 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
Step-Audio-EditX Technical Report
Nov 05, 2025


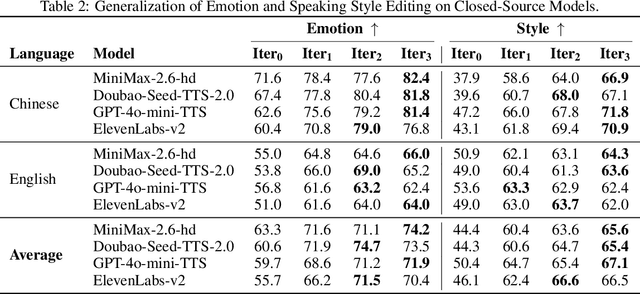
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Takin: A Cohort of Superior Quality Zero-shot Speech Generation Models
Sep 18, 2024



With the advent of the big data and large language model era, zero-shot personalized rapid customization has emerged as a significant trend. In this report, we introduce Takin AudioLLM, a series of techniques and models, mainly including Takin TTS, Takin VC, and Takin Morphing, specifically designed for audiobook production. These models are capable of zero-shot speech production, generating high-quality speech that is nearly indistinguishable from real human speech and facilitating individuals to customize the speech content according to their own needs. Specifically, we first introduce Takin TTS, a neural codec language model that builds upon an enhanced neural speech codec and a multi-task training framework, capable of generating high-fidelity natural speech in a zero-shot way. For Takin VC, we advocate an effective content and timbre joint modeling approach to improve the speaker similarity, while advocating for a conditional flow matching based decoder to further enhance its naturalness and expressiveness. Last, we propose the Takin Morphing system with highly decoupled and advanced timbre and prosody modeling approaches, which enables individuals to customize speech production with their preferred timbre and prosody in a precise and controllable manner. Extensive experiments validate the effectiveness and robustness of our Takin AudioLLM series models. For detailed demos, please refer to https://takinaudiollm.github.io.