 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF2Real: Sim2real Transfer of Vision-guided Bipedal Motion Skills using Neural Radiance Fields
Oct 10, 2022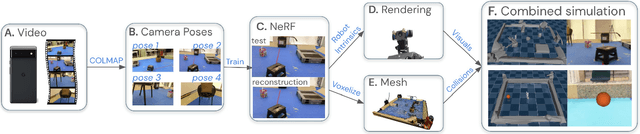
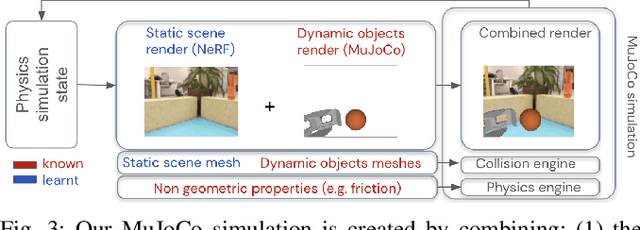
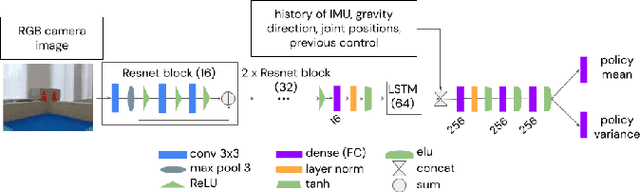

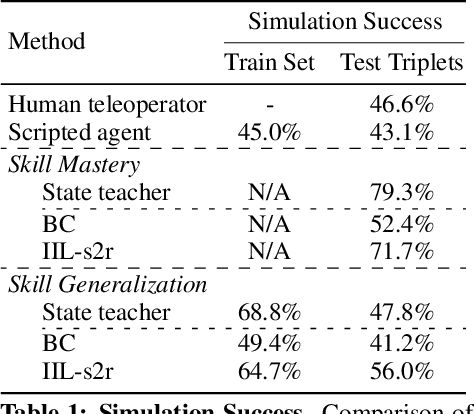
We present a system for applying sim2real approaches to "in the wild" scenes with realistic visuals, and to policies which rely on active perception using RGB cameras. Given a short video of a static scene collected using a generic phone, we learn the scene's contact geometry and a function for novel view synthesis using a Neural Radiance Field (NeRF). We augment the NeRF rendering of the static scene by overlaying the rendering of other dynamic objects (e.g. the robot's own body, a ball). A simulation is then created using the rendering engine in a physics simulator which computes contact dynamics from the static scene geometry (estimated from the NeRF volume density) and the dynamic objects' geometry and physical properties (assumed known). We demonstrate that we can use this simulation to learn vision-based whole body navigation and ball pushing policies for a 20 degrees of freedom humanoid robot with an actuated head-mounted RGB camera, and we successfully transfer these policies to a real robot. Project video is available at https://sites.google.com/view/nerf2real/home
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
iCub
May 07, 2021
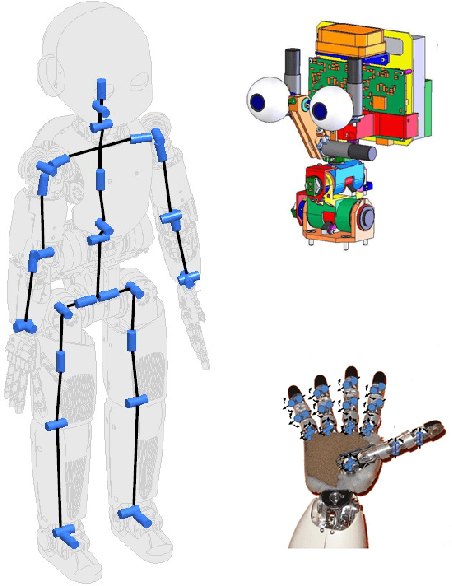


In this chapter we describe the history and evolution of the iCub humanoid platform. We start by describing the first version as it was designed during the RobotCub EU project and illustrate how it evolved to become the platform that is adopted by more than 30 laboratories world wide. We complete the chapter by illustrating some of the research activities that are currently carried out on the iCub robot, i.e. visual perception, event driven sensing and dynamic control. We conclude the Chapter with a discussion of the lessons we learned and a preview of the upcoming next release of the robot, iCub 3.0.
A Plenum-Based Calibration Device for Tactile Sensor Arrays
Mar 23, 2021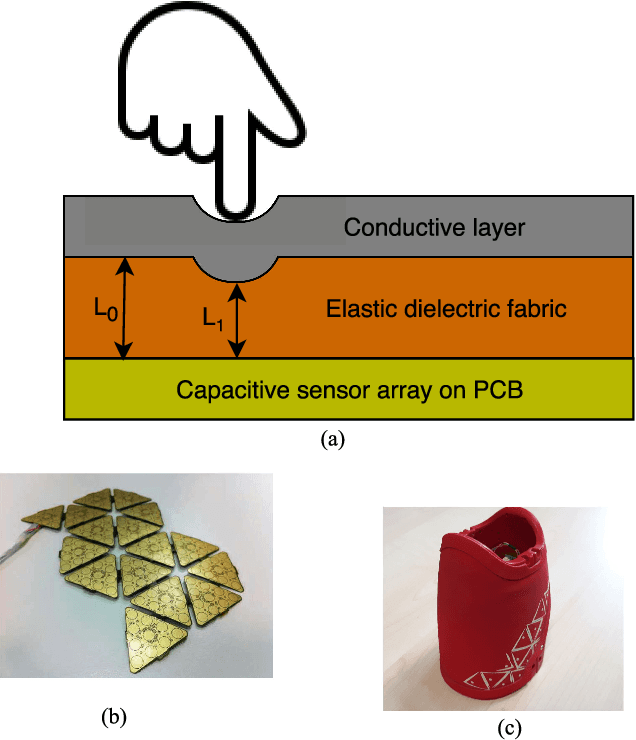
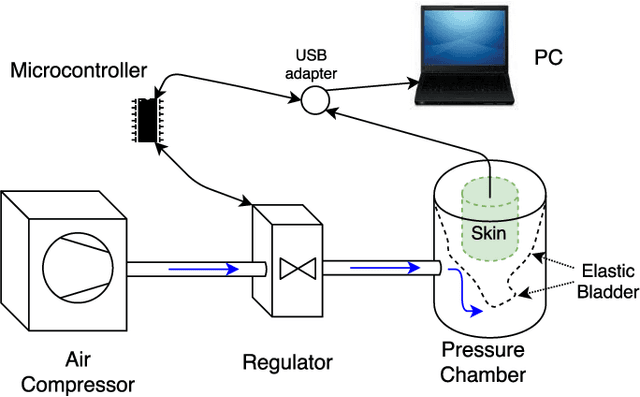
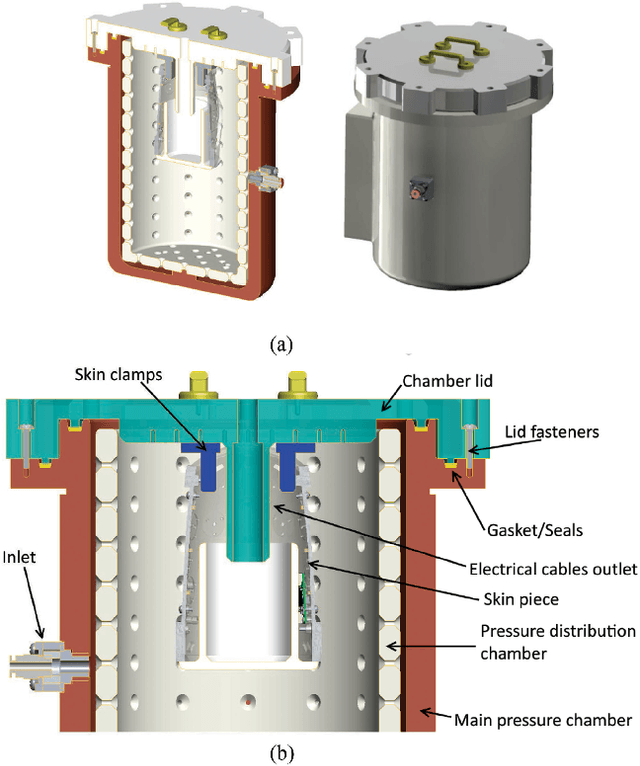
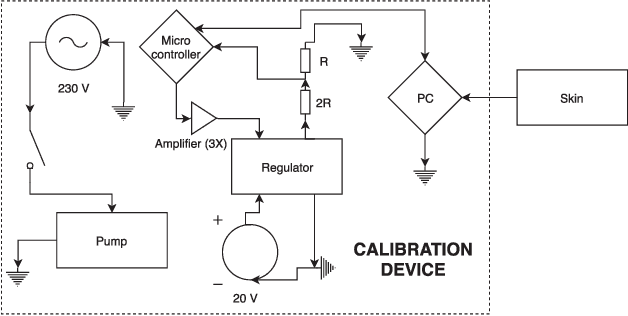
In modern robotic applications, tactile sensor arrays (i.e., artificial skins) are an emergent solution to determine the locations of contacts between a robot and an external agent. Localizing the point of contact is useful but determining the force applied on the skin provides many additional possibilities. This additional feature usually requires time-consuming calibration procedures to relate the sensor readings to the applied forces. This letter presents a novel device that enables the calibration of tactile sensor arrays in a fast and simple way. The key idea is to design a plenum chamber where the skin is inserted, and then the calibration of the tactile sensors is achieved by relating the air pressure and the sensor readings. This general concept is tested experimentally to calibrate the skin of the iCub robot. The validation of the calibration device is achieved by placing the masses of known weight on the artificial skin and comparing the applied force against the one estimated by the sensors.
* 8 pages, 18 figures
"What, not how": Solving an under-actuated insertion task from scratch
Oct 30, 2020

Robot manipulation requires a complex set of skills that need to be carefully combined and coordinated to solve a task. Yet, most ReinforcementLearning (RL) approaches in robotics study tasks which actually consist only of a single manipulation skill, such as grasping an object or inserting a pre-grasped object. As a result the skill ('how' to solve the task) but not the actual goal of a complete manipulation ('what' to solve) is specified. In contrast, we study a complex manipulation goal that requires an agent to learn and combine diverse manipulation skills. We propose a challenging, highly under-actuated peg-in-hole task with a free, rotational asymmetrical peg, requiring a broad range of manipulation skills. While correct peg (re-)orientation is a requirement for successful insertion, there is no reward associated with it. Hence an agent needs to understand this pre-condition and learn the skill to fulfil it. The final insertion reward is sparse, allowing freedom in the solution and leading to complex emerging behaviour not envisioned during the task design. We tackle the problem in a multi-task RL framework using Scheduled Auxiliary Control (SAC-X) combined with Regularized Hierarchical Policy Optimization (RHPO) which successfully solves the task in simulation and from scratch on a single robot where data is severely limited.
Learning Dexterous Manipulation from Suboptimal Experts
Oct 16, 2020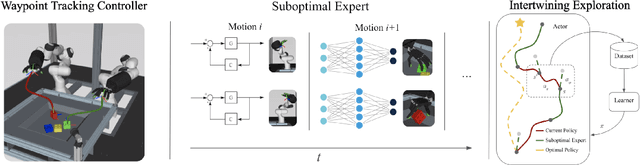
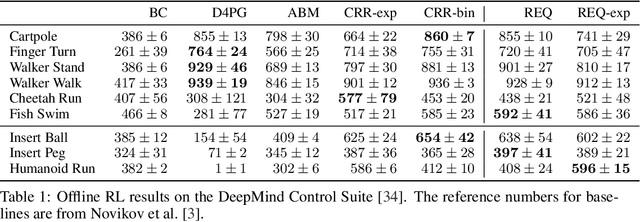

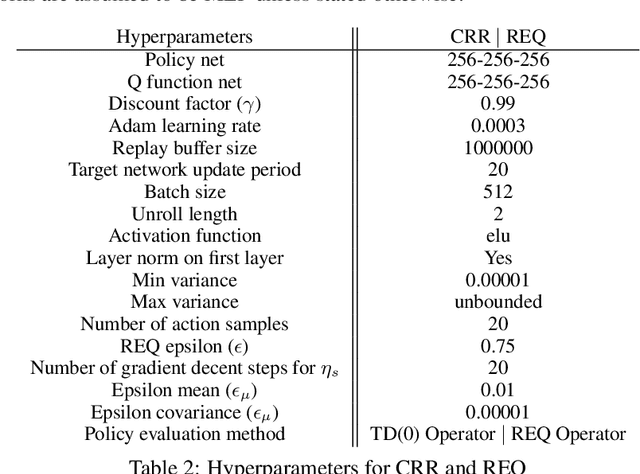
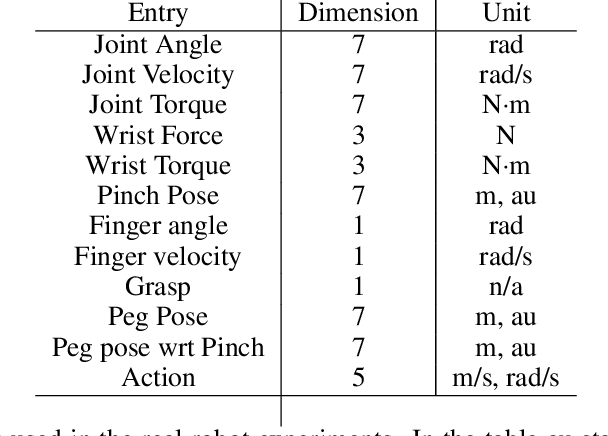
Learning dexterous manipulation in high-dimensional state-action spaces is an important open challenge with exploration presenting a major bottleneck. Although in many cases the learning process could be guided by demonstrations or other suboptimal experts, current RL algorithms for continuous action spaces often fail to effectively utilize combinations of highly off-policy expert data and on-policy exploration data. As a solution, we introduce Relative Entropy Q-Learning (REQ), a simple policy iteration algorithm that combines ideas from successful offline and conventional RL algorithms. It represents the optimal policy via importance sampling from a learned prior and is well-suited to take advantage of mixed data distributions. We demonstrate experimentally that REQ outperforms several strong baselines on robotic manipulation tasks for which suboptimal experts are available. We show how suboptimal experts can be constructed effectively by composing simple waypoint tracking controllers, and we also show how learned primitives can be combined with waypoint controllers to obtain reference behaviors to bootstrap a complex manipulation task on a simulated bimanual robot with human-like hands. Finally, we show that REQ is also effective for general off-policy RL, offline RL, and RL from demonstrations. Videos and further materials are available at sites.google.com/view/rlfse.
Modelling Generalized Forces with Reinforcement Learning for Sim-to-Real Transfer
Oct 21, 2019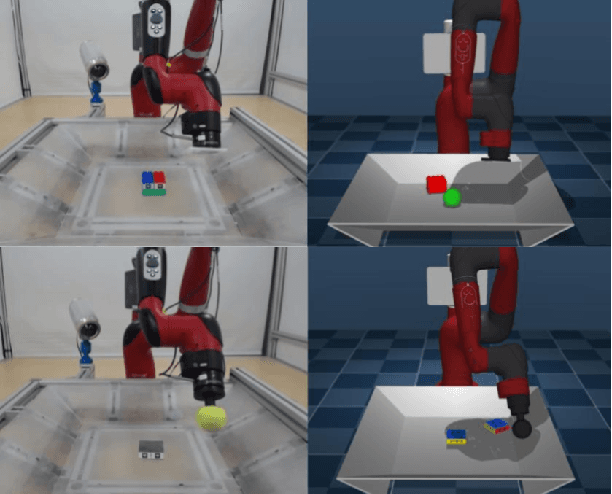
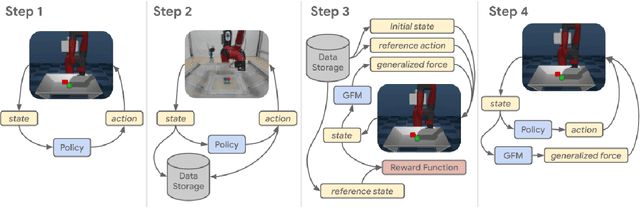
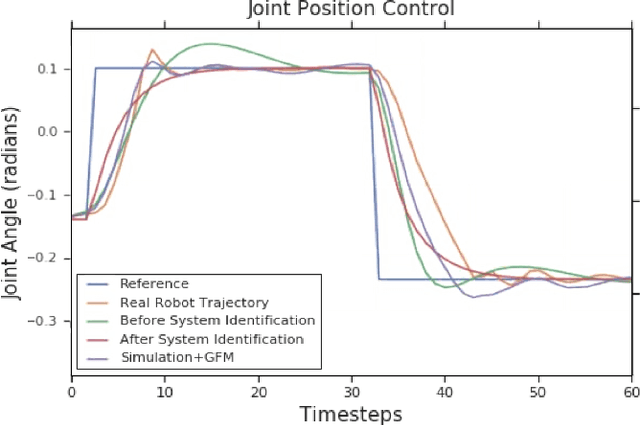

Learning robotic control policies in the real world gives rise to challenges in data efficiency, safety, and controlling the initial condition of the system. On the other hand, simulations are a useful alternative as they provide an abundant source of data without the restrictions of the real world. Unfortunately, simulations often fail to accurately model complex real-world phenomena. Traditional system identification techniques are limited in expressiveness by the analytical model parameters, and usually are not sufficient to capture such phenomena. In this paper we propose a general framework for improving the analytical model by optimizing state dependent generalized forces. State dependent generalized forces are expressive enough to model constraints in the equations of motion, while maintaining a clear physical meaning and intuition. We use reinforcement learning to efficiently optimize the mapping from states to generalized forces over a discounted infinite horizon. We show that using only minutes of real world data improves the sim-to-real control policy transfer. We demonstrate the feasibility of our approach by validating it on a nonprehensile manipulation task on the Sawyer robot.
Self-Supervised Sim-to-Real Adaptation for Visual Robotic Manipulation
Oct 21, 2019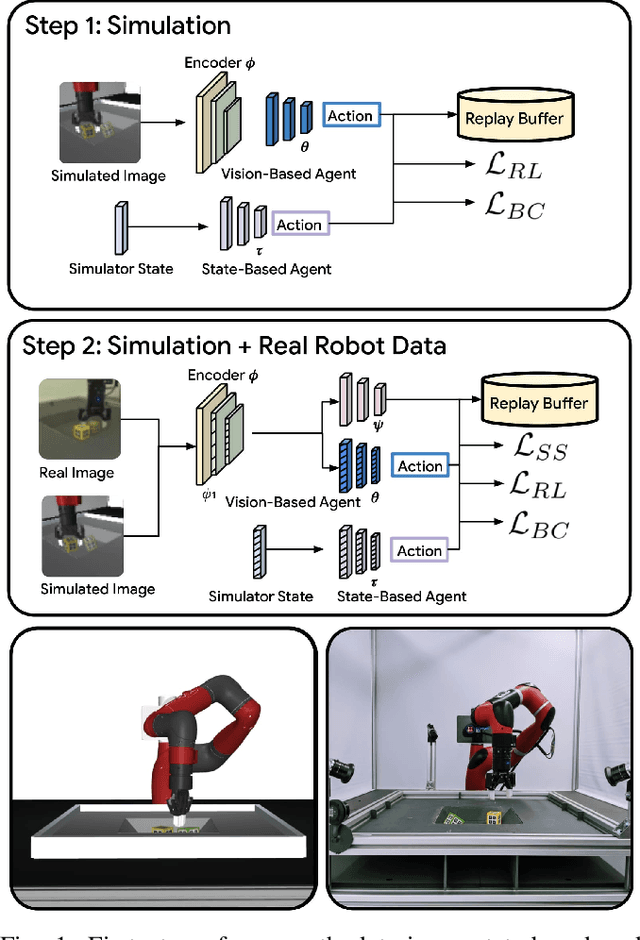

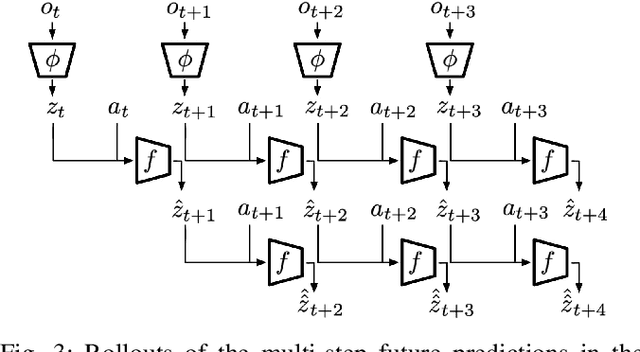
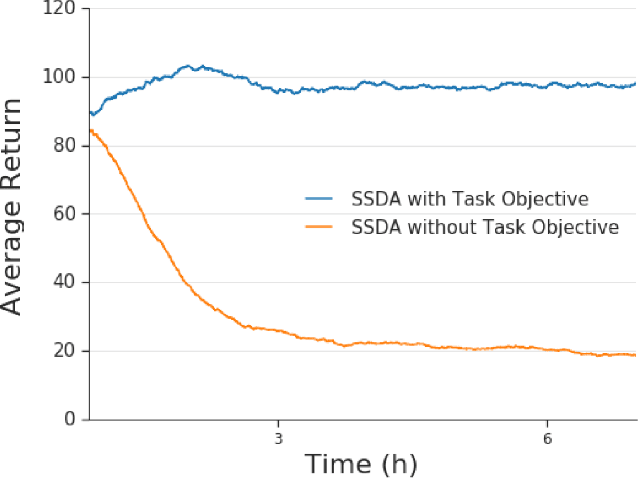
Collecting and automatically obtaining reward signals from real robotic visual data for the purposes of training reinforcement learning algorithms can be quite challenging and time-consuming. Methods for utilizing unlabeled data can have a huge potential to further accelerate robotic learning. We consider here the problem of performing manipulation tasks from pixels. In such tasks, choosing an appropriate state representation is crucial for planning and control. This is even more relevant with real images where noise, occlusions and resolution affect the accuracy and reliability of state estimation. In this work, we learn a latent state representation implicitly with deep reinforcement learning in simulation, and then adapt it to the real domain using unlabeled real robot data. We propose to do so by optimizing sequence-based self supervised objectives. These exploit the temporal nature of robot experience, and can be common in both the simulated and real domains, without assuming any alignment of underlying states in simulated and unlabeled real images. We propose Contrastive Forward Dynamics loss, which combines dynamics model learning with time-contrastive techniques. The learned state representation that results from our methods can be used to robustly solve a manipulation task in simulation and to successfully transfer the learned skill on a real system. We demonstrate the effectiveness of our approaches by training a vision-based reinforcement learning agent for cube stacking. Agents trained with our method, using only 5 hours of unlabeled real robot data for adaptation, shows a clear improvement over domain randomization, and standard visual domain adaptation techniques for sim-to-real transfer.
Momentum-Based Topology Estimation of Articulated Objects
Mar 20, 2019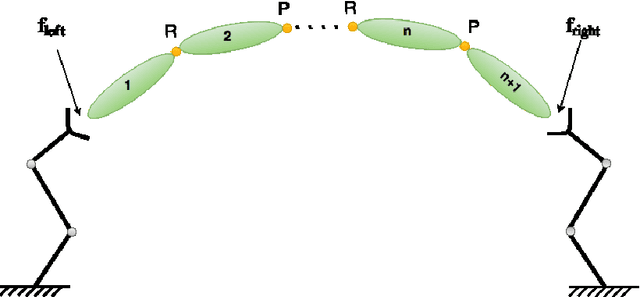
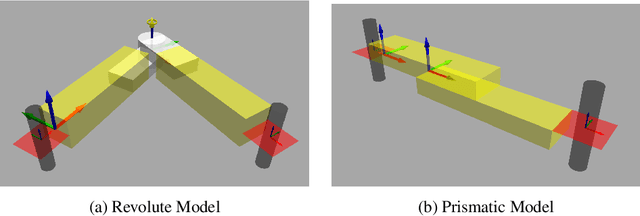

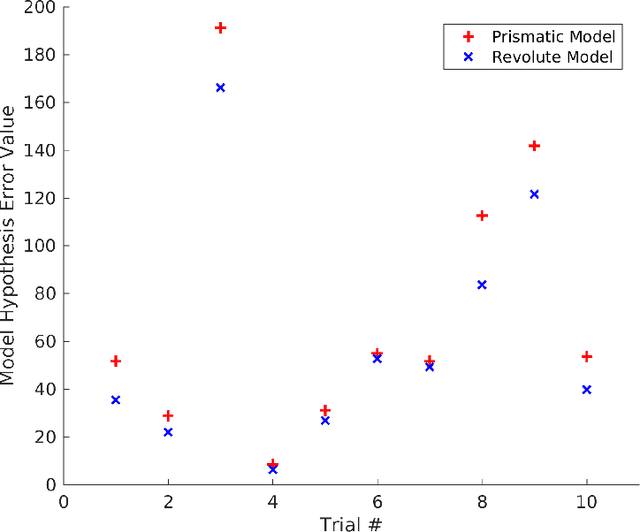
Articulated objects like doors, drawers, valves, and tools are pervasive in our everyday unstructured dynamic environments. Articulation models describe the joint nature between the different parts of an articulated object. As most of these objects are passive, a robot has to interact with them to infer all the articulation models to understand the object topology. We present a general algorithm to estimate the inherent articulation models by exploiting the momentum of the articulated system along with the interaction wrench while manipulating the object. We validate our approach with experiments in a simulation environment.
Towards Partner-Aware Humanoid Robot Control Under Physical Interactions
Mar 20, 2019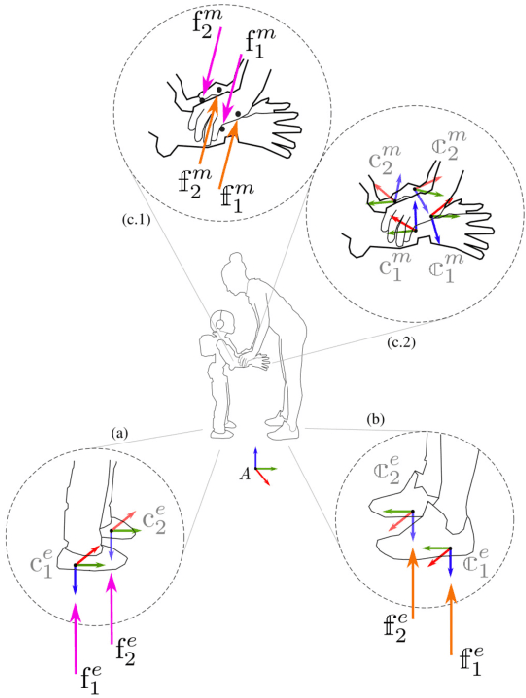

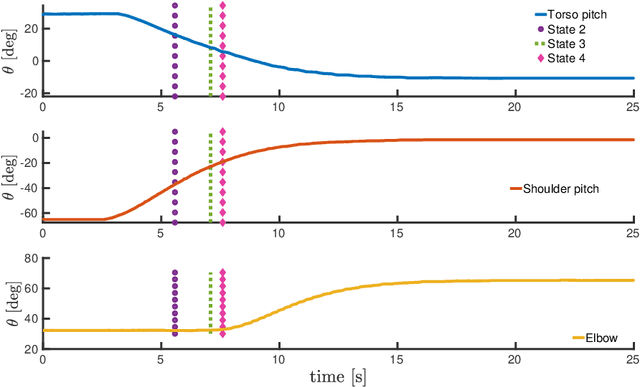
The topic of physical human-robot interaction received a lot of attention from the robotics community because of many promising application domains. However, studying physical interaction between a robot and an external agent, like a human or another robot, without considering the dynamics of both the systems may lead to many short-comings in fully exploiting the interaction. In this paper, we present a coupled-dynamics formalism followed by a sound approach in exploiting helpful interaction with a humanoid robot. In particular, we propose the first attempt to define and exploit the human help for the robot to accomplish a specific task. As a result, we present a task-based partner-aware robot control techniques. The theoretical results are validated by conducting experiments with two iCub humanoid robots involved in physical interaction.