 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERL: Self-Examining Reinforcement Learning on Open-Domain
Nov 18, 2025Reinforcement Learning (RL) has been shown to improve the capabilities of large language models (LLMs). However, applying RL to open-domain tasks faces two key challenges: (1) the inherent subjectivity of these tasks prevents the verifiable rewards as required by Reinforcement Learning with Verifiable Rewards (RLVR); (2) Reinforcement Learning from Human Feedback (RLHF) relies on external reward mechanisms. To overcome these limitations, we propose Self-Examining Reinforcement Learning (SERL), a novel self-improving framework where the LLM serves as both Actor and Judge. SERL introduces two synergistic reward mechanisms without any external signals. On the one hand, to improve the Actor's capability, we derive rewards from Copeland-style pairwise comparison judgments across a group of generated responses. On the other hand, a self-consistency reward that encourages coherent judgments is proposed to improve the Judge's reliability. This process refines the Judge's capability, which in turn provides a more robust reward for Actor. Experiments show that our method outperforms existing self-improvement training methods. SERL improves the LC win rate of Qwen3-8B on AlpacaEval 2 from 52.37% to 59.90%. To the best of our knowledge, our method achieves state-of-the-art performance among self-improving approaches. Furthermore, it achieves a performance comparable to significantly larger models like Qwen3-32B, demonstrating superior effectiveness and robustness on open-domain tasks.
SenseRay-3D: Generalizable and Physics-Informed Framework for End-to-End Indoor Propagation Modeling
Nov 15, 2025Modeling indoor radio propagation is crucial for wireless network planning and optimization. However, existing approaches often rely on labor-intensive manual modeling of geometry and material properties, resulting in limited scalability and efficiency. To overcome these challenges, this paper presents SenseRay-3D, a generalizable and physics-informed end-to-end framework that predicts three-dimensional (3D) path-loss heatmaps directly from RGB-D scans, thereby eliminating the need for explicit geometry reconstruction or material annotation. The proposed framework builds a sensing-driven voxelized scene representation that jointly encodes occupancy, electromagnetic material characteristics, and transmitter-receiver geometry, which is processed by a SwinUNETR-based neural network to infer environmental path-loss relative to free-space path-loss. A comprehensive synthetic indoor propagation dataset is further developed to validate the framework and to serve as a standardized benchmark for future research. Experimental results show that SenseRay-3D achieves a mean absolute error of 4.27 dB on unseen environments and supports real-time inference at 217 ms per sample, demonstrating its scalability, efficiency, and physical consistency. SenseRay-3D paves a new path for sense-driven, generalizable, and physics-consistent modeling of indoor propagation, marking a major leap beyond our pioneering EM DeepRay framework.
Step-Audio-EditX Technical Report
Nov 05, 2025


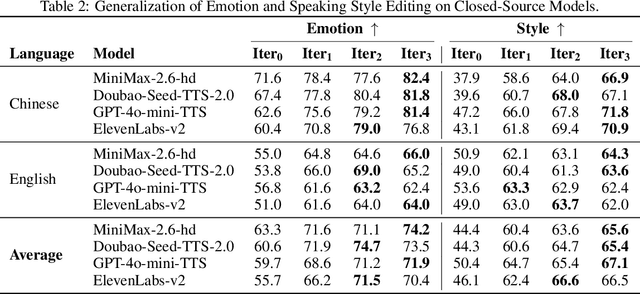
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
WithAnyone: Towards Controllable and ID Consistent Image Generation
Oct 16, 2025Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
pFedSAM: Personalized Federated Learning of Segment Anything Model for Medical Image Segmentation
Sep 19, 2025Medical image segmentation is crucial for computer-aided diagnosis, yet privacy constraints hinder data sharing across institutions. Federated learning addresses this limitation, but existing approaches often rely on lightweight architectures that struggle with complex, heterogeneous data. Recently, the Segment Anything Model (SAM) has shown outstanding segmentation capabilities; however, its massive encoder poses significant challenges in federated settings. In this work, we present the first personalized federated SAM framework tailored for heterogeneous data scenarios in medical image segmentation. Our framework integrates two key innovations: (1) a personalized strategy that aggregates only the global parameters to capture cross-client commonalities while retaining the designed L-MoE (Localized Mixture-of-Experts) component to preserve domain-specific features; and (2) a decoupled global-local fine-tuning mechanism that leverages a teacher-student paradigm via knowledge distillation to bridge the gap between the global shared model and the personalized local models, thereby mitigating overgeneralization. Extensive experiments on two public datasets validate that our approach significantly improves segmentation performance, achieves robust cross-domain adaptation, and reduces communication overhead.
Training-Free Text-Guided Color Editing with Multi-Modal Diffusion Transformer
Aug 12, 2025



Text-guided color editing in images and videos is a fundamental yet unsolved problem, requiring fine-grained manipulation of color attributes, including albedo, light source color, and ambient lighting, while preserving physical consistency in geometry, material properties, and light-matter interactions. Existing training-free methods offer broad applicability across editing tasks but struggle with precise color control and often introduce visual inconsistency in both edited and non-edited regions. In this work, we present ColorCtrl, a training-free color editing method that leverages the attention mechanisms of modern Multi-Modal Diffusion Transformers (MM-DiT). By disentangling structure and color through targeted manipulation of attention maps and value tokens, our method enables accurate and consistent color editing, along with word-level control of attribute intensity. Our method modifies only the intended regions specified by the prompt, leaving unrelated areas untouched. Extensive experiments on both SD3 and FLUX.1-dev demonstrate that ColorCtrl outperforms existing training-free approaches and achieves state-of-the-art performances in both edit quality and consistency. Furthermore, our method surpasses strong commercial models such as FLUX.1 Kontext Max and GPT-4o Image Generation in terms of consistency. When extended to video models like CogVideoX, our approach exhibits greater advantages, particularly in maintaining temporal coherence and editing stability. Finally, our method also generalizes to instruction-based editing diffusion models such as Step1X-Edit and FLUX.1 Kontext dev, further demonstrating its versatility.
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning
Aug 08, 2025We propose SC-Captioner, a reinforcement learning framework that enables the self-correcting capability of image caption models. Our crucial technique lies in the design of the reward function to incentivize accurate caption corrections. Specifically, the predicted and reference captions are decomposed into object, attribute, and relation sets using scene-graph parsing algorithms. We calculate the set difference between sets of initial and self-corrected captions to identify added and removed elements. These elements are matched against the reference sets to calculate correctness bonuses for accurate refinements and mistake punishments for wrong additions and removals, thereby forming the final reward. For image caption quality assessment, we propose a set of metrics refined from CAPTURE that alleviate its incomplete precision evaluation and inefficient relation matching problems. Furthermore, we collect a fine-grained annotated image caption dataset, RefinedCaps, consisting of 6.5K diverse images from COCO dataset. Experiments show that applying SC-Captioner on large visual-language models can generate better image captions across various scenarios, significantly outperforming the direct preference optimization training strategy.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.