of geometry first, appearance second. On nuScenes mapping, UMPE lifts MapTRv2 from 61.5 to 67.4 mAP (+5.9) and MapQR from 66.4 to 71.7 mAP (+5.3). On Argoverse2, UMPE adds +4.1 mAP over strong baselines. UMPE is compositional: when trained with all priors, it outperforms single-prior models even when only one prior is available at test time, demonstrating powerset robustness. For E2E planning with the VAD backbone on nuScenes, UMPE reduces trajectory error from 0.72 to 0.42 m L2 on average (-0.30 m) and collision rate from 0.22% to 0.12% (-0.10%), surpassing recent prior-injection methods. These results show that a unified, alignment-aware treatment of heterogeneous map priors yields better mapping and better planning.
ETA-VLA: Efficient Token Adaptation via Temporal Fusion and Intra-LLM Sparsification for Vision-Language-Action Models
Mar 26, 2026The integration of Vision-Language-Action (VLA) models into autonomous driving systems offers a unified framework for interpreting complex scenes and executing control commands. However, the necessity to incorporate historical multi-view frames for accurate temporal reasoning imposes a severe computational burden, primarily driven by the quadratic complexity of self-attention mechanisms in Large Language Models (LLMs). To alleviate this bottleneck, we propose ETA-VLA, an Efficient Token Adaptation framework for VLA models. ETA-VLA processes the past $n$ frames of multi-view images and introduces a novel Intra-LLM Sparse Aggregator (ILSA). Drawing inspiration from human driver attention allocation, ILSA dynamically identifies and prunes redundant visual tokens guided by textual queries and temporal consistency. Specifically, we utilize a text-guided scoring mechanism alongside a diversity-preserving sparsification strategy to select a sparse subset of critical tokens, ensuring comprehensive awareness of the driving scene. Extensive experiments on the NAVSIM v2 demonstrate that ETA-VLA achieves driving performance comparable to state-of-the-art baselines while reducing computational FLOPs by approximately 32\%. Notably, our method prunes 85% of visual tokens and reduces inference FLOPs by 61\%, but still retaining 94% of the original accuracy on the NAVSIM v2 benchmark.
UniUncer: Unified Dynamic Static Uncertainty for End to End Driving
Mar 08, 2026End-to-end (E2E) driving has become a cornerstone of both industry deployment and academic research, offering a single learnable pipeline that maps multi-sensor inputs to actions while avoiding hand-engineered modules. However, the reliability of such pipelines strongly depends on how well they handle uncertainty: sensors are noisy, semantics can be ambiguous, and interaction with other road users is inherently stochastic. Uncertainty also appears in multiple forms: classification vs. localization, and, crucially, in both static map elements and dynamic agents. Existing E2E approaches model only static-map uncertainty, leaving planning vulnerable to overconfident and unreliable inputs. We present UniUncer, the first lightweight, unified uncertainty framework that jointly estimates and uses uncertainty for both static and dynamic scene elements inside an E2E planner. Concretely: (1) we convert deterministic heads to probabilistic Laplace regressors that output per-vertex location and scale for vectorized static and dynamic entities; (2) we introduce an uncertainty-fusion module that encodes these parameters and injects them into object/map queries to form uncertainty-aware queries; and (3) we design an uncertainty-aware gate that adaptively modulates reliance on historical inputs (ego status or temporal perception queries) based on current uncertainty levels. The design adds minimal overhead and drops throughput by only $\sim$0.5 FPS while remaining plug-and-play for common E2E backbones. On nuScenes (open-loop), UniUncer reduces average L2 trajectory error by 7\%. On NavsimV2 (pseudo closed-loop), it improves overall EPDMS by 10.8\% and notable stage two gains in challenging, interaction-heavy scenes. Ablations confirm that dynamic-agent uncertainty and the uncertainty-aware gate are both necessary.
HiST-VLA: A Hierarchical Spatio-Temporal Vision-Language-Action Model for End-to-End Autonomous Driving
Feb 11, 2026Vision-Language-Action (VLA) models offer promising capabilities for autonomous driving through multimodal understanding. However, their utilization in safety-critical scenarios is constrained by inherent limitations, including imprecise numerical reasoning, weak 3D spatial awareness, and high sensitivity to context. To address these challenges, we propose HiST-VLA, a novel Hierarchical Spatio-Temporal VLA model designed for reliable trajectory generation. Our framework enhances 3D spatial and temporal reasoning by integrating geometric awareness with fine-grained driving commands and state history prompting. To ensure computational efficiency, we integrate dynamic token sparsification into the VLA architecture. This approach fuses redundant tokens rather than filtering them, effectively reducing redundancy without sacrificing model performance. Furthermore, we employ a hierarchical transformer-based planner to progressively refine coarse VLA waypoints into fine-grained trajectories. Crucially, the planner utilizes dynamic latent regularization to incorporate language commands, ensuring strict spatial grounding and temporal coherence. Extensive evaluation on the NAVSIM v2 benchmark demonstrates state-of-the-art performance on Navtest, achieving an EPDMS of 88.6, and EPDMS of 50.9 on pseudo closed-loop Navhard benchmark.
FlowDrive: Energy Flow Field for End-to-End Autonomous Driving
Sep 17, 2025Recent advances in end-to-end autonomous driving leverage multi-view images to construct BEV representations for motion planning. In motion planning, autonomous vehicles need considering both hard constraints imposed by geometrically occupied obstacles (e.g., vehicles, pedestrians) and soft, rule-based semantics with no explicit geometry (e.g., lane boundaries, traffic priors). However, existing end-to-end frameworks typically rely on BEV features learned in an implicit manner, lacking explicit modeling of risk and guidance priors for safe and interpretable planning. To address this, we propose FlowDrive, a novel framework that introduces physically interpretable energy-based flow fields-including risk potential and lane attraction fields-to encode semantic priors and safety cues into the BEV space. These flow-aware features enable adaptive refinement of anchor trajectories and serve as interpretable guidance for trajectory generation. Moreover, FlowDrive decouples motion intent prediction from trajectory denoising via a conditional diffusion planner with feature-level gating, alleviating task interference and enhancing multimodal diversity. Experiments on the NAVSIM v2 benchmark demonstrate that FlowDrive achieves state-of-the-art performance with an EPDMS of 86.3, surpassing prior baselines in both safety and planning quality. The project is available at https://astrixdrive.github.io/FlowDrive.github.io/.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
SparseMeXT Unlocking the Potential of Sparse Representations for HD Map Construction
May 12, 2025Recent advancements in high-definition \emph{HD} map construction have demonstrated the effectiveness of dense representations, which heavily rely on computationally intensive bird's-eye view \emph{BEV} features. While sparse representations offer a more efficient alternative by avoiding dense BEV processing, existing methods often lag behind due to the lack of tailored designs. These limitations have hindered the competitiveness of sparse representations in online HD map construction. In this work, we systematically revisit and enhance sparse representation techniques, identifying key architectural and algorithmic improvements that bridge the gap with--and ultimately surpass--dense approaches. We introduce a dedicated network architecture optimized for sparse map feature extraction, a sparse-dense segmentation auxiliary task to better leverage geometric and semantic cues, and a denoising module guided by physical priors to refine predictions. Through these enhancements, our method achieves state-of-the-art performance on the nuScenes dataset, significantly advancing HD map construction and centerline detection. Specifically, SparseMeXt-Tiny reaches a mean average precision \emph{mAP} of 55.5% at 32 frames per second \emph{fps}, while SparseMeXt-Base attains 65.2% mAP. Scaling the backbone and decoder further, SparseMeXt-Large achieves an mAP of 68.9% at over 20 fps, establishing a new benchmark for sparse representations in HD map construction. These results underscore the untapped potential of sparse methods, challenging the conventional reliance on dense representations and redefining efficiency-performance trade-offs in the field.
A Reinforcement learning method for Optical Thin-Film Design
Feb 13, 2021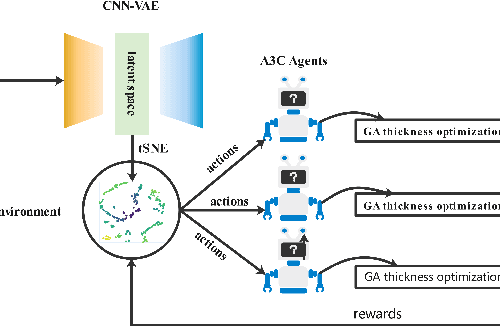
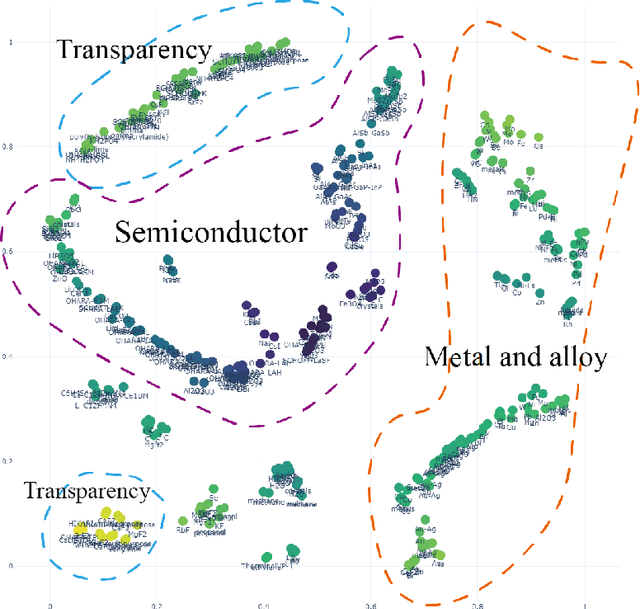
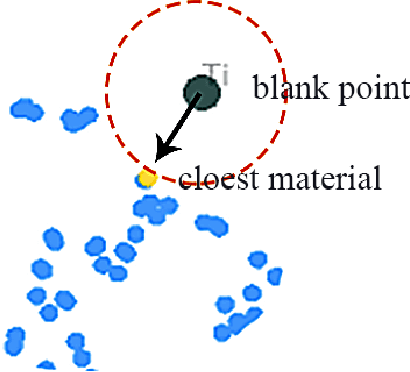
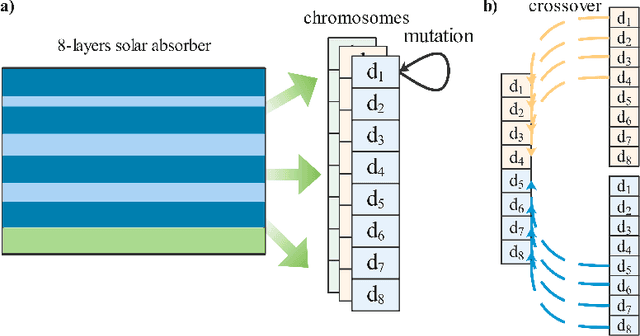
Machine learning, especially deep learning, is dramatically changing the methods associated with optical thin-film inverse design. The vast majority of this research has focused on the parameter optimization (layer thickness, and structure size) of optical thin-films. A challenging problem that arises is an automated material search. In this work, we propose a new end-to-end algorithm for optical thin-film inverse design. This method combines the ability of unsupervised learning, reinforcement learning(RL) and includes a genetic algorithm to design an optical thin-film without any human intervention. Furthermore, with several concrete examples, we have shown how one can use this technique to optimize the spectra of a multi-layer solar absorber device.
A new multilayer optical film optimal method based on deep q-learning
Dec 07, 2018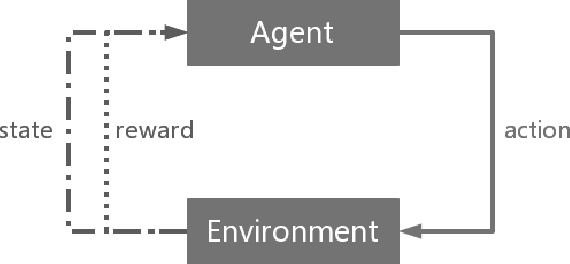
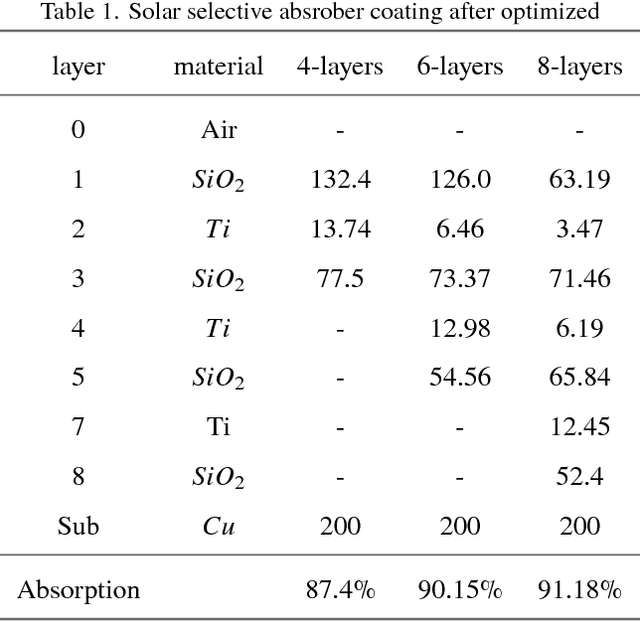
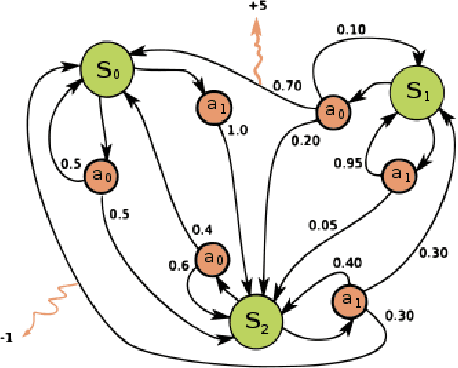
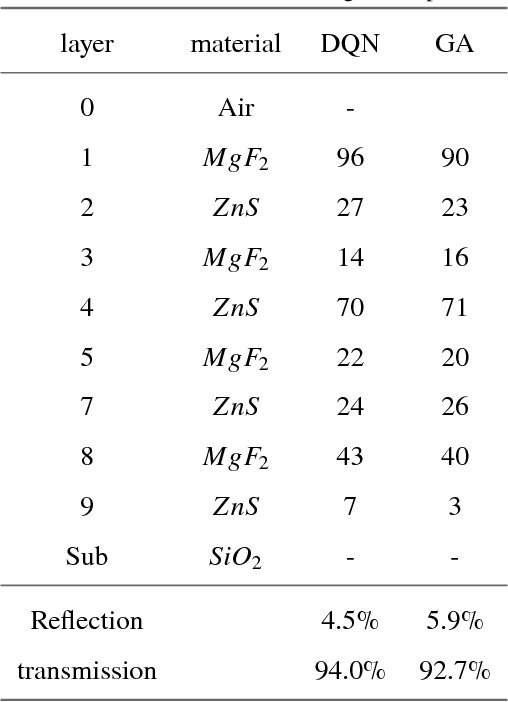
Multi-layer optical film has been found to afford important applications in optical communication, optical absorbers, optical filters, etc. Different algorithms of multi-layer optical film design has been developed, as simplex method, colony algorithm, genetic algorithm. These algorithms rapidly promote the design and manufacture of multi-layer films. However, traditional numerical algorithms of converge to local optimum. This means that the algorithms can not give a global optimal solution to the material researchers. In recent years, due to the rapid development to far artificial intelligence, to optimize optical film structure using AI algorithm has become possible. In this paper, we will introduce a new optical film design algorithm based on the deep Q learning. This model can converge the global optimum of the optical thin film structure, this will greatly improve the design efficiency of multi-layer films.