 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProper Name Diacritization for Arabic Wikipedia: A Benchmark Dataset
May 05, 2025



Proper names in Arabic Wikipedia are frequently undiacritized, creating ambiguity in pronunciation and interpretation, especially for transliterated named entities of foreign origin. While transliteration and diacritization have been well-studied separately in Arabic NLP,their intersection remains underexplored. In this paper, we introduce a new manually diacritized dataset of Arabic proper names of various origins with their English Wikipedia equivalent glosses, and present the challenges and guidelines we followed to create it. We benchmark GPT-4o on the task of recovering full diacritization given the undiacritized Arabic and English forms, and analyze its performance. Achieving 73% accuracy, our results underscore both the difficulty of the task and the need for improved models and resources. We release our dataset to facilitate further research on Arabic Wikipedia proper name diacritization.
Computational Morphology and Lexicography Modeling of Modern Standard Arabic Nominals
Feb 01, 2024Modern Standard Arabic (MSA) nominals present many morphological and lexical modeling challenges that have not been consistently addressed previously. This paper attempts to define the space of such challenges, and leverage a recently proposed morphological framework to build a comprehensive and extensible model for MSA nominals. Our model design addresses the nominals' intricate morphotactics, as well as their paradigmatic irregularities. Our implementation showcases enhanced accuracy and consistency compared to a commonly used MSA morphological analyzer and generator. We make our models publicly available.
Exploring Linguistic Probes for Morphological Generalization
Oct 20, 2023



Modern work on the cross-linguistic computational modeling of morphological inflection has typically employed language-independent data splitting algorithms. In this paper, we supplement that approach with language-specific probes designed to test aspects of morphological generalization. Testing these probes on three morphologically distinct languages, English, Spanish, and Swahili, we find evidence that three leading morphological inflection systems employ distinct generalization strategies over conjugational classes and feature sets on both orthographic and phonologically transcribed inputs.
Morphological Inflection: A Reality Check
May 25, 2023



Morphological inflection is a popular task in sub-word NLP with both practical and cognitive applications. For years now, state-of-the-art systems have reported high, but also highly variable, performance across data sets and languages. We investigate the causes of this high performance and high variability; we find several aspects of data set creation and evaluation which systematically inflate performance and obfuscate differences between languages. To improve generalizability and reliability of results, we propose new data sampling and evaluation strategies that better reflect likely use-cases. Using these new strategies, we make new observations on the generalization abilities of current inflection systems.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Morphosyntactic Tagging with Pre-trained Language Models for Arabic and its Dialects
Oct 13, 2021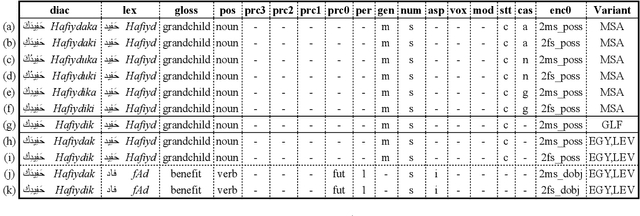
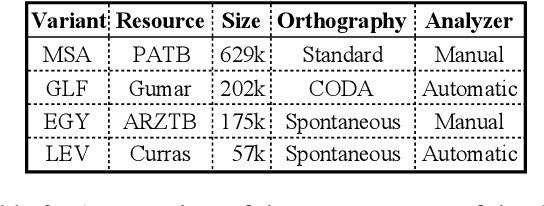
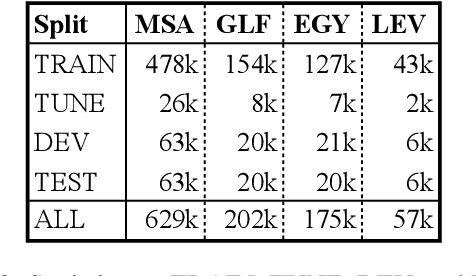
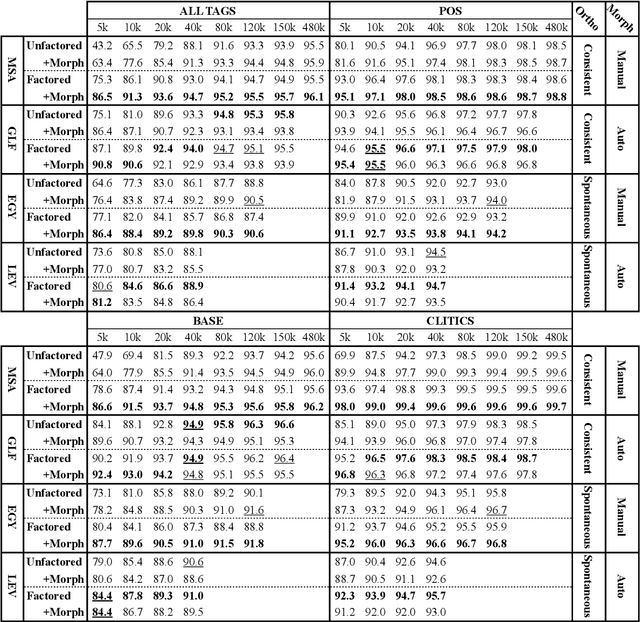
We present state-of-the-art results on morphosyntactic tagging across different varieties of Arabic using fine-tuned pre-trained transformer language models. Our models consistently outperform existing systems in Modern Standard Arabic and all the Arabic dialects we study, achieving 2.6% absolute improvement over the previous state-of-the-art in Modern Standard Arabic, 2.8% in Gulf, 1.6% in Egyptian, and 7.0% in Levantine. We explore different training setups for fine-tuning pre-trained transformer language models, including training data size, the use of external linguistic resources, and the use of annotated data from other dialects in a low-resource scenario. Our results show that strategic fine-tuning using datasets from other high-resource dialects is beneficial for a low-resource dialect. Additionally, we show that high-quality morphological analyzers as external linguistic resources are beneficial especially in low-resource settings.
MADARi: A Web Interface for Joint Arabic Morphological Annotation and Spelling Correction
Aug 25, 2018
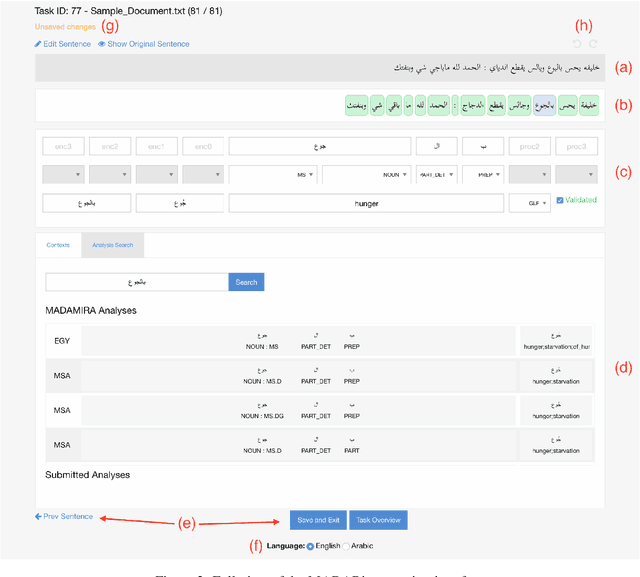
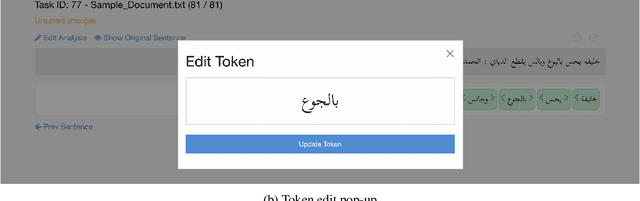
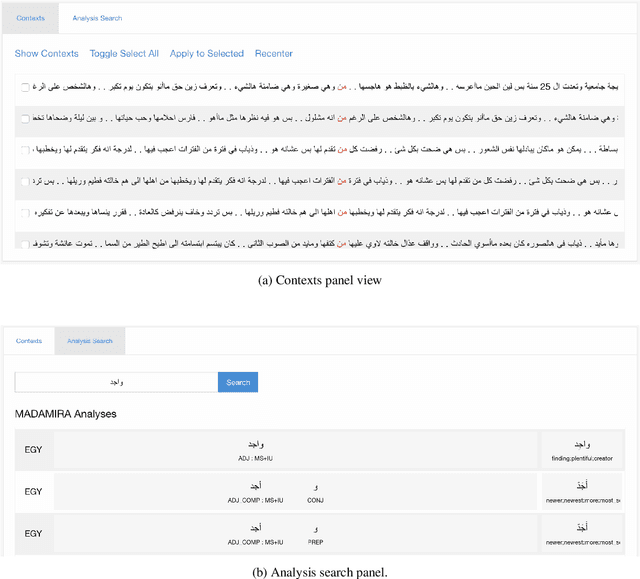
In this paper, we introduce MADARi, a joint morphological annotation and spelling correction system for texts in Standard and Dialectal Arabic. The MADARi framework provides intuitive interfaces for annotating text and managing the annotation process of a large number of sizable documents. Morphological annotation includes indicating, for a word, in context, its baseword, clitics, part-of-speech, lemma, gloss, and dialect identification. MADARi has a suite of utilities to help with annotator productivity. For example, annotators are provided with pre-computed analyses to assist them in their task and reduce the amount of work needed to complete it. MADARi also allows annotators to query a morphological analyzer for a list of possible analyses in multiple dialects or look up previously submitted analyses. The MADARi management interface enables a lead annotator to easily manage and organize the whole annotation process remotely and concurrently. We describe the motivation, design and implementation of this interface; and we present details from a user study working with this system.
A Large Scale Corpus of Gulf Arabic
Sep 09, 2016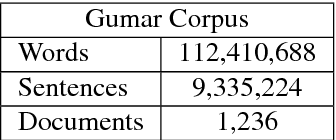
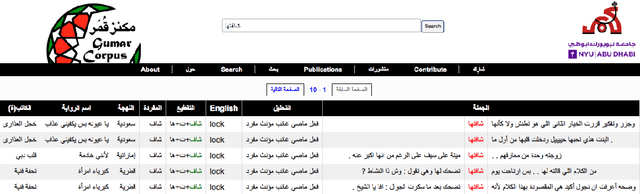
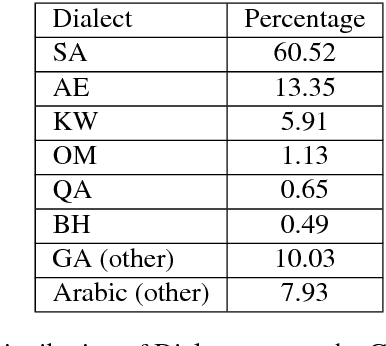
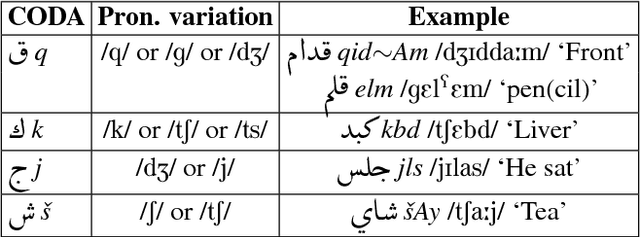
Most Arabic natural language processing tools and resources are developed to serve Modern Standard Arabic (MSA), which is the official written language in the Arab World. Some Dialectal Arabic varieties, notably Egyptian Arabic, have received some attention lately and have a growing collection of resources that include annotated corpora and morphological analyzers and taggers. Gulf Arabic, however, lags behind in that respect. In this paper, we present the Gumar Corpus, a large-scale corpus of Gulf Arabic consisting of 110 million words from 1,200 forum novels. We annotate the corpus for sub-dialect information at the document level. We also present results of a preliminary study in the morphological annotation of Gulf Arabic which includes developing guidelines for a conventional orthography. The text of the corpus is publicly browsable through a web interface we developed for it.