 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Feb 15, 2026As industrial recommender systems enter a scaling-driven regime, Transformer architectures have become increasingly attractive for scaling models towards larger capacity and longer sequence. However, existing Transformer-based recommendation models remain structurally fragmented, where sequence modeling and feature interaction are implemented as separate modules with independent parameterization. Such designs introduce a fundamental co-scaling challenge, as model capacity must be suboptimally allocated between dense feature interaction and sequence modeling under a limited computational budget. In this work, we propose MixFormer, a unified Transformer-style architecture tailored for recommender systems, which jointly models sequential behaviors and feature interactions within a single backbone. Through a unified parameterization, MixFormer enables effective co-scaling across both dense capacity and sequence length, mitigating the trade-off observed in decoupled designs. Moreover, the integrated architecture facilitates deep interaction between sequential and non-sequential representations, allowing high-order feature semantics to directly inform sequence aggregation and enhancing overall expressiveness. To ensure industrial practicality, we further introduce a user-item decoupling strategy for efficiency optimizations that significantly reduce redundant computation and inference latency. Extensive experiments on large-scale industrial datasets demonstrate that MixFormer consistently exhibits superior accuracy and efficiency. Furthermore, large-scale online A/B tests on two production recommender systems, Douyin and Douyin Lite, show consistent improvements in user engagement metrics, including active days and in-app usage duration.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025



Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
Modeling Users' Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
Mar 29, 2022

Modeling user's historical feedback is essential for Click-Through Rate Prediction in personalized search and recommendation. Existing methods usually only model users' positive feedback information such as click sequences which neglects the context information of the feedback. In this paper, we propose a new perspective for context-aware users' behavior modeling by including the whole page-wisely exposed products and the corresponding feedback as contextualized page-wise feedback sequence. The intra-page context information and inter-page interest evolution can be captured to learn more specific user preference. We design a novel neural ranking model RACP(i.e., Recurrent Attention over Contextualized Page sequence), which utilizes page-context aware attention to model the intra-page context. A recurrent attention process is used to model the cross-page interest convergence evolution as denoising the interest in the previous pages. Experiments on public and real-world industrial datasets verify our model's effectiveness.
Grid Tagging Scheme for Aspect-oriented Fine-grained Opinion Extraction
Oct 09, 2020

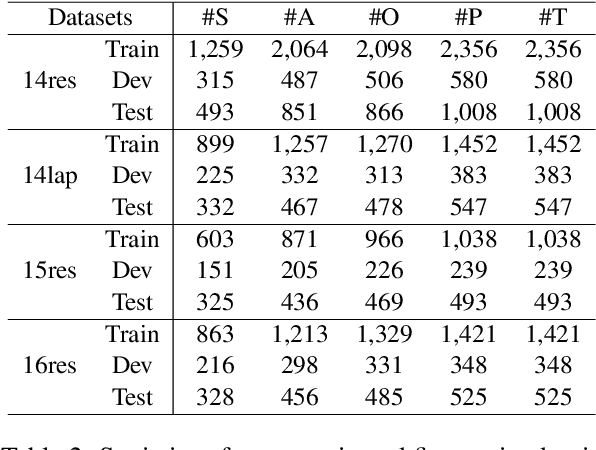
Aspect-oriented Fine-grained Opinion Extraction (AFOE) aims at extracting aspect terms and opinion terms from review in the form of opinion pairs or additionally extracting sentiment polarity of aspect term to form opinion triplet. Because of containing several opinion factors, the complete AFOE task is usually divided into multiple subtasks and achieved in the pipeline. However, pipeline approaches easily suffer from error propagation and inconvenience in real-world scenarios. To this end, we propose a novel tagging scheme, Grid Tagging Scheme (GTS), to address the AFOE task in an end-to-end fashion only with one unified grid tagging task. Additionally, we design an effective inference strategy on GTS to exploit mutual indication between different opinion factors for more accurate extractions. To validate the feasibility and compatibility of GTS, we implement three different GTS models respectively based on CNN, BiLSTM, and BERT, and conduct experiments on the aspect-oriented opinion pair extraction and opinion triplet extraction datasets. Extensive experimental results indicate that GTS models outperform strong baselines significantly and achieve state-of-the-art performance.