 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedVox: Safety and Fairness Gaps in Speech Models Across Languages
Jun 25, 2026Speech-capable models are increasingly deployed in real-world applications across languages. Yet their safety and fairness beyond English settings and under naturalistic conditions remain understudied. We survey safety reporting practices across state-of-the-art speech model releases, finding that only 8% document any multilingual analysis. To address this gap, we introduce RedVox, a multilingual safety and fairness benchmark for audio and speech built on real voices, covering unsafe and unfair stereotypical requests across five languages (English, French, Italian, Spanish, and German). Evaluating eight state-of-the-art models, we find that vulnerabilities persist even under non-adversarial conditions, worsen in non-English languages, and are amplified when the request comes from a spoken input. Finally, by surveying the participants who contributed to RedVox, we document the unique personal and privacy challenges of collecting speech data with human participants, pointing to broader sociotechnical challenges in naturalistic speech safety research.
FBK's Long-form SpeechLLMs for IWSLT 2026 Instruction Following
Jun 25, 2026This paper describes our submission to the IWSLT 2026 Instruction Following shared task. SpeechLLMs are developed for both short-form and long-form speech instruction following under constrained settings. For the short track, strong performance is achieved on MCIF, with a SIFS score of 2.0708. For the long track, three speech segmentation methods are explored, and the HIFS score is introduced to account for unstable long-form generation. Experimental results show that fixed 30-second segmentation provides the most robust long-form performance, achieving the highest HIFS score of 2.0663. Further analysis shows that hallucination mainly manifests as repetitive insertions in generated outputs, substantially affecting ASR and SSUM, while short-form capabilities are largely retained after long-form extension.
Ouvia: A User-centered Framework for Measuring Usability of Speech Translation in Real-World Communication Scenarios
Jun 04, 2026Speech translation (ST) is increasingly adopted in user applications, yet its evaluation largely focuses on decontextualized testbeds and holistic quality, rather than end users' communication needs. We introduce Ouvia, an evaluation framework for measuring user-perceived usability of speech translation outputs in real-world settings. Ouvia focuses on one-to-one communication: an English speaker needs to convey a request to a Portuguese speaker, and the message is automatically translated. Through a custom web app and multi-phase study design, we collect more than 1,750 such interactions in healthcare and everyday situations, mediated by four ST systems, involving speakers from three English dialects and two genders. We find that modern ST serves people only to a limited extent -- only around half of interactions are rated as usable -- with significant gaps in reported usability across demographic groups. Moreover, among quality metrics, we find that QA-based evaluation is a substantially stronger predictor of real-world usability than standard approaches. Together, these findings stress the importance of situated, user-centered evaluation frameworks that go beyond holistic quality scores and attend to who the technology serves -- and how well.
SimulU: Training-free Policy for Long-form Simultaneous Speech-to-Speech Translation
Mar 11, 2026Simultaneous speech-to-speech translation (SimulS2S) is essential for real-time multilingual communication, with increasing integration into meeting and streaming platforms. Despite this, SimulS2S remains underexplored in research, where current solutions often rely on resource-intensive training procedures and operate on short-form, pre-segmented utterances, failing to generalize to continuous speech. To bridge this gap, we propose SimulU, the first training-free policy for long-form SimulS2S. SimulU adopts history management and speech output selection strategies that exploit cross-attention in pre-trained end-to-end models to regulate both input history and output generation. Evaluations on MuST-C across 8 languages show that SimulU achieves a better or comparable quality-latency trade-off against strong cascaded models. By eliminating the need for ad-hoc training, SimulU offers a promising path to end-to-end SimulS2S in realistic, long-form scenarios.
Simulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems
Dec 19, 2025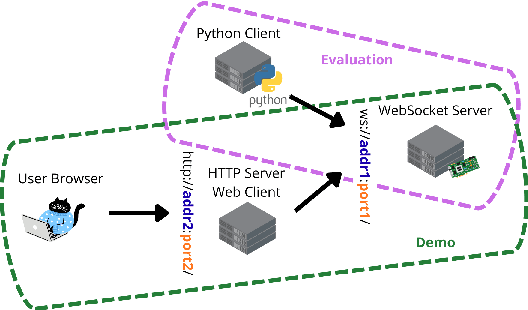
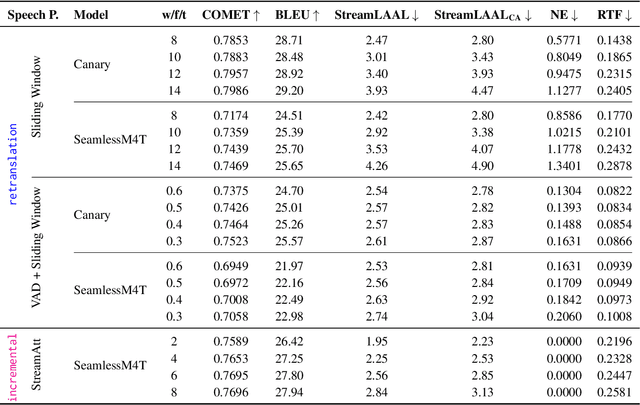
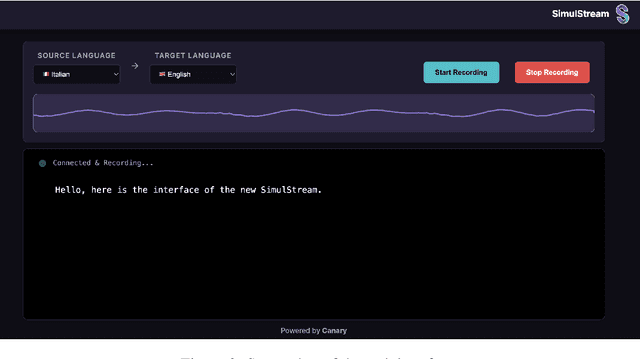
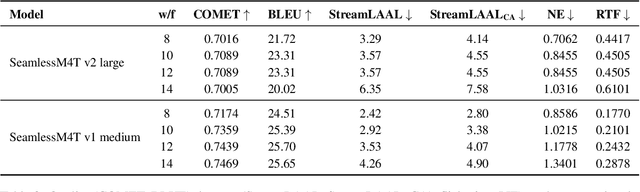
Streaming Speech-to-Text Translation (StreamST) requires producing translations concurrently with incoming speech, imposing strict latency constraints and demanding models that balance partial-information decision-making with high translation quality. Research efforts on the topic have so far relied on the SimulEval repository, which is no longer maintained and does not support systems that revise their outputs. In addition, it has been designed for simulating the processing of short segments, rather than long-form audio streams, and it does not provide an easy method to showcase systems in a demo. As a solution, we introduce simulstream, the first open-source framework dedicated to unified evaluation and demonstration of StreamST systems. Designed for long-form speech processing, it supports not only incremental decoding approaches, but also re-translation methods, enabling for their comparison within the same framework both in terms of quality and latency. In addition, it also offers an interactive web interface to demo any system built within the tool.
The Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025



Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
The Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Implicit bias produces neural scaling laws in learning curves, from perceptrons to deep networks
May 19, 2025Scaling laws in deep learning - empirical power-law relationships linking model performance to resource growth - have emerged as simple yet striking regularities across architectures, datasets, and tasks. These laws are particularly impactful in guiding the design of state-of-the-art models, since they quantify the benefits of increasing data or model size, and hint at the foundations of interpretability in machine learning. However, most studies focus on asymptotic behavior at the end of training or on the optimal training time given the model size. In this work, we uncover a richer picture by analyzing the entire training dynamics through the lens of spectral complexity norms. We identify two novel dynamical scaling laws that govern how performance evolves during training. These laws together recover the well-known test error scaling at convergence, offering a mechanistic explanation of generalization emergence. Our findings are consistent across CNNs, ResNets, and Vision Transformers trained on MNIST, CIFAR-10 and CIFAR-100. Furthermore, we provide analytical support using a solvable model: a single-layer perceptron trained with binary cross-entropy. In this setting, we show that the growth of spectral complexity driven by the implicit bias mirrors the generalization behavior observed at fixed norm, allowing us to connect the performance dynamics to classical learning rules in the perceptron.