 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?
Jun 09, 2026The deployment of Large Language Model (LLM) agents for computer automation is accelerating, yet their ability to navigate complex, professional-grade productivity software is largely untested. We argue that Office automation is an ideal environment for benchmarking document-automation capability, as it requires long-horizon planning and reasoning, precise parameter configuration, and multi-application integration. To quantify this capability, we introduce an evaluation based on China's National Computer Rank Examination (NCRE), featuring 200 comprehensive practical-operation tasks across Word, Excel, and PowerPoint. Each task is scored on a 100-point rubric scale using 7,118 machine-gradable criteria, and Score Rate (SR) denotes the mean percentage of rubric points earned across these tasks. We benchmark 7 frontier LLMs and observe stark limitations: single-turn models score a maximum of 36.6%. A stronger agentic system with execution feedback, iterative repair, and broader Office automation access reaches 68.8%, but remains below the 95.5% community-reference score used as a scoring sanity check. Ultimately, our experiments demonstrate that despite recent advancements in code generation, achieving reliable fine-grained Office document automation remains a significant challenge for current code-generating LLM and agent systems.
Demystifying Data Organization for Enhanced LLM Training
May 28, 2026Large Language Models (LLMs) have revolutionized various fields, yet their training efficiency is heavily reliant on effective data curation. While data selection has been widely studied, the strategic data organization for enhanced training remains an underexplored area, particularly since current LLMs are often trained for only one or a few epochs. This paper systematically explores the influence of data organization on LLM training by reusing pre-computed sample-level scores originally generated for data efficiency, thereby incurring minimal additional computational overhead. We identify and formalize four key guidelines for optimizing data organization: Boundary Sharpening, Cyclic Scheduling, Curriculum Continuity, and Local Diversity. Guided by them, we introduce two novel data ordering methods termed STR and SAW. Extensive experiments across different model scales and data sizes, encompassing both pre-training and SFT stages, validate the effectiveness of our summarized guidelines. They also demonstrate the robustness of our proposed data ordering methods in enhancing the stability and performance of LLM training. Github Link: https://github.com/microsoft/data-efficacy/
GENIUS: Generative Fluid Intelligence Evaluation Suite
Feb 11, 2026Unified Multimodal Models (UMMs) have shown remarkable progress in visual generation. Yet, existing benchmarks predominantly assess $\textit{Crystallized Intelligence}$, which relies on recalling accumulated knowledge and learned schemas. This focus overlooks $\textit{Generative Fluid Intelligence (GFI)}$: the capacity to induce patterns, reason through constraints, and adapt to novel scenarios on the fly. To rigorously assess this capability, we introduce $\textbf{GENIUS}$ ($\textbf{GEN}$ Fluid $\textbf{I}$ntelligence Eval$\textbf{U}$ation $\textbf{S}$uite). We formalize $\textit{GFI}$ as a synthesis of three primitives. These include $\textit{Inducing Implicit Patterns}$ (e.g., inferring personalized visual preferences), $\textit{Executing Ad-hoc Constraints}$ (e.g., visualizing abstract metaphors), and $\textit{Adapting to Contextual Knowledge}$ (e.g., simulating counter-intuitive physics). Collectively, these primitives challenge models to solve problems grounded entirely in the immediate context. Our systematic evaluation of 12 representative models reveals significant performance deficits in these tasks. Crucially, our diagnostic analysis disentangles these failure modes. It demonstrates that deficits stem from limited context comprehension rather than insufficient intrinsic generative capability. To bridge this gap, we propose a training-free attention intervention strategy. Ultimately, $\textbf{GENIUS}$ establishes a rigorous standard for $\textit{GFI}$, guiding the field beyond knowledge utilization toward dynamic, general-purpose reasoning. Our dataset and code will be released at: $\href{https://github.com/arctanxarc/GENIUS}{https://github.com/arctanxarc/GENIUS}$.
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
Aug 27, 2025For human cognitive process, spatial reasoning and perception are closely entangled, yet the nature of this interplay remains underexplored in the evaluation of multimodal large language models (MLLMs). While recent MLLM advancements show impressive performance on reasoning, their capacity for human-like spatial cognition remains an open question. In this work, we introduce a systematic evaluation framework to assess the spatial reasoning abilities of state-of-the-art MLLMs relative to human performance. Central to our work is 11Plus-Bench, a high-quality benchmark derived from realistic standardized spatial aptitude tests. 11Plus-Bench also features fine-grained expert annotations of both perceptual complexity and reasoning process, enabling detailed instance-level analysis of model behavior. Through extensive experiments across 14 MLLMs and human evaluation, we find that current MLLMs exhibit early signs of spatial cognition. Despite a large performance gap compared to humans, MLLMs' cognitive profiles resemble those of humans in that cognitive effort correlates strongly with reasoning-related complexity. However, instance-level performance in MLLMs remains largely random, whereas human correctness is highly predictable and shaped by abstract pattern complexity. These findings highlight both emerging capabilities and limitations in current MLLMs' spatial reasoning capabilities and provide actionable insights for advancing model design.
Data Efficacy for Language Model Training
Jun 26, 2025Data is fundamental to the training of language models (LM). Recent research has been dedicated to data efficiency, which aims to maximize performance by selecting a minimal or optimal subset of training data. Techniques such as data filtering, sampling, and selection play a crucial role in this area. To complement it, we define Data Efficacy, which focuses on maximizing performance by optimizing the organization of training data and remains relatively underexplored. This work introduces a general paradigm, DELT, for considering data efficacy in LM training, which highlights the significance of training data organization. DELT comprises three components: Data Scoring, Data Selection, and Data Ordering. Among these components, we design Learnability-Quality Scoring (LQS), as a new instance of Data Scoring, which considers both the learnability and quality of each data sample from the gradient consistency perspective. We also devise Folding Ordering (FO), as a novel instance of Data Ordering, which addresses issues such as model forgetting and data distribution bias. Comprehensive experiments validate the data efficacy in LM training, which demonstrates the following: Firstly, various instances of the proposed DELT enhance LM performance to varying degrees without increasing the data scale and model size. Secondly, among these instances, the combination of our proposed LQS for data scoring and Folding for data ordering achieves the most significant improvement. Lastly, data efficacy can be achieved together with data efficiency by applying data selection. Therefore, we believe that data efficacy is a promising foundational area in LM training.
A Call for New Recipes to Enhance Spatial Reasoning in MLLMs
Apr 21, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in general vision-language tasks. However, recent studies have exposed critical limitations in their spatial reasoning capabilities. This deficiency in spatial reasoning significantly constrains MLLMs' ability to interact effectively with the physical world, thereby limiting their broader applications. We argue that spatial reasoning capabilities will not naturally emerge from merely scaling existing architectures and training methodologies. Instead, this challenge demands dedicated attention to fundamental modifications in the current MLLM development approach. In this position paper, we first establish a comprehensive framework for spatial reasoning within the context of MLLMs. We then elaborate on its pivotal role in real-world applications. Through systematic analysis, we examine how individual components of the current methodology-from training data to reasoning mechanisms-influence spatial reasoning capabilities. This examination reveals critical limitations while simultaneously identifying promising avenues for advancement. Our work aims to direct the AI research community's attention toward these crucial yet underexplored aspects. By highlighting these challenges and opportunities, we seek to catalyze progress toward achieving human-like spatial reasoning capabilities in MLLMs.
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Jan 13, 2025



Chain-of-Thought (CoT) prompting has proven highly effective for enhancing complex reasoning in Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Yet, it struggles in complex spatial reasoning tasks. Nonetheless, human cognition extends beyond language alone, enabling the remarkable capability to think in both words and images. Inspired by this mechanism, we propose a new reasoning paradigm, Multimodal Visualization-of-Thought (MVoT). It enables visual thinking in MLLMs by generating image visualizations of their reasoning traces. To ensure high-quality visualization, we introduce token discrepancy loss into autoregressive MLLMs. This innovation significantly improves both visual coherence and fidelity. We validate this approach through several dynamic spatial reasoning tasks. Experimental results reveal that MVoT demonstrates competitive performance across tasks. Moreover, it exhibits robust and reliable improvements in the most challenging scenarios where CoT fails. Ultimately, MVoT establishes new possibilities for complex reasoning tasks where visual thinking can effectively complement verbal reasoning.
Enhancing Language Model Rationality with Bi-Directional Deliberation Reasoning
Jul 08, 2024



This paper introduces BI-Directional DEliberation Reasoning (BIDDER), a novel reasoning approach to enhance the decision rationality of language models. Traditional reasoning methods typically rely on historical information and employ uni-directional (left-to-right) reasoning strategy. This lack of bi-directional deliberation reasoning results in limited awareness of potential future outcomes and insufficient integration of historical context, leading to suboptimal decisions. BIDDER addresses this gap by incorporating principles of rational decision-making, specifically managing uncertainty and predicting expected utility. Our approach involves three key processes: Inferring hidden states to represent uncertain information in the decision-making process from historical data; Using these hidden states to predict future potential states and potential outcomes; Integrating historical information (past contexts) and long-term outcomes (future contexts) to inform reasoning. By leveraging bi-directional reasoning, BIDDER ensures thorough exploration of both past and future contexts, leading to more informed and rational decisions. We tested BIDDER's effectiveness in two well-defined scenarios: Poker (Limit Texas Hold'em) and Negotiation. Our experiments demonstrate that BIDDER significantly improves the decision-making capabilities of LLMs and LLM agents.
Meta Reasoning for Large Language Models
Jun 17, 2024



We introduce Meta-Reasoning Prompting (MRP), a novel and efficient system prompting method for large language models (LLMs) inspired by human meta-reasoning. Traditional in-context learning-based reasoning techniques, such as Tree-of-Thoughts, show promise but lack consistent state-of-the-art performance across diverse tasks due to their specialized nature. MRP addresses this limitation by guiding LLMs to dynamically select and apply different reasoning methods based on the specific requirements of each task, optimizing both performance and computational efficiency. With MRP, LLM reasoning operates in two phases. Initially, the LLM identifies the most appropriate reasoning method using task input cues and objective descriptions of available methods. Subsequently, it applies the chosen method to complete the task. This dynamic strategy mirrors human meta-reasoning, allowing the model to excel in a wide range of problem domains. We evaluate the effectiveness of MRP through comprehensive benchmarks. The results demonstrate that MRP achieves or approaches state-of-the-art performance across diverse tasks. MRP represents a significant advancement in enabling LLMs to identify cognitive challenges across problems and leverage benefits across different reasoning approaches, enhancing their ability to handle diverse and complex problem domains efficiently. Every LLM deserves a Meta-Reasoning Prompting to unlock its full potential and ensure adaptability in an ever-evolving landscape of challenges and applications.
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
Apr 04, 2024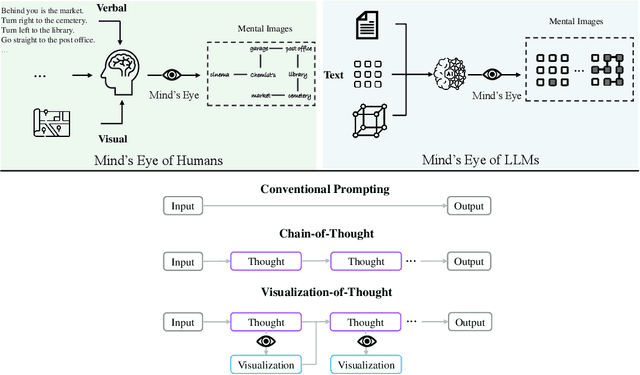
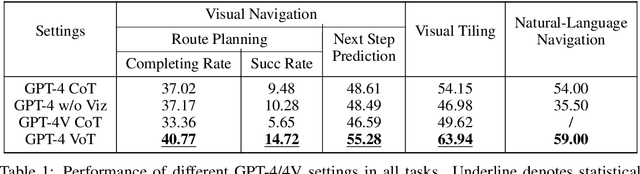
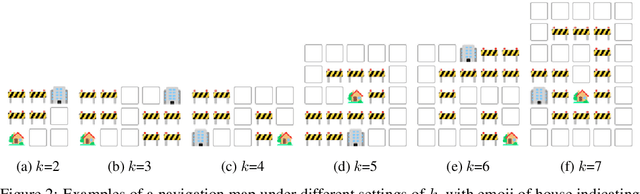
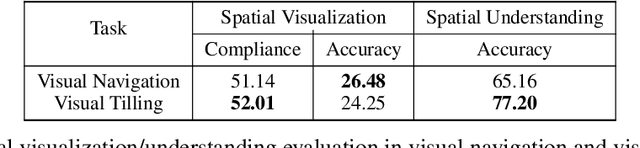
Large language models (LLMs) have exhibited impressive performance in language comprehension and various reasoning tasks. However, their abilities in spatial reasoning, a crucial aspect of human cognition, remain relatively unexplored. Human possess a remarkable ability to create mental images of unseen objects and actions through a process known as \textbf{the Mind's Eye}, enabling the imagination of the unseen world. Inspired by this cognitive capacity, we propose Visualization-of-Thought (\textbf{VoT}) prompting. VoT aims to elicit spatial reasoning of LLMs by visualizing their reasoning traces, thereby guiding subsequent reasoning steps. We employed VoT for multi-hop spatial reasoning tasks, including natural language navigation, visual navigation, and visual tiling in 2D grid worlds. Experimental results demonstrated that VoT significantly enhances the spatial reasoning abilities of LLMs. Notably, VoT outperformed existing multimodal large language models (MLLMs) in these tasks. While VoT works surprisingly well on LLMs, the ability to generate \textit{mental images} to facilitate spatial reasoning resembles the mind's eye process, suggesting its potential viability in MLLMs.