 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024



Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)
Long-form Simultaneous Speech Translation: Thesis Proposal
Oct 17, 2023Simultaneous speech translation (SST) aims to provide real-time translation of spoken language, even before the speaker finishes their sentence. Traditionally, SST has been addressed primarily by cascaded systems that decompose the task into subtasks, including speech recognition, segmentation, and machine translation. However, the advent of deep learning has sparked significant interest in end-to-end (E2E) systems. Nevertheless, a major limitation of most approaches to E2E SST reported in the current literature is that they assume that the source speech is pre-segmented into sentences, which is a significant obstacle for practical, real-world applications. This thesis proposal addresses end-to-end simultaneous speech translation, particularly in the long-form setting, i.e., without pre-segmentation. We present a survey of the latest advancements in E2E SST, assess the primary obstacles in SST and its relevance to long-form scenarios, and suggest approaches to tackle these challenges.
Long-Form End-to-End Speech Translation via Latent Alignment Segmentation
Sep 20, 2023

Current simultaneous speech translation models can process audio only up to a few seconds long. Contemporary datasets provide an oracle segmentation into sentences based on human-annotated transcripts and translations. However, the segmentation into sentences is not available in the real world. Current speech segmentation approaches either offer poor segmentation quality or have to trade latency for quality. In this paper, we propose a novel segmentation approach for a low-latency end-to-end speech translation. We leverage the existing speech translation encoder-decoder architecture with ST CTC and show that it can perform the segmentation task without supervision or additional parameters. To the best of our knowledge, our method is the first that allows an actual end-to-end simultaneous speech translation, as the same model is used for translation and segmentation at the same time. On a diverse set of language pairs and in- and out-of-domain data, we show that the proposed approach achieves state-of-the-art quality at no additional computational cost.
Incremental Blockwise Beam Search for Simultaneous Speech Translation with Controllable Quality-Latency Tradeoff
Sep 20, 2023



Blockwise self-attentional encoder models have recently emerged as one promising end-to-end approach to simultaneous speech translation. These models employ a blockwise beam search with hypothesis reliability scoring to determine when to wait for more input speech before translating further. However, this method maintains multiple hypotheses until the entire speech input is consumed -- this scheme cannot directly show a single \textit{incremental} translation to users. Further, this method lacks mechanisms for \textit{controlling} the quality vs. latency tradeoff. We propose a modified incremental blockwise beam search incorporating local agreement or hold-$n$ policies for quality-latency control. We apply our framework to models trained for online or offline translation and demonstrate that both types can be effectively used in online mode. Experimental results on MuST-C show 0.6-3.6 BLEU improvement without changing latency or 0.8-1.4 s latency improvement without changing quality.
* Accepted at INTERSPEECH 2023
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023



Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
ESPnet-ST-v2: Multipurpose Spoken Language Translation Toolkit
Apr 11, 2023



ESPnet-ST-v2 is a revamp of the open-source ESPnet-ST toolkit necessitated by the broadening interests of the spoken language translation community. ESPnet-ST-v2 supports 1) offline speech-to-text translation (ST), 2) simultaneous speech-to-text translation (SST), and 3) offline speech-to-speech translation (S2ST) -- each task is supported with a wide variety of approaches, differentiating ESPnet-ST-v2 from other open source spoken language translation toolkits. This toolkit offers state-of-the-art architectures such as transducers, hybrid CTC/attention, multi-decoders with searchable intermediates, time-synchronous blockwise CTC/attention, Translatotron models, and direct discrete unit models. In this paper, we describe the overall design, example models for each task, and performance benchmarking behind ESPnet-ST-v2, which is publicly available at https://github.com/espnet/espnet.
ALIGNMEET: A Comprehensive Tool for Meeting Annotation, Alignment, and Evaluation
May 11, 2022
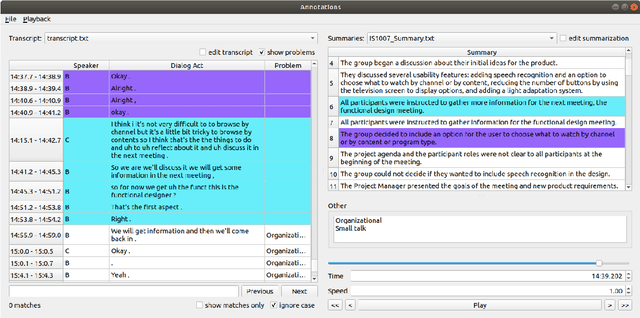

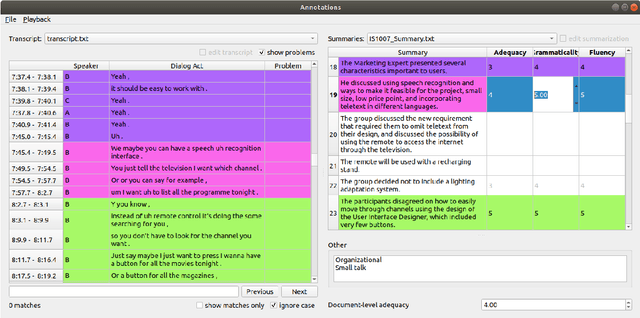
Summarization is a challenging problem, and even more challenging is to manually create, correct, and evaluate the summaries. The severity of the problem grows when the inputs are multi-party dialogues in a meeting setup. To facilitate the research in this area, we present ALIGNMEET, a comprehensive tool for meeting annotation, alignment, and evaluation. The tool aims to provide an efficient and clear interface for fast annotation while mitigating the risk of introducing errors. Moreover, we add an evaluation mode that enables a comprehensive quality evaluation of meeting minutes. To the best of our knowledge, there is no such tool available. We release the tool as open source. It is also directly installable from PyPI.
CUNI-KIT System for Simultaneous Speech Translation Task at IWSLT 2022
Apr 12, 2022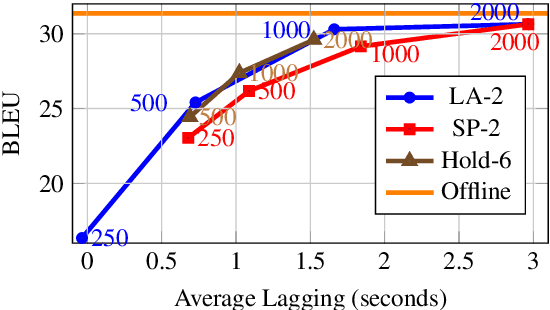
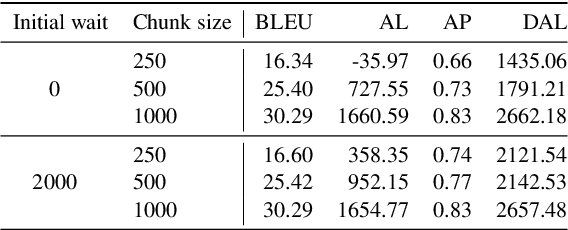
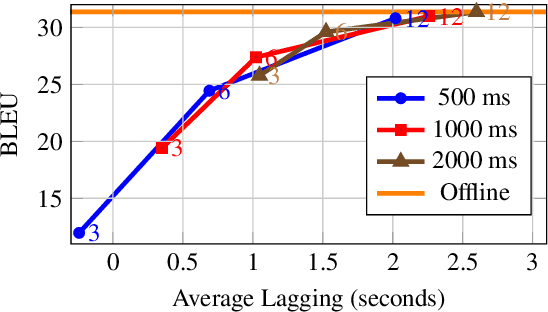
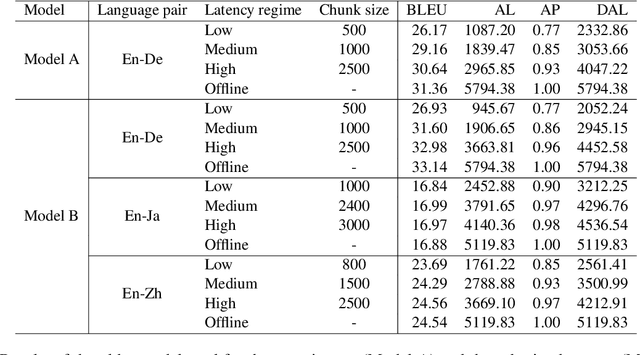
In this paper, we describe our submission to the Simultaneous Speech Translation at IWSLT 2022. We explore strategies to utilize an offline model in a simultaneous setting without the need to modify the original model. In our experiments, we show that our onlinization algorithm is almost on par with the offline setting while being 3x faster than offline in terms of latency on the test set. We make our system publicly available.
Coarse-To-Fine And Cross-Lingual ASR Transfer
Sep 02, 2021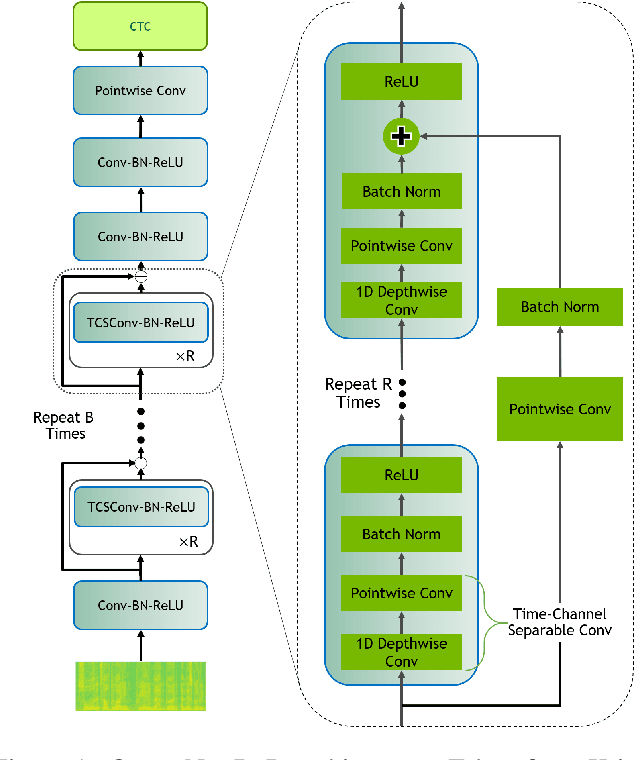
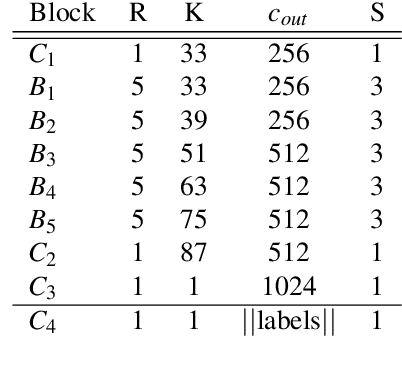
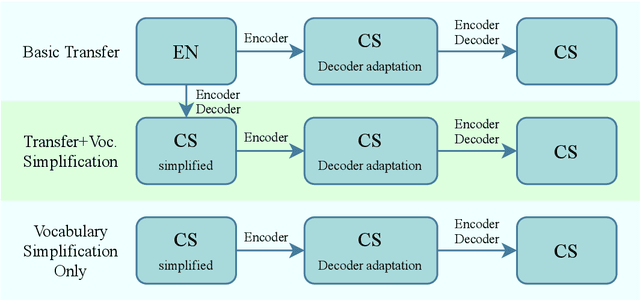

End-to-end neural automatic speech recognition systems achieved recently state-of-the-art results, but they require large datasets and extensive computing resources. Transfer learning has been proposed to overcome these difficulties even across languages, e.g., German ASR trained from an English model. We experiment with much less related languages, reusing an English model for Czech ASR. To simplify the transfer, we propose to use an intermediate alphabet, Czech without accents, and document that it is a highly effective strategy. The technique is also useful on Czech data alone, in the style of coarse-to-fine training. We achieve substantial eductions in training time as well as word error rate (WER).