 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Cache Once: Decoder-Decoder Architectures for Language Models
May 08, 2024We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes. Code is available at https://aka.ms/YOCO.
Semi-Parametric Retrieval via Binary Token Index
May 03, 2024The landscape of information retrieval has broadened from search services to a critical component in various advanced applications, where indexing efficiency, cost-effectiveness, and freshness are increasingly important yet remain less explored. To address these demands, we introduce Semi-parametric Vocabulary Disentangled Retrieval (SVDR). SVDR is a novel semi-parametric retrieval framework that supports two types of indexes: an embedding-based index for high effectiveness, akin to existing neural retrieval methods; and a binary token index that allows for quick and cost-effective setup, resembling traditional term-based retrieval. In our evaluation on three open-domain question answering benchmarks with the entire Wikipedia as the retrieval corpus, SVDR consistently demonstrates superiority. It achieves a 3% higher top-1 retrieval accuracy compared to the dense retriever DPR when using an embedding-based index and an 9% higher top-1 accuracy compared to BM25 when using a binary token index. Specifically, the adoption of a binary token index reduces index preparation time from 30 GPU hours to just 2 CPU hours and storage size from 31 GB to 2 GB, achieving a 90% reduction compared to an embedding-based index.
Multimodal Large Language Model is a Human-Aligned Annotator for Text-to-Image Generation
Apr 23, 2024Recent studies have demonstrated the exceptional potentials of leveraging human preference datasets to refine text-to-image generative models, enhancing the alignment between generated images and textual prompts. Despite these advances, current human preference datasets are either prohibitively expensive to construct or suffer from a lack of diversity in preference dimensions, resulting in limited applicability for instruction tuning in open-source text-to-image generative models and hinder further exploration. To address these challenges and promote the alignment of generative models through instruction tuning, we leverage multimodal large language models to create VisionPrefer, a high-quality and fine-grained preference dataset that captures multiple preference aspects. We aggregate feedback from AI annotators across four aspects: prompt-following, aesthetic, fidelity, and harmlessness to construct VisionPrefer. To validate the effectiveness of VisionPrefer, we train a reward model VP-Score over VisionPrefer to guide the training of text-to-image generative models and the preference prediction accuracy of VP-Score is comparable to human annotators. Furthermore, we use two reinforcement learning methods to supervised fine-tune generative models to evaluate the performance of VisionPrefer, and extensive experimental results demonstrate that VisionPrefer significantly improves text-image alignment in compositional image generation across diverse aspects, e.g., aesthetic, and generalizes better than previous human-preference metrics across various image distributions. Moreover, VisionPrefer indicates that the integration of AI-generated synthetic data as a supervisory signal is a promising avenue for achieving improved alignment with human preferences in vision generative models.
Multi-Head Mixture-of-Experts
Apr 23, 2024Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibits the following two issues: (1) Low expert activation, where only a small subset of experts are activated for optimization. (2) Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form. The multi-head mechanism enables the model to collectively attend to information from various representation spaces within different experts, while significantly enhances expert activation, thus deepens context understanding and alleviate overfitting. Moreover, our MH-MoE is straightforward to implement and decouples from other SMoE optimization methods, making it easy to integrate with other SMoE models for enhanced performance. Extensive experimental results across three tasks: English-focused language modeling, Multi-lingual language modeling and Masked multi-modality modeling tasks, demonstrate the effectiveness of MH-MoE.
Mixture of LoRA Experts
Apr 21, 2024LoRA has gained widespread acceptance in the fine-tuning of large pre-trained models to cater to a diverse array of downstream tasks, showcasing notable effectiveness and efficiency, thereby solidifying its position as one of the most prevalent fine-tuning techniques. Due to the modular nature of LoRA's plug-and-play plugins, researchers have delved into the amalgamation of multiple LoRAs to empower models to excel across various downstream tasks. Nonetheless, extant approaches for LoRA fusion grapple with inherent challenges. Direct arithmetic merging may result in the loss of the original pre-trained model's generative capabilities or the distinct identity of LoRAs, thereby yielding suboptimal outcomes. On the other hand, Reference tuning-based fusion exhibits limitations concerning the requisite flexibility for the effective combination of multiple LoRAs. In response to these challenges, this paper introduces the Mixture of LoRA Experts (MoLE) approach, which harnesses hierarchical control and unfettered branch selection. The MoLE approach not only achieves superior LoRA fusion performance in comparison to direct arithmetic merging but also retains the crucial flexibility for combining LoRAs effectively. Extensive experimental evaluations conducted in both the Natural Language Processing (NLP) and Vision & Language (V&L) domains substantiate the efficacy of MoLE.
LongEmbed: Extending Embedding Models for Long Context Retrieval
Apr 18, 2024Embedding models play a pivot role in modern NLP applications such as IR and RAG. While the context limit of LLMs has been pushed beyond 1 million tokens, embedding models are still confined to a narrow context window not exceeding 8k tokens, refrained from application scenarios requiring long inputs such as legal contracts. This paper explores context window extension of existing embedding models, pushing the limit to 32k without requiring additional training. First, we examine the performance of current embedding models for long context retrieval on our newly constructed LongEmbed benchmark. LongEmbed comprises two synthetic tasks and four carefully chosen real-world tasks, featuring documents of varying length and dispersed target information. Benchmarking results underscore huge room for improvement in these models. Based on this, comprehensive experiments show that training-free context window extension strategies like position interpolation can effectively extend the context window of existing embedding models by several folds, regardless of their original context being 512 or beyond 4k. Furthermore, for models employing absolute position encoding (APE), we show the possibility of further fine-tuning to harvest notable performance gains while strictly preserving original behavior for short inputs. For models using rotary position embedding (RoPE), significant enhancements are observed when employing RoPE-specific methods, such as NTK and SelfExtend, indicating RoPE's superiority over APE for context window extension. To facilitate future research, we release E5-Base-4k and E5-RoPE-Base, along with the LongEmbed benchmark.
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Apr 04, 2024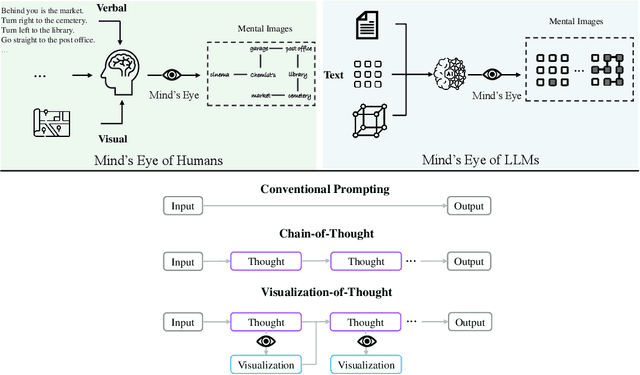
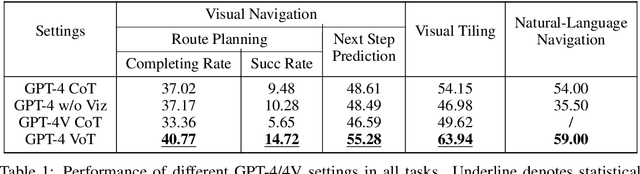
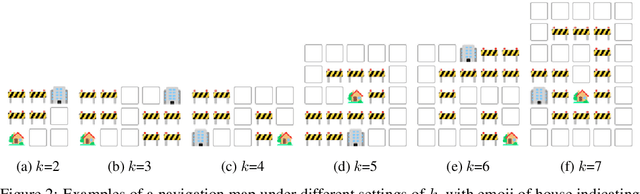
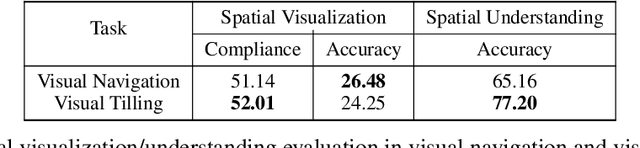
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as \textbf{the Mind's Eye}, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (\textbf{VoT}) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate \textit{mental images} to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024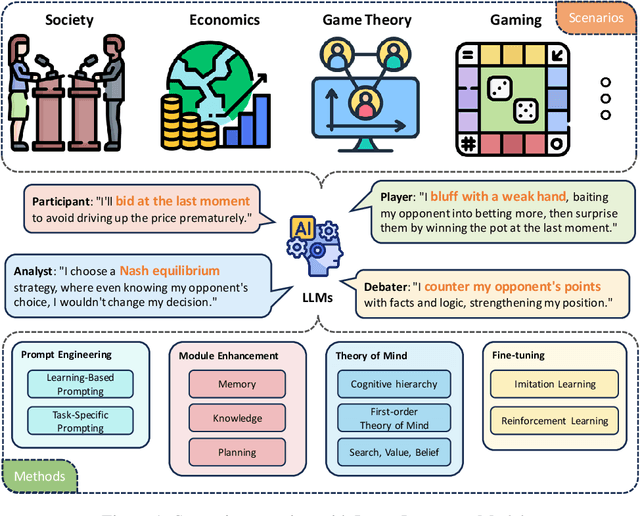
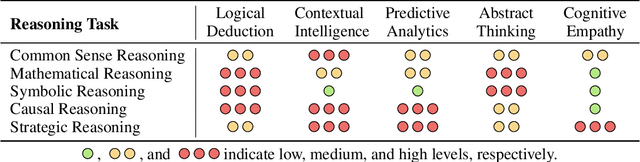
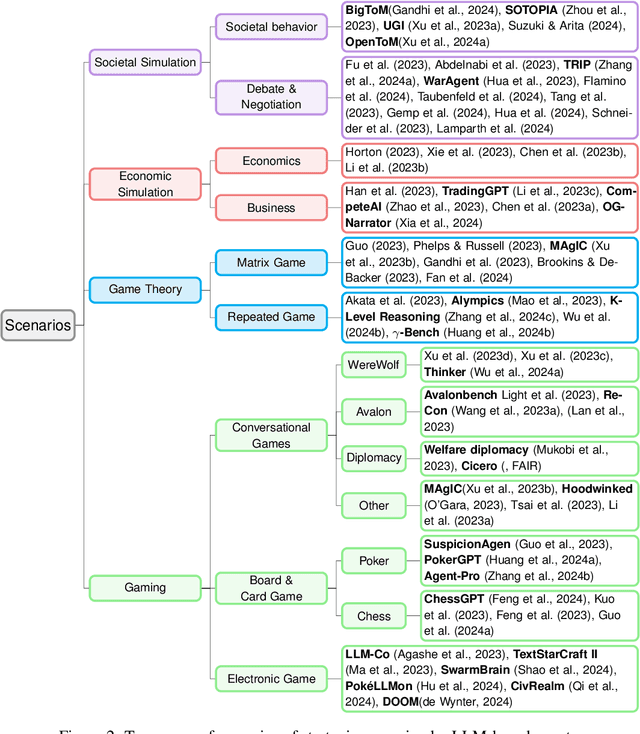

This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Mar 31, 2024The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at \url{aka.ms/wavllm}.
$Se^2$: Sequential Example Selection for In-Context Learning
Mar 06, 2024



The remarkable capability of large language models (LLMs) for in-context learning (ICL) needs to be activated by demonstration examples. Prior work has extensively explored the selection of examples for ICL, predominantly following the "select then organize" paradigm, such approaches often neglect the internal relationships between examples and exist an inconsistency between the training and inference. In this paper, we formulate the problem as a $\textit{se}$quential $\textit{se}$lection problem and introduce $Se^2$, a sequential-aware method that leverages the LLM's feedback on varying context, aiding in capturing inter-relationships and sequential information among examples, significantly enriching the contextuality and relevance of ICL prompts. Meanwhile, we utilize beam search to seek and construct example sequences, enhancing both quality and diversity. Extensive experiments across 23 NLP tasks from 8 distinct categories illustrate that $Se^2$ markedly surpasses competitive baselines and achieves 42% relative improvement over random selection. Further in-depth analysis show the effectiveness of proposed strategies, highlighting $Se^2$'s exceptional stability and adaptability across various scenarios. Our code will be released to facilitate future research.