 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCzechDocs: A Multiway Parallel Dataset of Formatted Documents for Minority Languages in Czechia
Jun 18, 2026We present CzechDocs, a multiway parallel dataset of formatted documents (HTML, DOCX, and PDF) covering Czech and minority languages used in Czechia-primarily Ukrainian and English, with smaller portions of Vietnamese, Russian and other languages. The dataset is designed to support the evaluation of machine translation systems that aim to preserve document formatting during translation. We provide a comparison of the most common approaches to format-preserving machine translation on a validation subset of the dataset. This validation split, together with the evaluation toolkit, is publicly released for further research. A held-out test split will be reserved for a future shared task focused on document-level translation with formatting preservation.
Training data generation for context-dependent rubric-based short answer grading
Mar 31, 2026Every four years, the PISA test is administered by the OECD to test the knowledge of teenage students worldwide and allow for comparisons of educational systems. However, having to avoid language differences and annotator bias makes the grading of student answers challenging. For these reasons, it would be interesting to consider methods of automatic student answer grading. To train some of these methods, which require machine learning, or to compute parameters or select hyperparameters for those that do not, a large amount of domain-specific data is needed. In this work, we explore a small number of methods for creating a large-scale training dataset using only a relatively small confidential dataset as a reference, leveraging a set of very simple derived text formats to preserve confidentiality. Using the proposed methods, we successfully created three surrogate datasets that are, at the very least, superficially more similar to the reference dataset than a straightforward result of prompt-based generation. Early experiments suggest one of these approaches might also lead to improved training of automatic answer grading models.
Corpus of Cross-lingual Dialogues with Minutes and Detection of Misunderstandings
Dec 23, 2025Speech processing and translation technology have the potential to facilitate meetings of individuals who do not share any common language. To evaluate automatic systems for such a task, a versatile and realistic evaluation corpus is needed. Therefore, we create and present a corpus of cross-lingual dialogues between individuals without a common language who were facilitated by automatic simultaneous speech translation. The corpus consists of 5 hours of speech recordings with ASR and gold transcripts in 12 original languages and automatic and corrected translations into English. For the purposes of research into cross-lingual summarization, our corpus also includes written summaries (minutes) of the meetings. Moreover, we propose automatic detection of misunderstandings. For an overview of this task and its complexity, we attempt to quantify misunderstandings in cross-lingual meetings. We annotate misunderstandings manually and also test the ability of current large language models to detect them automatically. The results show that the Gemini model is able to identify text spans with misunderstandings with recall of 77% and precision of 47%.
* 12 pages, 2 figures, 6 tables, published as a conference paper in Text, Speech, and Dialogue 28th International Conference, TSD 2025, Erlangen, Germany, August 25-28, 2025, Proceedings, Part II. This version published here on arXiv.org is before review comments and seedings of the TSD conference staff
Overview of the Sensemaking Task at the ELOQUENT 2025 Lab: LLMs as Teachers, Students and Evaluators
Jul 16, 2025



ELOQUENT is a set of shared tasks that aims to create easily testable high-level criteria for evaluating generative language models. Sensemaking is one such shared task. In Sensemaking, we try to assess how well generative models ``make sense out of a given text'' in three steps inspired by exams in a classroom setting: (1) Teacher systems should prepare a set of questions, (2) Student systems should answer these questions, and (3) Evaluator systems should score these answers, all adhering rather strictly to a given set of input materials. We report on the 2025 edition of Sensemaking, where we had 7 sources of test materials (fact-checking analyses of statements, textbooks, transcribed recordings of a lecture, and educational videos) spanning English, German, Ukrainian, and Czech languages. This year, 4 teams participated, providing us with 2 Teacher submissions, 2 Student submissions, and 2 Evaluator submissions. We added baselines for Teacher and Student using commercial large language model systems. We devised a fully automatic evaluation procedure, which we compare to a minimalistic manual evaluation. We were able to make some interesting observations. For the first task, the creation of questions, better evaluation strategies will still have to be devised because it is difficult to discern the quality of the various candidate question sets. In the second task, question answering, the LLMs examined overall perform acceptably, but restricting their answers to the given input texts remains problematic. In the third task, evaluation of question answers, our adversarial tests reveal that systems using the LLM-as-a-Judge paradigm erroneously rate both garbled question-answer pairs and answers to mixed-up questions as acceptable.
MockConf: A Student Interpretation Dataset: Analysis, Word- and Span-level Alignment and Baselines
Jun 05, 2025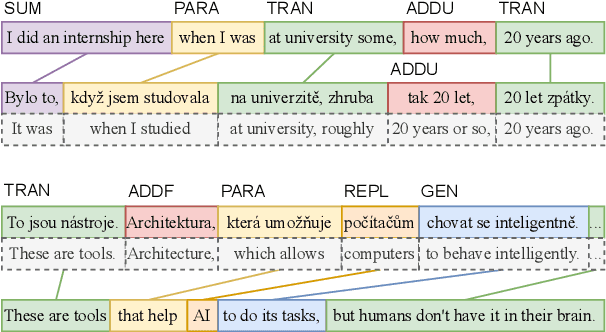
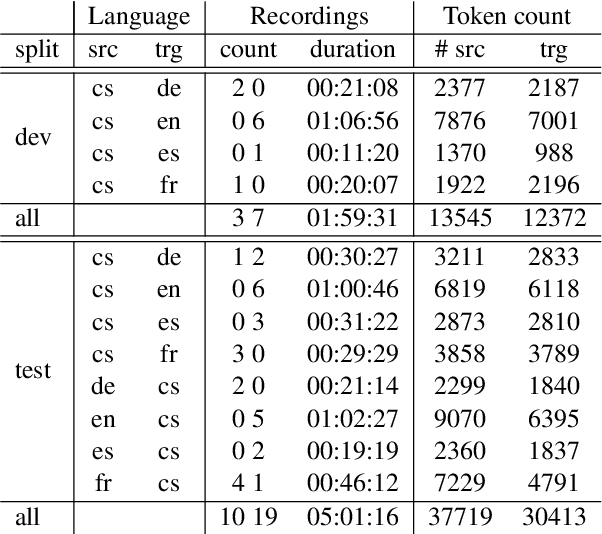
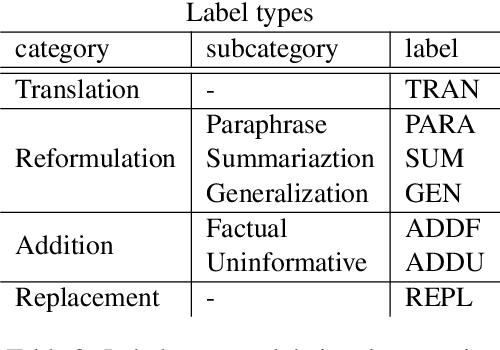
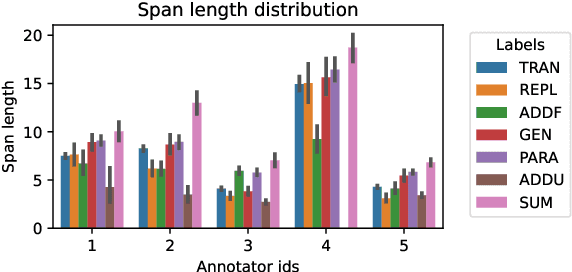
In simultaneous interpreting, an interpreter renders a source speech into another language with a very short lag, much sooner than sentences are finished. In order to understand and later reproduce this dynamic and complex task automatically, we need dedicated datasets and tools for analysis, monitoring, and evaluation, such as parallel speech corpora, and tools for their automatic annotation. Existing parallel corpora of translated texts and associated alignment algorithms hardly fill this gap, as they fail to model long-range interactions between speech segments or specific types of divergences (e.g., shortening, simplification, functional generalization) between the original and interpreted speeches. In this work, we introduce MockConf, a student interpreting dataset that was collected from Mock Conferences run as part of the students' curriculum. This dataset contains 7 hours of recordings in 5 European languages, transcribed and aligned at the level of spans and words. We further implement and release InterAlign, a modern web-based annotation tool for parallel word and span annotations on long inputs, suitable for aligning simultaneous interpreting. We propose metrics for the evaluation and a baseline for automatic alignment. Dataset and tools are released to the community.
Prompting LLMs: Length Control for Isometric Machine Translation
Jun 05, 2025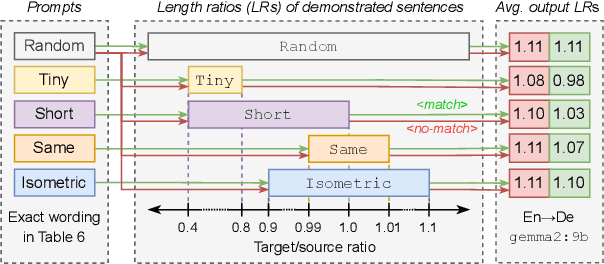

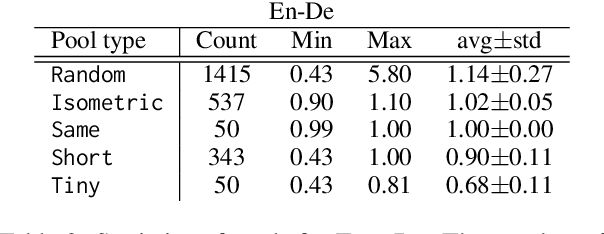
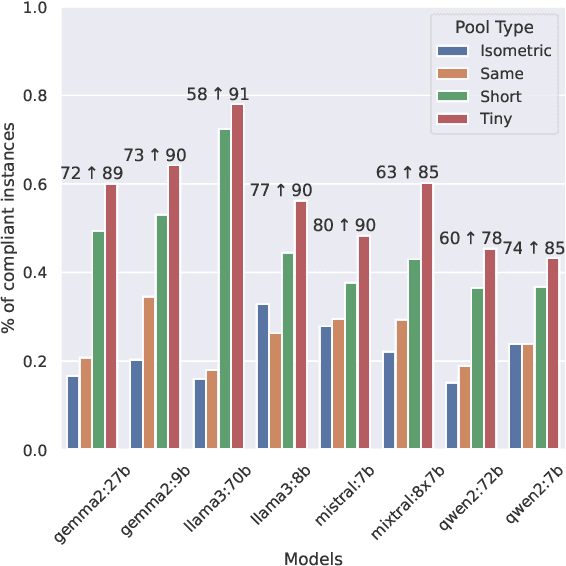
In this study, we explore the effectiveness of isometric machine translation across multiple language pairs (En$\to$De, En$\to$Fr, and En$\to$Es) under the conditions of the IWSLT Isometric Shared Task 2022. Using eight open-source large language models (LLMs) of varying sizes, we investigate how different prompting strategies, varying numbers of few-shot examples, and demonstration selection influence translation quality and length control. We discover that the phrasing of instructions, when aligned with the properties of the provided demonstrations, plays a crucial role in controlling the output length. Our experiments show that LLMs tend to produce shorter translations only when presented with extreme examples, while isometric demonstrations often lead to the models disregarding length constraints. While few-shot prompting generally enhances translation quality, further improvements are marginal across 5, 10, and 20-shot settings. Finally, considering multiple outputs allows to notably improve overall tradeoff between the length and quality, yielding state-of-the-art performance for some language pairs.
How "Real" is Your Real-Time Simultaneous Speech-to-Text Translation System?
Dec 24, 2024



Simultaneous speech-to-text translation (SimulST) translates source-language speech into target-language text concurrently with the speaker's speech, ensuring low latency for better user comprehension. Despite its intended application to unbounded speech, most research has focused on human pre-segmented speech, simplifying the task and overlooking significant challenges. This narrow focus, coupled with widespread terminological inconsistencies, is limiting the applicability of research outcomes to real-world applications, ultimately hindering progress in the field. Our extensive literature review of 110 papers not only reveals these critical issues in current research but also serves as the foundation for our key contributions. We 1) define the steps and core components of a SimulST system, proposing a standardized terminology and taxonomy; 2) conduct a thorough analysis of community trends, and 3) offer concrete recommendations and future directions to bridge the gaps in existing literature, from evaluation frameworks to system architectures, for advancing the field towards more realistic and effective SimulST solutions.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Adversarial Testing as a Tool for Interpretability: Length-based Overfitting of Elementary Functions in Transformers
Oct 17, 2024



The Transformer model has a tendency to overfit various aspects of the training data, such as the overall sequence length. We study elementary string edit functions using a defined set of error indicators to interpret the behaviour of the sequence-to-sequence Transformer. We show that generalization to shorter sequences is often possible, but confirm that longer sequences are highly problematic, although partially correct answers are often obtained. Additionally, we find that other structural characteristics of the sequences, such as subsegment length, may be equally important. We hypothesize that the models learn algorithmic aspects of the tasks simultaneously with structural aspects but adhering to the structural aspects is unfortunately often preferred by Transformer when they come into conflict.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024



Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)