 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Low-light Enhancement and Deblurring for 3D Dark Scenes
Mar 09, 2026Novel view synthesis from low-light, noisy, and motion-blurred imagery remains a valuable and challenging task. Current volumetric rendering methods struggle with compound degradation, and sequential 2D preprocessing introduces artifacts due to interdependencies. In this work, we introduce FLED-GS, a fast low-light enhancement and deblurring framework that reformulates 3D scene restoration as an alternating cycle of enhancement and reconstruction. Specifically, FLED-GS inserts several intermediate brightness anchors to enable progressive recovery, preventing noise blow-up from harming deblurring or geometry. Each iteration sharpens inputs with an off-the-shelf 2D deblurrer and then performs noise-aware 3DGS reconstruction that estimates and suppresses noise while producing clean priors for the next level. Experiments show FLED-GS outperforms state-of-the-art LuSh-NeRF, achieving 21$\times$ faster training and 11$\times$ faster rendering.
Chain-of-Thought Re-ranking for Image Retrieval Tasks
Sep 18, 2025



Image retrieval remains a fundamental yet challenging problem in computer vision. While recent advances in Multimodal Large Language Models (MLLMs) have demonstrated strong reasoning capabilities, existing methods typically employ them only for evaluation, without involving them directly in the ranking process. As a result, their rich multimodal reasoning abilities remain underutilized, leading to suboptimal performance. In this paper, we propose a novel Chain-of-Thought Re-Ranking (CoTRR) method to address this issue. Specifically, we design a listwise ranking prompt that enables MLLM to directly participate in re-ranking candidate images. This ranking process is grounded in an image evaluation prompt, which assesses how well each candidate aligns with users query. By allowing MLLM to perform listwise reasoning, our method supports global comparison, consistent reasoning, and interpretable decision-making - all of which are essential for accurate image retrieval. To enable structured and fine-grained analysis, we further introduce a query deconstruction prompt, which breaks down the original query into multiple semantic components. Extensive experiments on five datasets demonstrate the effectiveness of our CoTRR method, which achieves state-of-the-art performance across three image retrieval tasks, including text-to-image retrieval (TIR), composed image retrieval (CIR) and chat-based image retrieval (Chat-IR). Our code is available at https://github.com/freshfish15/CoTRR .
KTPFormer: Kinematics and Trajectory Prior Knowledge-Enhanced Transformer for 3D Human Pose Estimation
Apr 02, 2024This paper presents a novel Kinematics and Trajectory Prior Knowledge-Enhanced Transformer (KTPFormer), which overcomes the weakness in existing transformer-based methods for 3D human pose estimation that the derivation of Q, K, V vectors in their self-attention mechanisms are all based on simple linear mapping. We propose two prior attention modules, namely Kinematics Prior Attention (KPA) and Trajectory Prior Attention (TPA) to take advantage of the known anatomical structure of the human body and motion trajectory information, to facilitate effective learning of global dependencies and features in the multi-head self-attention. KPA models kinematic relationships in the human body by constructing a topology of kinematics, while TPA builds a trajectory topology to learn the information of joint motion trajectory across frames. Yielding Q, K, V vectors with prior knowledge, the two modules enable KTPFormer to model both spatial and temporal correlations simultaneously. Extensive experiments on three benchmarks (Human3.6M, MPI-INF-3DHP and HumanEva) show that KTPFormer achieves superior performance in comparison to state-of-the-art methods. More importantly, our KPA and TPA modules have lightweight plug-and-play designs and can be integrated into various transformer-based networks (i.e., diffusion-based) to improve the performance with only a very small increase in the computational overhead. The code is available at: https://github.com/JihuaPeng/KTPFormer.
SGDiff: A Style Guided Diffusion Model for Fashion Synthesis
Aug 15, 2023



This paper reports on the development of \textbf{a novel style guided diffusion model (SGDiff)} which overcomes certain weaknesses inherent in existing models for image synthesis. The proposed SGDiff combines image modality with a pretrained text-to-image diffusion model to facilitate creative fashion image synthesis. It addresses the limitations of text-to-image diffusion models by incorporating supplementary style guidance, substantially reducing training costs, and overcoming the difficulties of controlling synthesized styles with text-only inputs. This paper also introduces a new dataset -- SG-Fashion, specifically designed for fashion image synthesis applications, offering high-resolution images and an extensive range of garment categories. By means of comprehensive ablation study, we examine the application of classifier-free guidance to a variety of conditions and validate the effectiveness of the proposed model for generating fashion images of the desired categories, product attributes, and styles. The contributions of this paper include a novel classifier-free guidance method for multi-modal feature fusion, a comprehensive dataset for fashion image synthesis application, a thorough investigation on conditioned text-to-image synthesis, and valuable insights for future research in the text-to-image synthesis domain. The code and dataset are available at: \url{https://github.com/taited/SGDiff}.
Modeling Field-level Factor Interactions for Fashion Recommendation
Apr 08, 2022
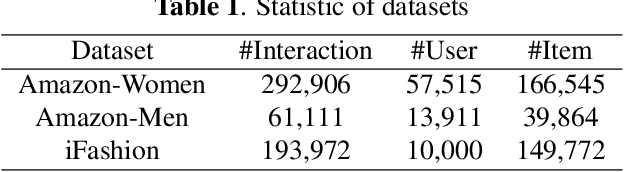
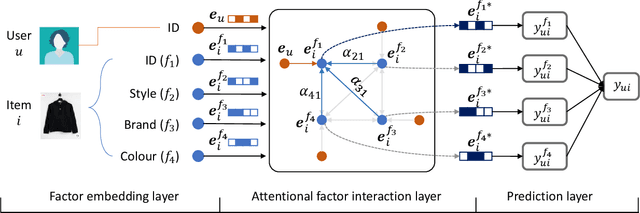
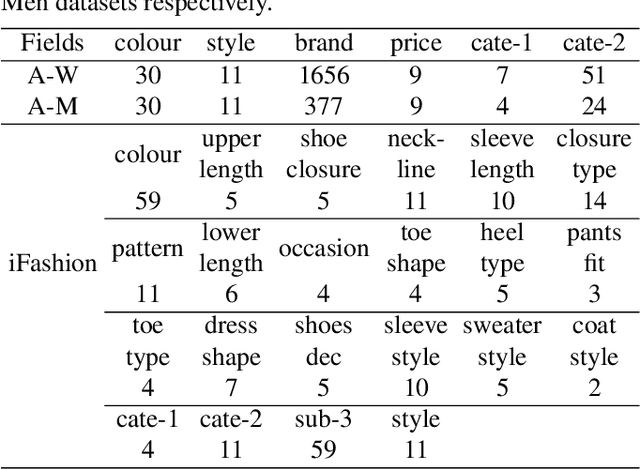
Personalized fashion recommendation aims to explore patterns from historical interactions between users and fashion items and thereby predict the future ones. It is challenging due to the sparsity of the interaction data and the diversity of user preference in fashion. To tackle the challenge, this paper investigates multiple factor fields in fashion domain, such as colour, style, brand, and tries to specify the implicit user-item interaction into field level. Specifically, an attentional factor field interaction graph (AFFIG) approach is proposed which models both the user-factor interactions and cross-field factors interactions for predicting the recommendation probability at specific field. In addition, an attention mechanism is equipped to aggregate the cross-field factor interactions for each field. Extensive experiments have been conducted on three E-Commerce fashion datasets and the results demonstrate the effectiveness of the proposed method for fashion recommendation. The influence of various factor fields on recommendation in fashion domain is also discussed through experiments.