 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Touch My Diacritics
Oct 31, 2024The common practice of preprocessing text before feeding it into NLP models introduces many decision points which have unintended consequences on model performance. In this opinion piece, we focus on the handling of diacritics in texts originating in many languages and scripts. We demonstrate, through several case studies, the adverse effects of inconsistent encoding of diacritized characters and of removing diacritics altogether. We call on the community to adopt simple but necessary steps across all models and toolkits in order to improve handling of diacritized text and, by extension, increase equity in multilingual NLP.
The SIGMORPHON 2022 Shared Task on Morpheme Segmentation
Jun 15, 2022
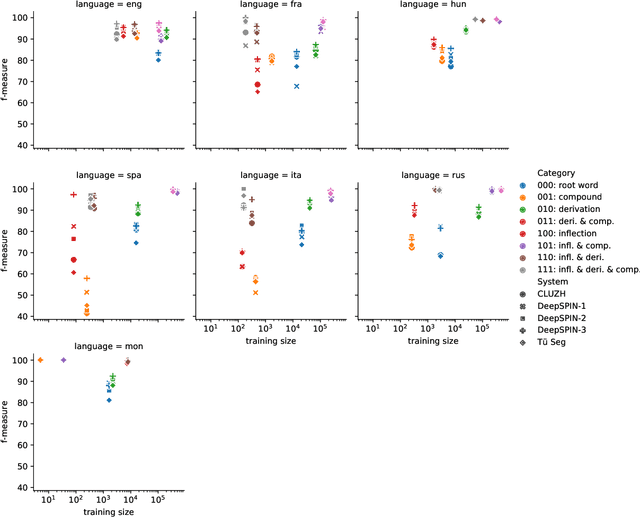
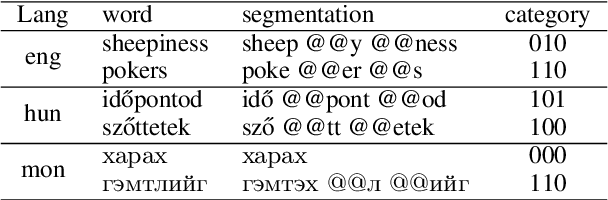
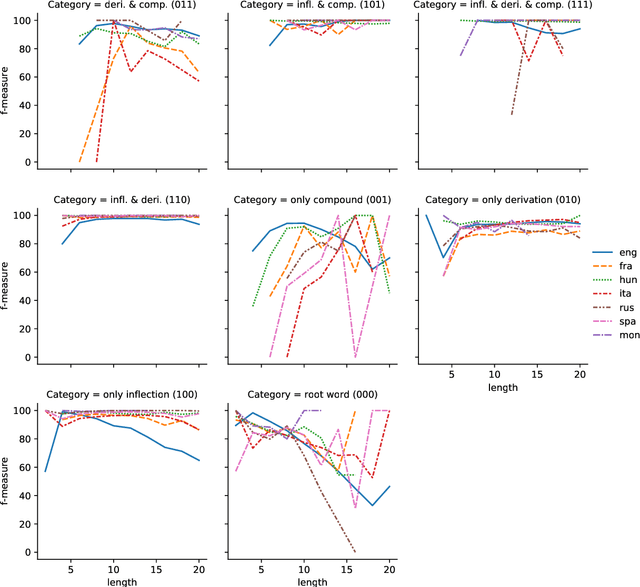
The SIGMORPHON 2022 shared task on morpheme segmentation challenged systems to decompose a word into a sequence of morphemes and covered most types of morphology: compounds, derivations, and inflections. Subtask 1, word-level morpheme segmentation, covered 5 million words in 9 languages (Czech, English, Spanish, Hungarian, French, Italian, Russian, Latin, Mongolian) and received 13 system submissions from 7 teams and the best system averaged 97.29% F1 score across all languages, ranging English (93.84%) to Latin (99.38%). Subtask 2, sentence-level morpheme segmentation, covered 18,735 sentences in 3 languages (Czech, English, Mongolian), received 10 system submissions from 3 teams, and the best systems outperformed all three state-of-the-art subword tokenization methods (BPE, ULM, Morfessor2) by 30.71% absolute. To facilitate error analysis and support any type of future studies, we released all system predictions, the evaluation script, and all gold standard datasets.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
A* shortest string decoding for non-idempotent semirings
Apr 14, 2022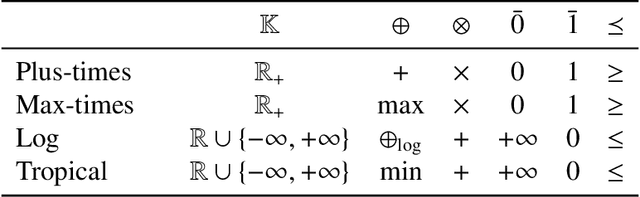
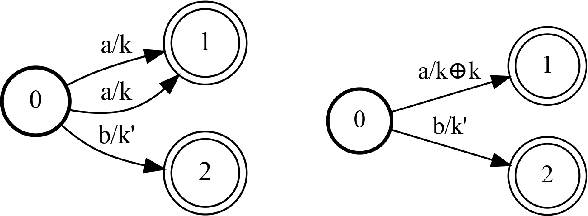
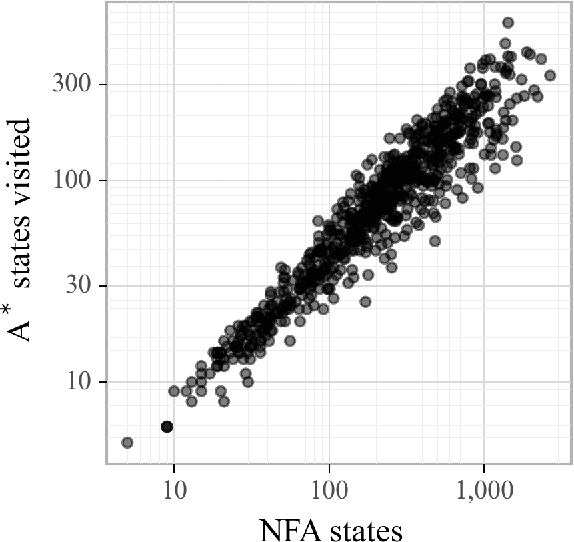
The single shortest path algorithm is undefined for weighted finite-state automata over non-idempotent semirings because such semirings do not guarantee the existence of a shortest path. However, in non-idempotent semirings admitting an order satisfying a monotonicity condition (such as the plus-times or log semirings), the notion of shortest string is well-defined. We describe an algorithm which finds the shortest string for a weighted non-deterministic automaton over such semirings using the backwards shortest distance of an equivalent deterministic automaton (DFA) as a heuristic for A* search performed over a companion idempotent semiring, which is proven to return the shortest string. While there may be exponentially more states in the DFA, this algorithm needs to visit only a small fraction of them if determinization is performed "on the fly".
Group-matching algorithms for subjects and items
Oct 09, 2021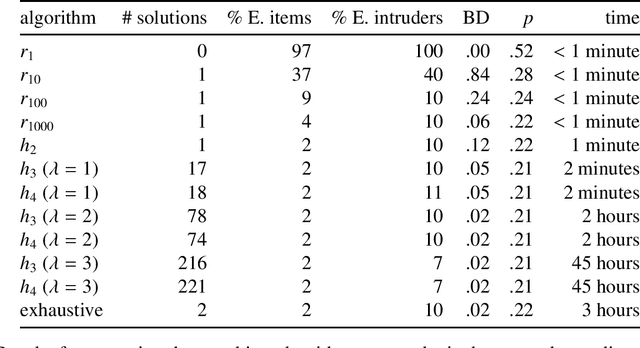
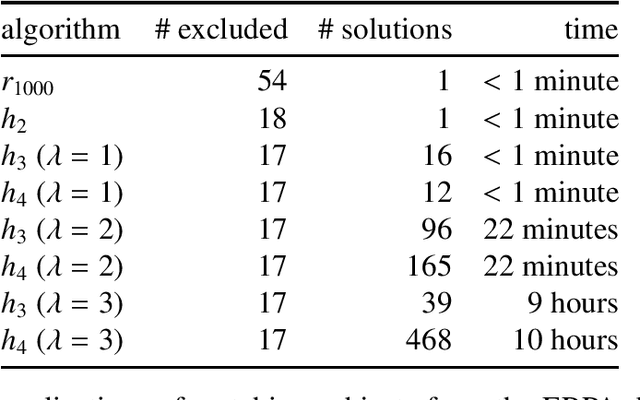
We consider the problem of constructing matched groups such that the resulting groups are statistically similar with respect to their average values for multiple covariates. This group-matching problem arises in many cases, including quasi-experimental and observational studies in which subjects or items are sampled from pre-existing groups, scenarios in which traditional pair-matching approaches may be inappropriate. We consider the case in which one is provided with an existing sample and iteratively eliminates samples so that the groups "match" according to arbitrary statistically-defined criteria. This problem is NP-hard. However, using artificial and real-world data sets, we show that heuristics implemented by the ldamatch package produce high-quality matches.
Structured abbreviation expansion in context
Oct 04, 2021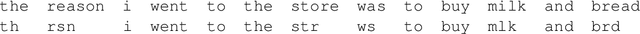
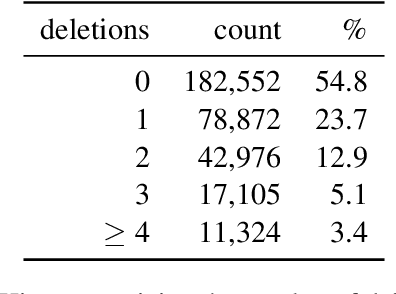
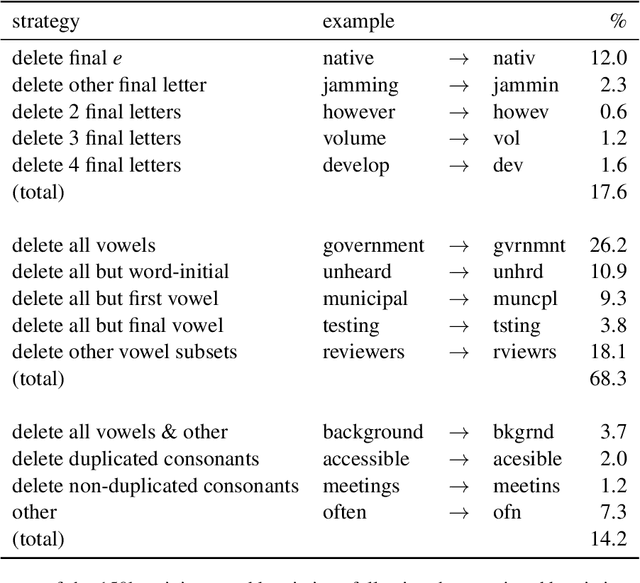
Ad hoc abbreviations are commonly found in informal communication channels that favor shorter messages. We consider the task of reversing these abbreviations in context to recover normalized, expanded versions of abbreviated messages. The problem is related to, but distinct from, spelling correction, in that ad hoc abbreviations are intentional and may involve substantial differences from the original words. Ad hoc abbreviations are productively generated on-the-fly, so they cannot be resolved solely by dictionary lookup. We generate a large, open-source data set of ad hoc abbreviations. This data is used to study abbreviation strategies and to develop two strong baselines for abbreviation expansion
NeMo Inverse Text Normalization: From Development To Production
Apr 11, 2021
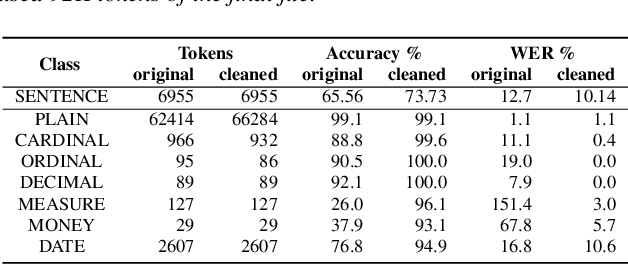
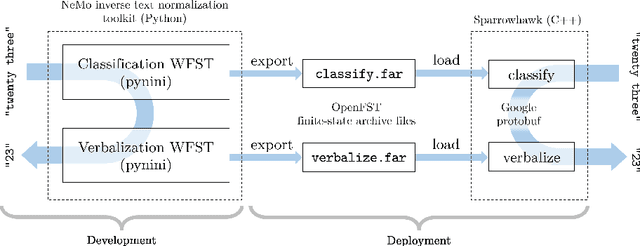

Inverse text normalization (ITN) converts spoken-domain automatic speech recognition (ASR) output into written-domain text to improve the readability of the ASR output. Many state-of-the-art ITN systems use hand-written weighted finite-state transducer(WFST) grammars since this task has extremely low tolerance to unrecoverable errors. We introduce an open-source Python WFST-based library for ITN which enables a seamless path from development to production. We describe the specification of ITN grammar rules for English, but the library can be adapted for other languages. It can also be used for written-to-spoken text normalization. We evaluate the NeMo ITN library using a modified version of the Google Text normalization dataset.
Detecting Objectifying Language in Online Professor Reviews
Oct 16, 2020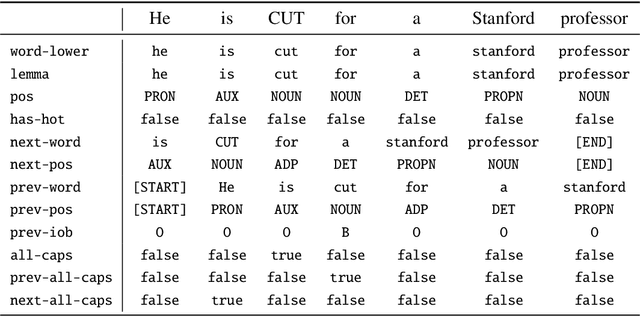
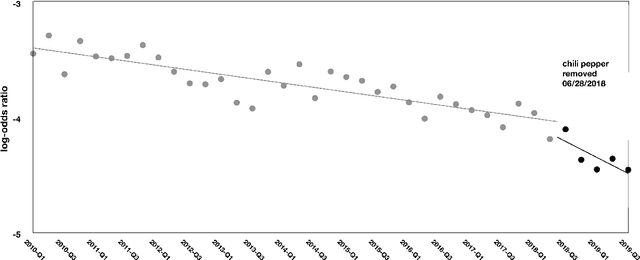
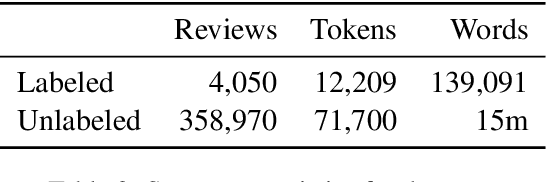
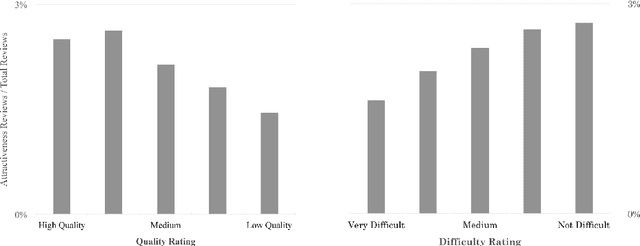
Student reviews often make reference to professors' physical appearances. Until recently RateMyProfessors.com, the website of this study's focus, used a design feature to encourage a "hot or not" rating of college professors. In the wake of recent #MeToo and #TimesUp movements, social awareness of the inappropriateness of these reviews has grown; however, objectifying comments remain and continue to be posted in this online context. We describe two supervised text classifiers for detecting objectifying commentary in professor reviews. We then ensemble these classifiers and use the resulting model to track objectifying commentary at scale. We measure correlations between objectifying commentary, changes to the review website interface, and teacher gender across a ten-year period.
Is the Best Better? Bayesian Statistical Model Comparison for Natural Language Processing
Oct 06, 2020
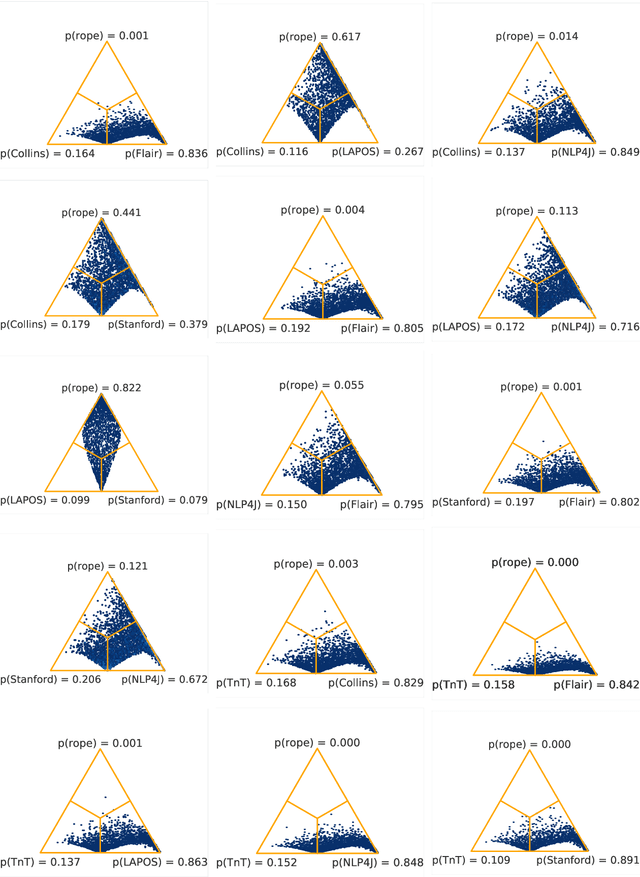
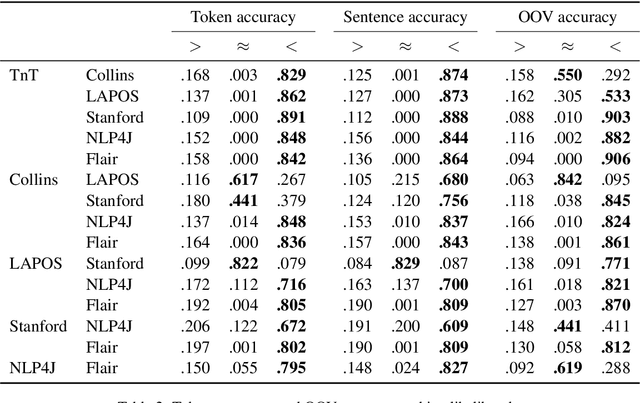
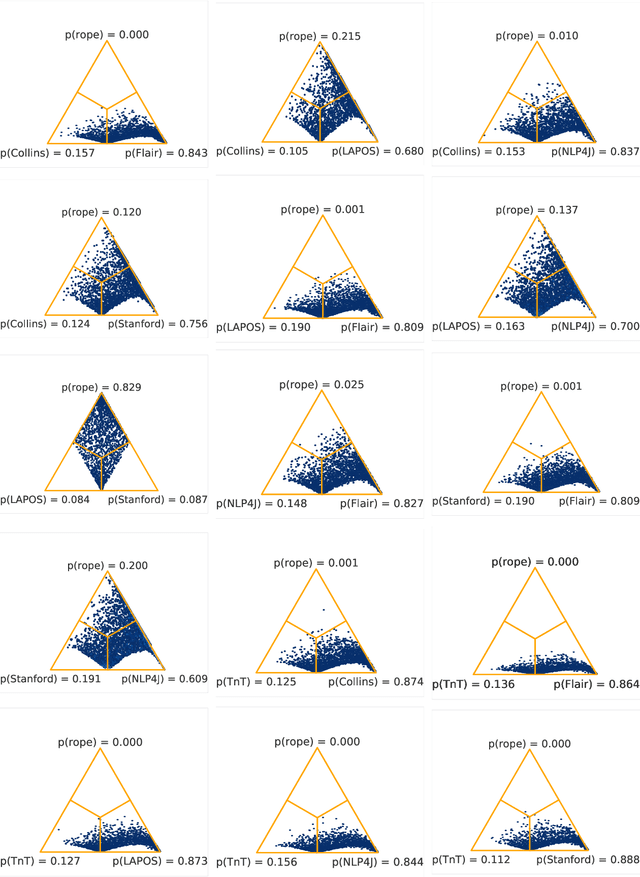
Recent work raises concerns about the use of standard splits to compare natural language processing models. We propose a Bayesian statistical model comparison technique which uses k-fold cross-validation across multiple data sets to estimate the likelihood that one model will outperform the other, or that the two will produce practically equivalent results. We use this technique to rank six English part-of-speech taggers across two data sets and three evaluation metrics.
What Kind of Language Is Hard to Language-Model?
Jun 11, 2019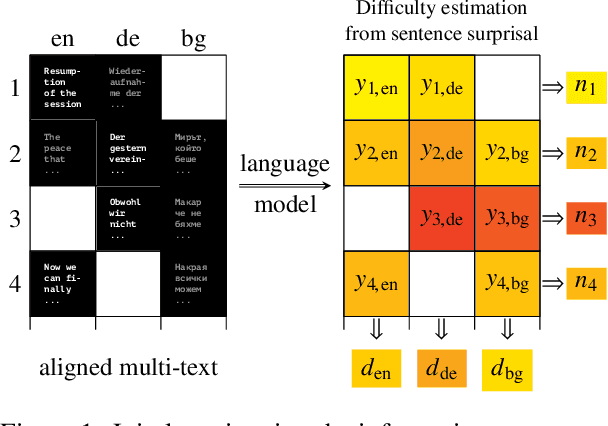
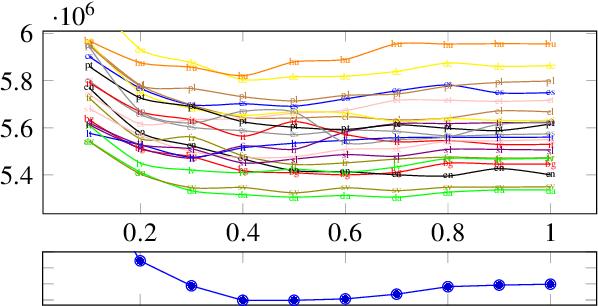
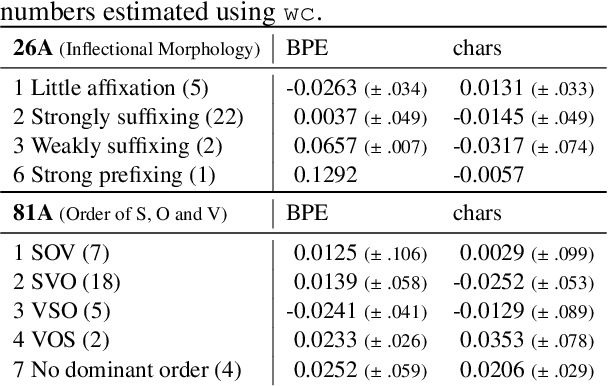
How language-agnostic are current state-of-the-art NLP tools? Are there some types of language that are easier to model with current methods? In prior work (Cotterell et al., 2018) we attempted to address this question for language modeling, and observed that recurrent neural network language models do not perform equally well over all the high-resource European languages found in the Europarl corpus. We speculated that inflectional morphology may be the primary culprit for the discrepancy. In this paper, we extend these earlier experiments to cover 69 languages from 13 language families using a multilingual Bible corpus. Methodologically, we introduce a new paired-sample multiplicative mixed-effects model to obtain language difficulty coefficients from at-least-pairwise parallel corpora. In other words, the model is aware of inter-sentence variation and can handle missing data. Exploiting this model, we show that "translationese" is not any easier to model than natively written language in a fair comparison. Trying to answer the question of what features difficult languages have in common, we try and fail to reproduce our earlier (Cotterell et al., 2018) observation about morphological complexity and instead reveal far simpler statistics of the data that seem to drive complexity in a much larger sample.