 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
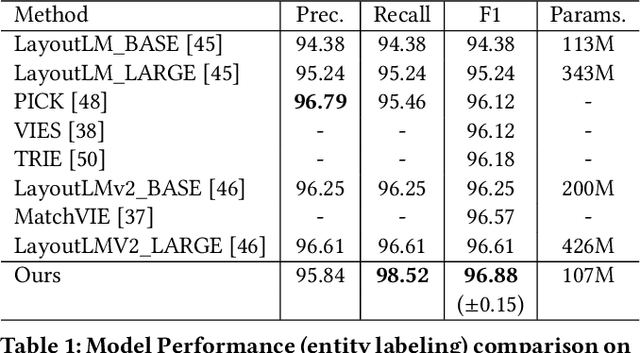
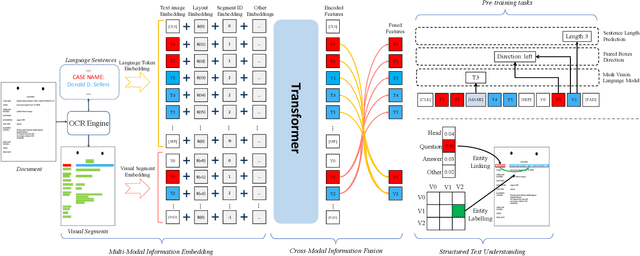
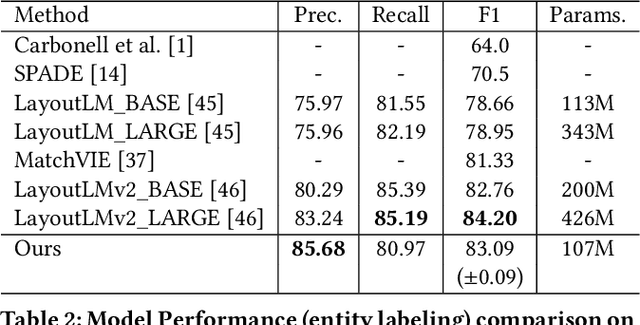
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
Weakly-Supervised Spatio-Temporal Anomaly Detection in Surveillance Video
Aug 09, 2021
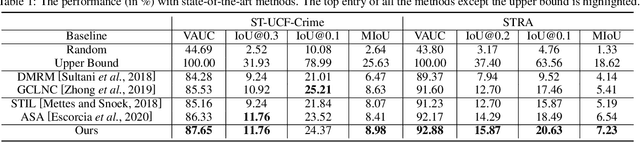
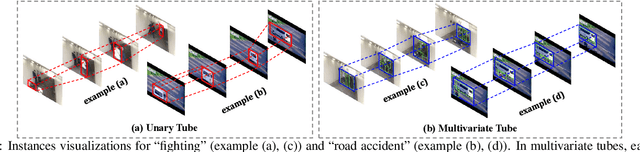
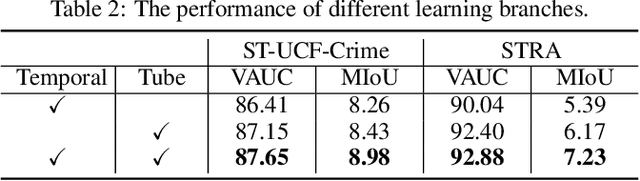
In this paper, we introduce a novel task, referred to as Weakly-Supervised Spatio-Temporal Anomaly Detection (WSSTAD) in surveillance video. Specifically, given an untrimmed video, WSSTAD aims to localize a spatio-temporal tube (i.e., a sequence of bounding boxes at consecutive times) that encloses the abnormal event, with only coarse video-level annotations as supervision during training. To address this challenging task, we propose a dual-branch network which takes as input the proposals with multi-granularities in both spatial-temporal domains. Each branch employs a relationship reasoning module to capture the correlation between tubes/videolets, which can provide rich contextual information and complex entity relationships for the concept learning of abnormal behaviors. Mutually-guided Progressive Refinement framework is set up to employ dual-path mutual guidance in a recurrent manner, iteratively sharing auxiliary supervision information across branches. It impels the learned concepts of each branch to serve as a guide for its counterpart, which progressively refines the corresponding branch and the whole framework. Furthermore, we contribute two datasets, i.e., ST-UCF-Crime and STRA, consisting of videos containing spatio-temporal abnormal annotations to serve as the benchmarks for WSSTAD. We conduct extensive qualitative and quantitative evaluations to demonstrate the effectiveness of the proposed approach and analyze the key factors that contribute more to handle this task.
Oriented Object Detection with Transformer
Jun 06, 2021
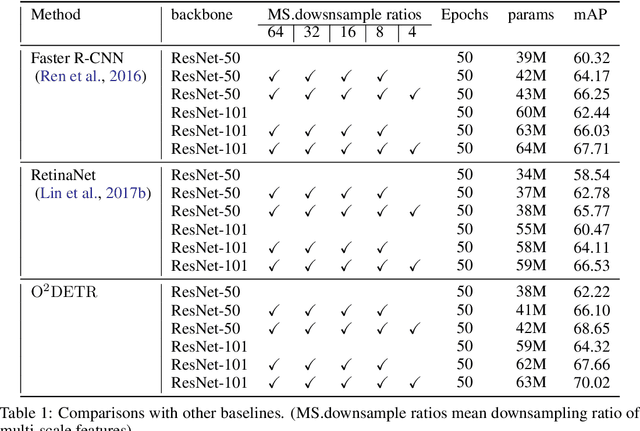
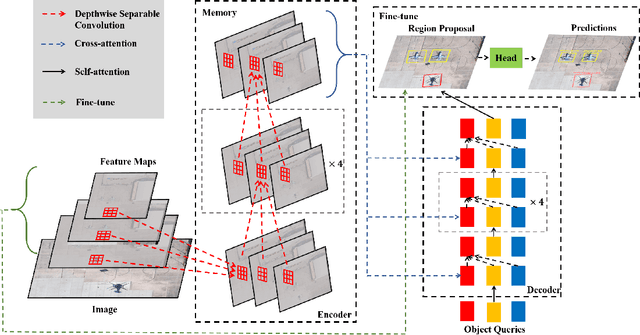
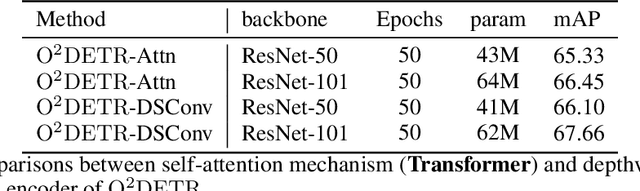
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021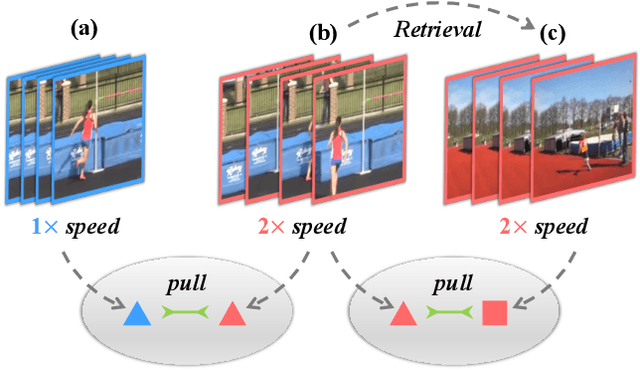

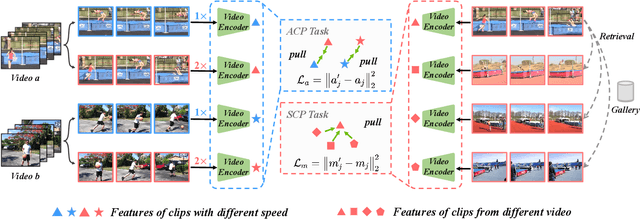
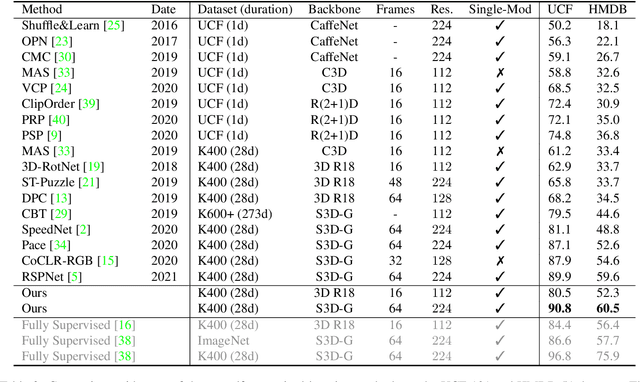
We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.
Dual-stream Network for Visual Recognition
May 31, 2021
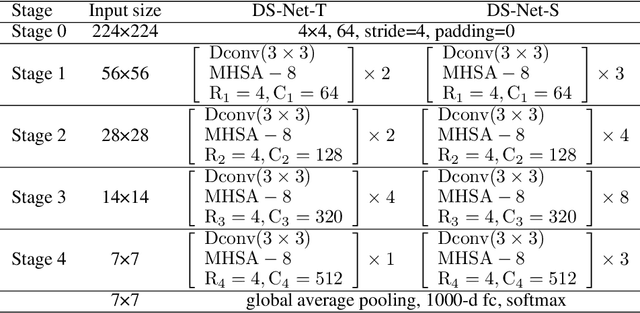
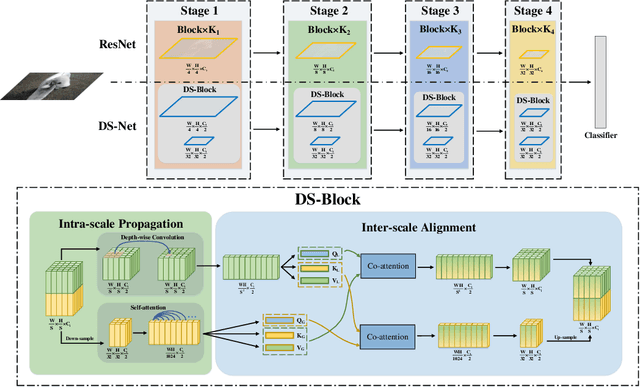
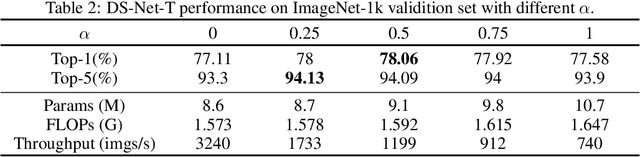
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.
Dynamic Class Queue for Large Scale Face Recognition In the Wild
May 24, 2021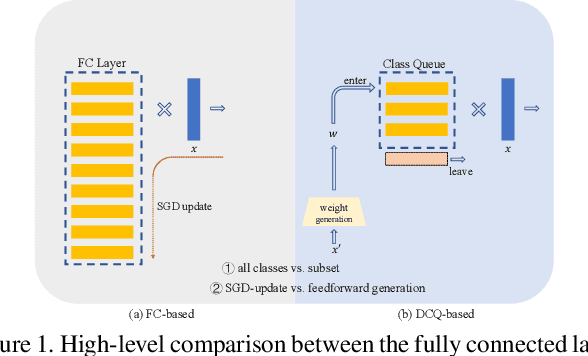

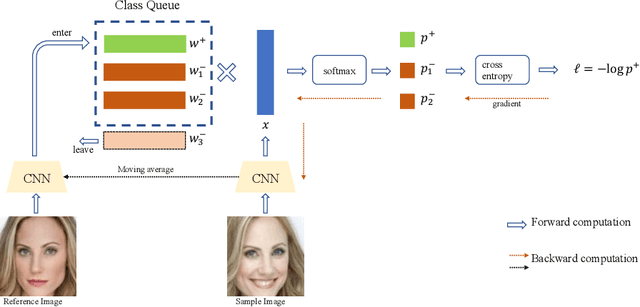
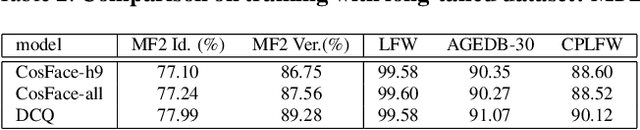
Learning discriminative representation using large-scale face datasets in the wild is crucial for real-world applications, yet it remains challenging. The difficulties lie in many aspects and this work focus on computing resource constraint and long-tailed class distribution. Recently, classification-based representation learning with deep neural networks and well-designed losses have demonstrated good recognition performance. However, the computing and memory cost linearly scales up to the number of identities (classes) in the training set, and the learning process suffers from unbalanced classes. In this work, we propose a dynamic class queue (DCQ) to tackle these two problems. Specifically, for each iteration during training, a subset of classes for recognition are dynamically selected and their class weights are dynamically generated on-the-fly which are stored in a queue. Since only a subset of classes is selected for each iteration, the computing requirement is reduced. By using a single server without model parallel, we empirically verify in large-scale datasets that 10% of classes are sufficient to achieve similar performance as using all classes. Moreover, the class weights are dynamically generated in a few-shot manner and therefore suitable for tail classes with only a few instances. We show clear improvement over a strong baseline in the largest public dataset Megaface Challenge2 (MF2) which has 672K identities and over 88% of them have less than 10 instances. Code is available at https://github.com/bilylee/DCQ
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021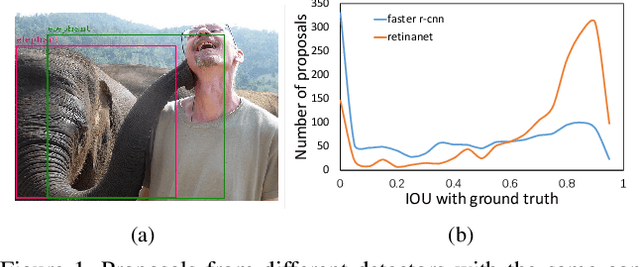

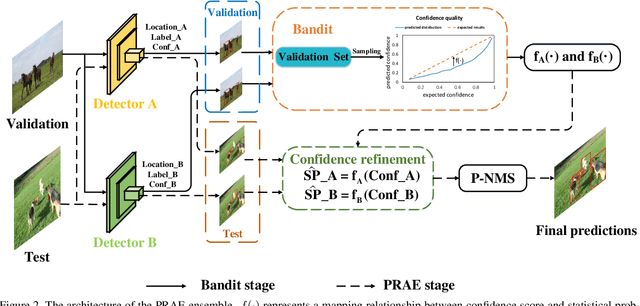

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.
Image Inpainting by End-to-End Cascaded Refinement with Mask Awareness
Apr 28, 2021
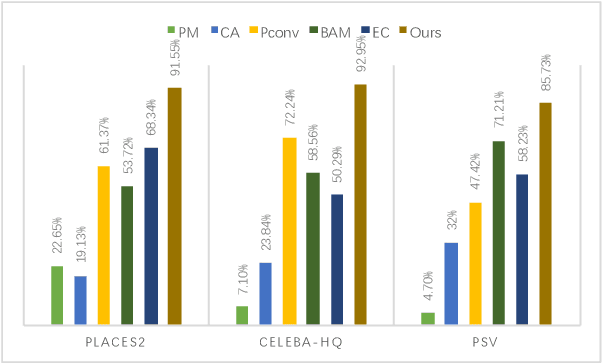


Inpainting arbitrary missing regions is challenging because learning valid features for various masked regions is nontrivial. Though U-shaped encoder-decoder frameworks have been witnessed to be successful, most of them share a common drawback of mask unawareness in feature extraction because all convolution windows (or regions), including those with various shapes of missing pixels, are treated equally and filtered with fixed learned kernels. To this end, we propose our novel mask-aware inpainting solution. Firstly, a Mask-Aware Dynamic Filtering (MADF) module is designed to effectively learn multi-scale features for missing regions in the encoding phase. Specifically, filters for each convolution window are generated from features of the corresponding region of the mask. The second fold of mask awareness is achieved by adopting Point-wise Normalization (PN) in our decoding phase, considering that statistical natures of features at masked points differentiate from those of unmasked points. The proposed PN can tackle this issue by dynamically assigning point-wise scaling factor and bias. Lastly, our model is designed to be an end-to-end cascaded refinement one. Supervision information such as reconstruction loss, perceptual loss and total variation loss is incrementally leveraged to boost the inpainting results from coarse to fine. Effectiveness of the proposed framework is validated both quantitatively and qualitatively via extensive experiments on three public datasets including Places2, CelebA and Paris StreetView.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021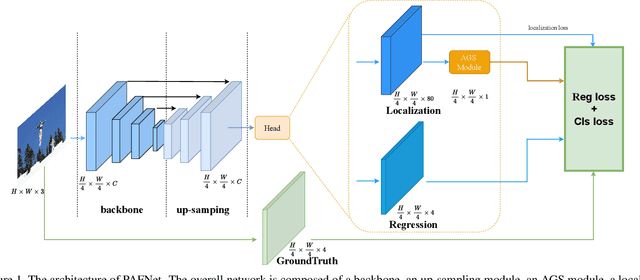
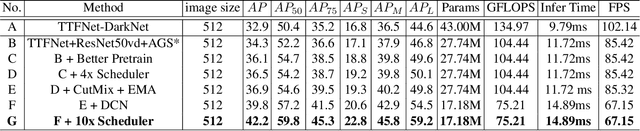
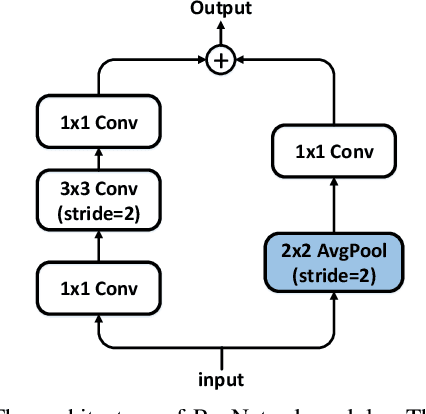

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Unsupervised Multi-Source Domain Adaptation for Person Re-Identification
Apr 27, 2021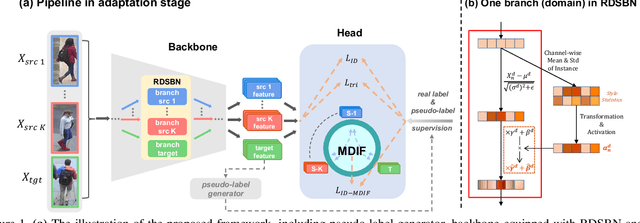

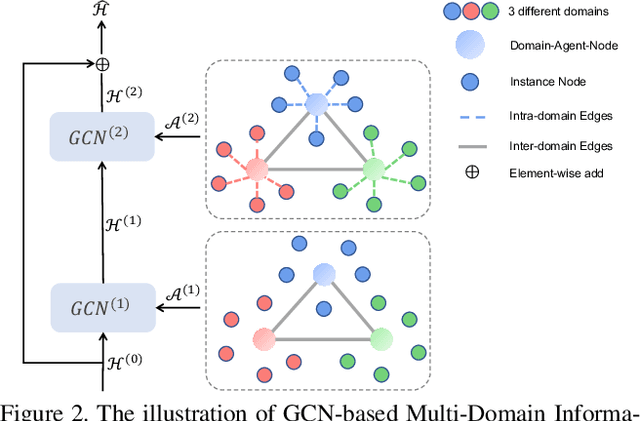
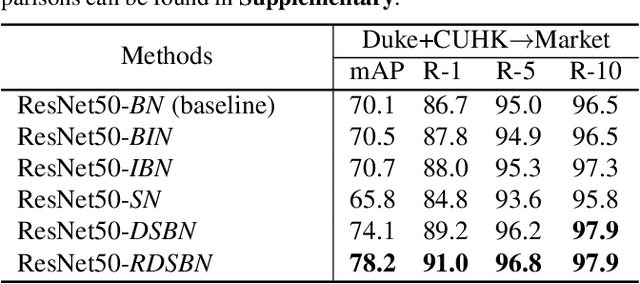
Unsupervised domain adaptation (UDA) methods for person re-identification (re-ID) aim at transferring re-ID knowledge from labeled source data to unlabeled target data. Although achieving great success, most of them only use limited data from a single-source domain for model pre-training, making the rich labeled data insufficiently exploited. To make full use of the valuable labeled data, we introduce the multi-source concept into UDA person re-ID field, where multiple source datasets are used during training. However, because of domain gaps, simply combining different datasets only brings limited improvement. In this paper, we try to address this problem from two perspectives, \ie{} domain-specific view and domain-fusion view. Two constructive modules are proposed, and they are compatible with each other. First, a rectification domain-specific batch normalization (RDSBN) module is explored to simultaneously reduce domain-specific characteristics and increase the distinctiveness of person features. Second, a graph convolutional network (GCN) based multi-domain information fusion (MDIF) module is developed, which minimizes domain distances by fusing features of different domains. The proposed method outperforms state-of-the-art UDA person re-ID methods by a large margin, and even achieves comparable performance to the supervised approaches without any post-processing techniques.