 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRAD: Zero-Shot Anomaly Detection with Memory-Driven Retrieval
Jan 31, 2026Zero-shot anomaly detection (ZSAD) often leverages pretrained vision or vision-language models, but many existing methods use prompt learning or complex modeling to fit the data distribution, resulting in high training or inference cost and limited cross-domain stability. To address these limitations, we propose Memory-Retrieval Anomaly Detection method (MRAD), a unified framework that replaces parametric fitting with a direct memory retrieval. The train-free base model, MRAD-TF, freezes the CLIP image encoder and constructs a two-level memory bank (image-level and pixel-level) from auxiliary data, where feature-label pairs are explicitly stored as keys and values. During inference, anomaly scores are obtained directly by similarity retrieval over the memory bank. Based on the MRAD-TF, we further propose two lightweight variants as enhancements: (i) MRAD-FT fine-tunes the retrieval metric with two linear layers to enhance the discriminability between normal and anomaly; (ii) MRAD-CLIP injects the normal and anomalous region priors from the MRAD-FT as dynamic biases into CLIP's learnable text prompts, strengthening generalization to unseen categories. Across 16 industrial and medical datasets, the MRAD framework consistently demonstrates superior performance in anomaly classification and segmentation, under both train-free and training-based settings. Our work shows that fully leveraging the empirical distribution of raw data, rather than relying only on model fitting, can achieve stronger anomaly detection performance. The code will be publicly released at https://github.com/CROVO1026/MRAD.
UserLM-R1: Modeling Human Reasoning in User Language Models with Multi-Reward Reinforcement Learning
Jan 14, 2026User simulators serve as the critical interactive environment for agent post-training, and an ideal user simulator generalizes across domains and proactively engages in negotiation by challenging or bargaining. However, current methods exhibit two issues. They rely on static and context-unaware profiles, necessitating extensive manual redesign for new scenarios, thus limiting generalizability. Moreover, they neglect human strategic thinking, leading to vulnerability to agent manipulation. To address these issues, we propose UserLM-R1, a novel user language model with reasoning capability. Specifically, we first construct comprehensive user profiles with both static roles and dynamic scenario-specific goals for adaptation to diverse scenarios. Then, we propose a goal-driven decision-making policy to generate high-quality rationales before producing responses, and further refine the reasoning and improve strategic capabilities with supervised fine-tuning and multi-reward reinforcement learning. Extensive experimental results demonstrate that UserLM-R1 outperforms competitive baselines, particularly on the more challenging adversarial set.
Efficient Paths and Dense Rewards: Probabilistic Flow Reasoning for Large Language Models
Jan 14, 2026High-quality chain-of-thought has demonstrated strong potential for unlocking the reasoning capabilities of large language models. However, current paradigms typically treat the reasoning process as an indivisible sequence, lacking an intrinsic mechanism to quantify step-wise information gain. This granularity gap manifests in two limitations: inference inefficiency from redundant exploration without explicit guidance, and optimization difficulty due to sparse outcome supervision or costly external verifiers. In this work, we propose CoT-Flow, a framework that reconceptualizes discrete reasoning steps as a continuous probabilistic flow, quantifying the contribution of each step toward the ground-truth answer. Built on this formulation, CoT-Flow enables two complementary methodologies: flow-guided decoding, which employs a greedy flow-based decoding strategy to extract information-efficient reasoning paths, and flow-based reinforcement learning, which constructs a verifier-free dense reward function. Experiments on challenging benchmarks demonstrate that CoT-Flow achieves a superior balance between inference efficiency and reasoning performance.
SHIELD: Spherical-Projection Hybrid-Frontier Integration for Efficient LiDAR-based Drone Exploration
Dec 30, 2025This paper introduces SHIELD, a Spherical-Projection Hybrid-Frontier Integration for Efficient LiDAR-based Drone exploration method. Although laser LiDAR offers the advantage of a wide field of view, its application in UAV exploration still faces several challenges. The observation quality of LiDAR point clouds is generally inferior to that of depth cameras. Traditional frontier methods based on known and unknown regions impose a heavy computational burden, especially when handling the wide field of view of LiDAR. In addition, regions without point cloud are also difficult to classify as free space through raycasting. To address these problems, the SHIELD is proposed. It maintains an observation-quality occupancy map and performs ray-casting on this map to address the issue of inconsistent point-cloud quality during exploration. A hybrid frontier method is used to tackle both the computational burden and the limitations of point-cloud quality exploration. In addition, an outward spherical-projection ray-casting strategy is proposed to jointly ensure flight safety and exploration efficiency in open areas. Simulations and flight experiments prove the effectiveness of SHIELD. This work will be open-sourced to contribute to the research community.
ADHint: Adaptive Hints with Difficulty Priors for Reinforcement Learning
Dec 15, 2025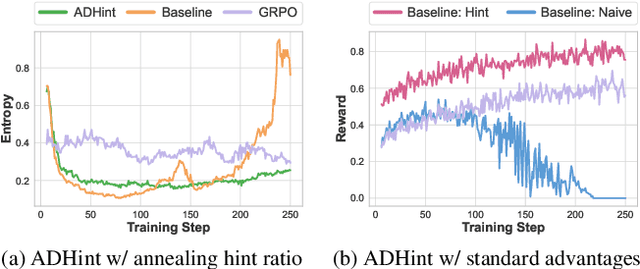
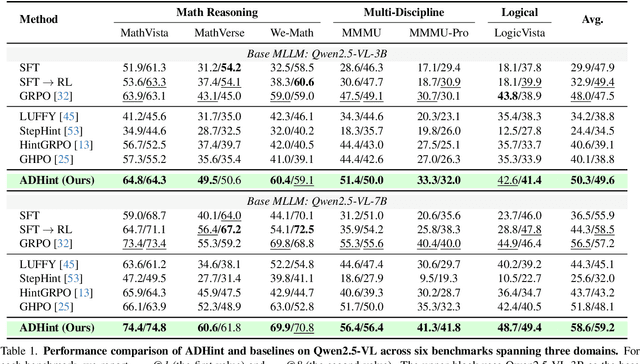
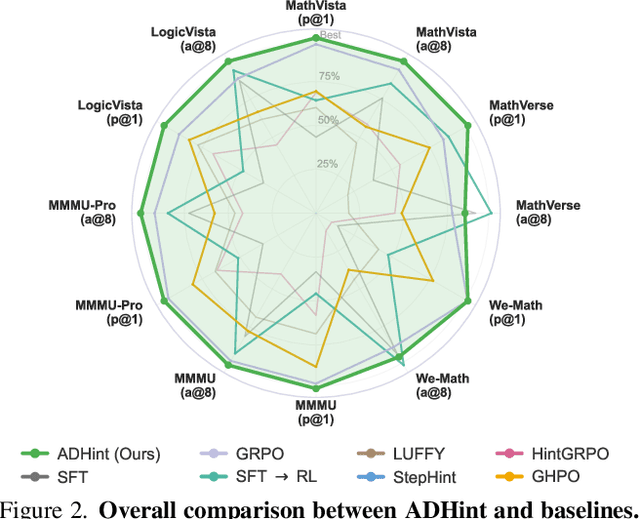
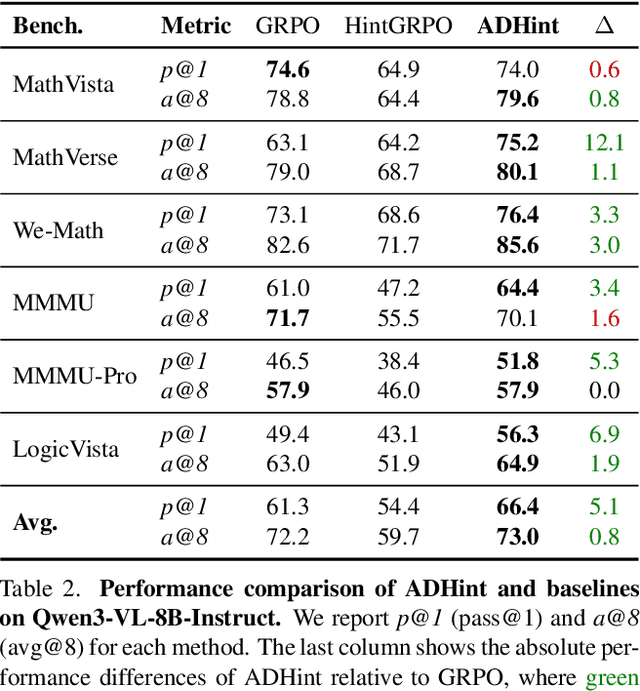
To combine the advantages of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), recent methods have integrated ''hints'' into post-training, which are prefix segments of complete reasoning trajectories, aiming for powerful knowledge expansion and reasoning generalization. However, existing hint-based RL methods typically ignore difficulty when scheduling hint ratios and estimating relative advantages, leading to unstable learning and excessive imitation of off-policy hints. In this work, we propose ADHint, which treats difficulty as a key factor in both hint-ratio schedule and relative-advantage estimation to achieve a better trade-off between exploration and imitation. Specifically, we propose Adaptive Hint with Sample Difficulty Prior, which evaluates each sample's difficulty under the policy model and accordingly schedules an appropriate hint ratio to guide its rollouts. We also introduce Consistency-based Gradient Modulation and Selective Masking for Hint Preservation to modulate token-level gradients within hints, preventing biased and destructive updates. Additionally, we propose Advantage Estimation with Rollout Difficulty Posterior, which leverages the relative difficulty of rollouts with and without hints to estimate their respective advantages, thereby achieving more balanced updates. Extensive experiments across diverse modalities, model scales, and domains demonstrate that ADHint delivers superior reasoning ability and out-of-distribution generalization, consistently surpassing existing methods in both pass@1 and avg@8. Our code and dataset will be made publicly available upon paper acceptance.
Hybrid Attribution Priors for Explainable and Robust Model Training
Dec 09, 2025Small language models (SLMs) are widely used in tasks that require low latency and lightweight deployment, particularly classification. As interpretability and robustness gain increasing importance, explanation-guided learning has emerged as an effective framework by introducing attribution-based supervision during training; however, deriving general and reliable attribution priors remains a significant challenge. Through an analysis of representative attribution methods in classification settings, we find that although these methods can reliably highlight class-relevant tokens, they often focus on common keywords shared by semantically similar classes. Because such classes are already difficult to distinguish under standard training, these attributions provide insufficient discriminative cues, limiting their ability to improve model differentiation. To overcome this limitation, we propose Class-Aware Attribution Prior (CAP), a novel attribution prior extraction framework that guides language models toward capturing fine-grained class distinctions and producing more salient, discriminative attribution priors. Building on this idea, we further introduce CAP Hybrid, which combines priors from CAP with those from existing attribution techniques to form a more comprehensive and balanced supervisory signal. By aligning a model's self-attribution with these enriched priors, our approach encourages the learning of diverse, decision-relevant features. Extensive experiments in full-data, few-shot, and adversarial scenarios demonstrate that our method consistently enhances both interpretability and robustness.
Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025



Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
Chain-of-Thought Re-ranking for Image Retrieval Tasks
Sep 18, 2025



Image retrieval remains a fundamental yet challenging problem in computer vision. While recent advances in Multimodal Large Language Models (MLLMs) have demonstrated strong reasoning capabilities, existing methods typically employ them only for evaluation, without involving them directly in the ranking process. As a result, their rich multimodal reasoning abilities remain underutilized, leading to suboptimal performance. In this paper, we propose a novel Chain-of-Thought Re-Ranking (CoTRR) method to address this issue. Specifically, we design a listwise ranking prompt that enables MLLM to directly participate in re-ranking candidate images. This ranking process is grounded in an image evaluation prompt, which assesses how well each candidate aligns with users query. By allowing MLLM to perform listwise reasoning, our method supports global comparison, consistent reasoning, and interpretable decision-making - all of which are essential for accurate image retrieval. To enable structured and fine-grained analysis, we further introduce a query deconstruction prompt, which breaks down the original query into multiple semantic components. Extensive experiments on five datasets demonstrate the effectiveness of our CoTRR method, which achieves state-of-the-art performance across three image retrieval tasks, including text-to-image retrieval (TIR), composed image retrieval (CIR) and chat-based image retrieval (Chat-IR). Our code is available at https://github.com/freshfish15/CoTRR .
Cross-Layer Vision Smoothing: Enhancing Visual Understanding via Sustained Focus on Key Objects in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) can accurately locate key objects in images, yet their attention to these objects tends to be very brief. Motivated by the hypothesis that sustained focus on key objects can improve LVLMs' visual capabilities, we propose Cross-Layer Vision Smoothing (CLVS). The core idea of CLVS is to incorporate a vision memory that smooths the attention distribution across layers. Specifically, we initialize this vision memory with position-unbiased visual attention in the first layer. In subsequent layers, the model's visual attention jointly considers the vision memory from previous layers, while the memory is updated iteratively, thereby maintaining smooth attention on key objects. Given that visual understanding primarily occurs in the early and middle layers of the model, we use uncertainty as an indicator of completed visual understanding and terminate the smoothing process accordingly. Experiments on four benchmarks across three LVLMs confirm the effectiveness and generalizability of our method. CLVS achieves state-of-the-art performance on a variety of visual understanding tasks, with particularly significant improvements in relation and attribute understanding.
Learning Unpaired Image Dehazing with Physics-based Rehazy Generation
Jun 15, 2025



Overfitting to synthetic training pairs remains a critical challenge in image dehazing, leading to poor generalization capability to real-world scenarios. To address this issue, existing approaches utilize unpaired realistic data for training, employing CycleGAN or contrastive learning frameworks. Despite their progress, these methods often suffer from training instability, resulting in limited dehazing performance. In this paper, we propose a novel training strategy for unpaired image dehazing, termed Rehazy, to improve both dehazing performance and training stability. This strategy explores the consistency of the underlying clean images across hazy images and utilizes hazy-rehazy pairs for effective learning of real haze characteristics. To favorably construct hazy-rehazy pairs, we develop a physics-based rehazy generation pipeline, which is theoretically validated to reliably produce high-quality rehazy images. Additionally, leveraging the rehazy strategy, we introduce a dual-branch framework for dehazing network training, where a clean branch provides a basic dehazing capability in a synthetic manner, and a hazy branch enhances the generalization ability with hazy-rehazy pairs. Moreover, we design a new dehazing network within these branches to improve the efficiency, which progressively restores clean scenes from coarse to fine. Extensive experiments on four benchmarks demonstrate the superior performance of our approach, exceeding the previous state-of-the-art methods by 3.58 dB on the SOTS-Indoor dataset and by 1.85 dB on the SOTS-Outdoor dataset in PSNR. Our code will be publicly available.