 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Harness: Harnesses That Improve Themselves
Jun 08, 2026The performance of LLM-based agents is jointly shaped by their base models and the harnesses that mediate their interaction with the environment. Because different models exhibit distinct behaviors, effective harness design is inherently model-specific. Yet agent harnesses are still largely engineered by human experts, a paradigm that scales poorly as modern LLMs become increasingly diverse and rapidly evolving. In this paper, we introduce Self-Harness, a new paradigm in which an LLM-based agent improves its own operating harness, without relying on human engineers or stronger external agents. We operationalize Self-Harness as an iterative loop with three stages: Weakness Mining, which identifies model-specific failure patterns from execution traces; Harness Proposal, which generates diverse yet minimal harness modifications tied to these failures; and Proposal Validation, which accepts candidate edits only after regression testing. We instantiate Self-Harness on Terminal-Bench-2.0 using a minimal initial harness and three base models from diverse families: MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5. Across all three models, Self-Harness consistently improves performance, with held-out pass rates increasing from 40.5% to 61.9%, 23.8% to 38.1%, and 42.9% to 57.1%, respectively. Qualitative analyses further show that Self-Harness does not simply add generic instructions, but effectively turns model-specific weaknesses into concrete, executable harness changes. These results suggest a path toward LLM-based agents that are not merely shaped by their harnesses, but can also participate in reshaping them.
CurveStream: Boosting Streaming Video Understanding in MLLMs via Curvature-Aware Hierarchical Visual Memory Management
Mar 20, 2026Multimodal Large Language Models have achieved significant success in offline video understanding, yet their application to streaming videos is severely limited by the linear explosion of visual tokens, which often leads to Out-of-Memory (OOM) errors or catastrophic forgetting. Existing visual retention and memory management methods typically rely on uniform sampling, low-level physical metrics, or passive cache eviction. However, these strategies often lack intrinsic semantic awareness, potentially disrupting contextual coherence and blurring transient yet critical semantic transitions. To address these limitations, we propose CurveStream, a training-free, curvature-aware hierarchical visual memory management framework. Our approach is motivated by the key observation that high-curvature regions along continuous feature trajectories closely align with critical global semantic transitions. Based on this geometric insight, CurveStream evaluates real-time semantic intensity via a Curvature Score and integrates an online K-Sigma dynamic threshold to adaptively route frames into clear and fuzzy memory states under a strict token budget. Evaluations across diverse temporal scales confirm that this lightweight framework, CurveStream, consistently yields absolute performance gains of over 10% (e.g., 10.69% on StreamingBench and 13.58% on OVOBench) over respective baselines, establishing new state-of-the-art results for streaming video perception.The code will be released at https://github.com/streamingvideos/CurveStream.
FreshMem: Brain-Inspired Frequency-Space Hybrid Memory for Streaming Video Understanding
Feb 02, 2026Transitioning Multimodal Large Language Models (MLLMs) from offline to online streaming video understanding is essential for continuous perception. However, existing methods lack flexible adaptivity, leading to irreversible detail loss and context fragmentation. To resolve this, we propose FreshMem, a Frequency-Space Hybrid Memory network inspired by the brain's logarithmic perception and memory consolidation. FreshMem reconciles short-term fidelity with long-term coherence through two synergistic modules: Multi-scale Frequency Memory (MFM), which projects overflowing frames into representative frequency coefficients, complemented by residual details to reconstruct a global historical "gist"; and Space Thumbnail Memory (STM), which discretizes the continuous stream into episodic clusters by employing an adaptive compression strategy to distill them into high-density space thumbnails. Extensive experiments show that FreshMem significantly boosts the Qwen2-VL baseline, yielding gains of 5.20%, 4.52%, and 2.34% on StreamingBench, OV-Bench, and OVO-Bench, respectively. As a training-free solution, FreshMem outperforms several fully fine-tuned methods, offering a highly efficient paradigm for long-horizon streaming video understanding.
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning
Aug 08, 2025We propose SC-Captioner, a reinforcement learning framework that enables the self-correcting capability of image caption models. Our crucial technique lies in the design of the reward function to incentivize accurate caption corrections. Specifically, the predicted and reference captions are decomposed into object, attribute, and relation sets using scene-graph parsing algorithms. We calculate the set difference between sets of initial and self-corrected captions to identify added and removed elements. These elements are matched against the reference sets to calculate correctness bonuses for accurate refinements and mistake punishments for wrong additions and removals, thereby forming the final reward. For image caption quality assessment, we propose a set of metrics refined from CAPTURE that alleviate its incomplete precision evaluation and inefficient relation matching problems. Furthermore, we collect a fine-grained annotated image caption dataset, RefinedCaps, consisting of 6.5K diverse images from COCO dataset. Experiments show that applying SC-Captioner on large visual-language models can generate better image captions across various scenarios, significantly outperforming the direct preference optimization training strategy.
Multi-Level Decoupled Relational Distillation for Heterogeneous Architectures
Feb 10, 2025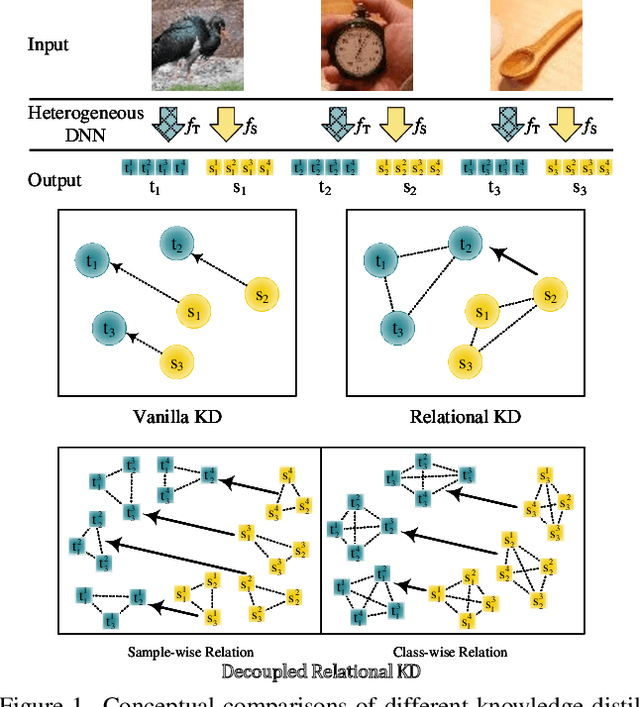



Heterogeneous distillation is an effective way to transfer knowledge from cross-architecture teacher models to student models. However, existing heterogeneous distillation methods do not take full advantage of the dark knowledge hidden in the teacher's output, limiting their performance.To this end, we propose a novel framework named Multi-Level Decoupled Relational Knowledge Distillation (MLDR-KD) to unleash the potential of relational distillation in heterogeneous distillation. Concretely, we first introduce Decoupled Finegrained Relation Alignment (DFRA) in both logit and feature levels to balance the trade-off between distilled dark knowledge and the confidence in the correct category of the heterogeneous teacher model. Then, Multi-Scale Dynamic Fusion (MSDF) module is applied to dynamically fuse the projected logits of multiscale features at different stages in student model, further improving performance of our method in feature level. We verify our method on four architectures (CNNs, Transformers, MLPs and Mambas), two datasets (CIFAR-100 and Tiny-ImageNet). Compared with the best available method, our MLDR-KD improves student model performance with gains of up to 4.86% on CIFAR-100 and 2.78% on Tiny-ImageNet datasets respectively, showing robustness and generality in heterogeneous distillation. Code will be released soon.