 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023



Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
ChatGPT MT: Competitive for High- (but not Low-) Resource Languages
Sep 14, 2023



Large language models (LLMs) implicitly learn to perform a range of language tasks, including machine translation (MT). Previous studies explore aspects of LLMs' MT capabilities. However, there exist a wide variety of languages for which recent LLM MT performance has never before been evaluated. Without published experimental evidence on the matter, it is difficult for speakers of the world's diverse languages to know how and whether they can use LLMs for their languages. We present the first experimental evidence for an expansive set of 204 languages, along with MT cost analysis, using the FLORES-200 benchmark. Trends reveal that GPT models approach or exceed traditional MT model performance for some high-resource languages (HRLs) but consistently lag for low-resource languages (LRLs), under-performing traditional MT for 84.1% of languages we covered. Our analysis reveals that a language's resource level is the most important feature in determining ChatGPT's relative ability to translate it, and suggests that ChatGPT is especially disadvantaged for LRLs and African languages.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023



In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
When Is TTS Augmentation Through a Pivot Language Useful?
Jul 20, 2022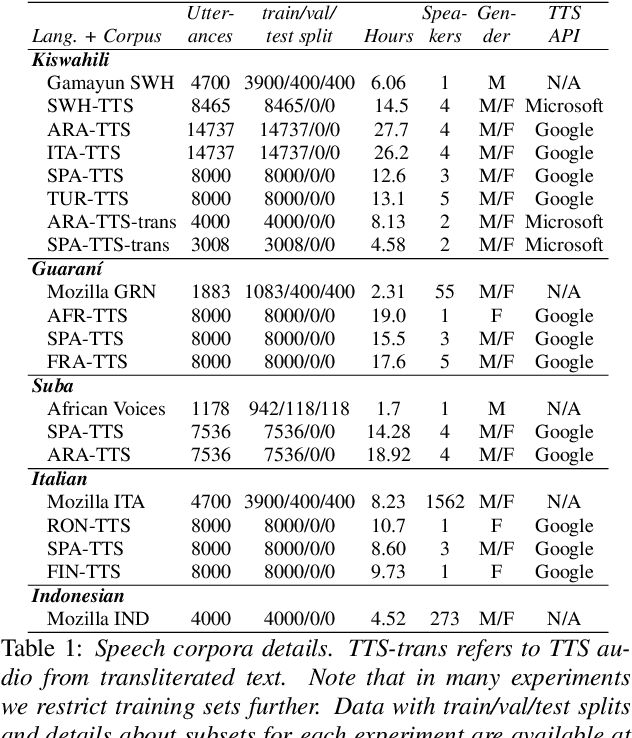
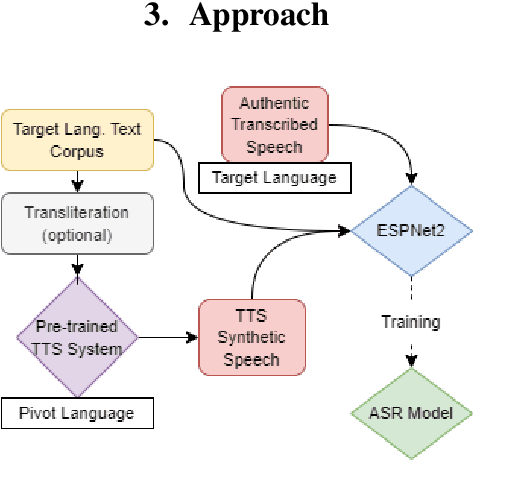
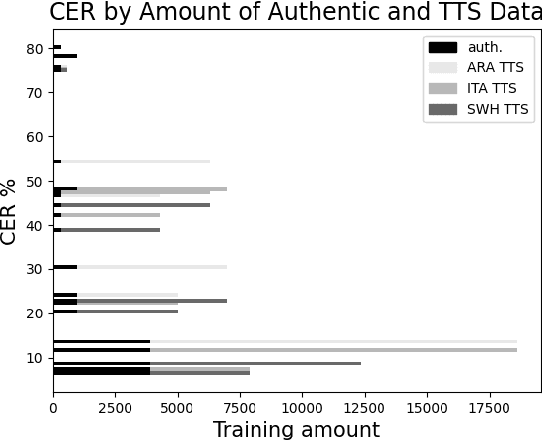
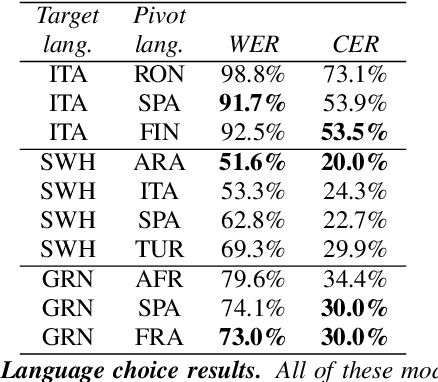
Developing Automatic Speech Recognition (ASR) for low-resource languages is a challenge due to the small amount of transcribed audio data. For many such languages, audio and text are available separately, but not audio with transcriptions. Using text, speech can be synthetically produced via text-to-speech (TTS) systems. However, many low-resource languages do not have quality TTS systems either. We propose an alternative: produce synthetic audio by running text from the target language through a trained TTS system for a higher-resource pivot language. We investigate when and how this technique is most effective in low-resource settings. In our experiments, using several thousand synthetic TTS text-speech pairs and duplicating authentic data to balance yields optimal results. Our findings suggest that searching over a set of candidate pivot languages can lead to marginal improvements and that, surprisingly, ASR performance can by harmed by increases in measured TTS quality. Application of these findings improves ASR by 64.5\% and 45.0\% character error reduction rate (CERR) respectively for two low-resource languages: Guaran\'i and Suba.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022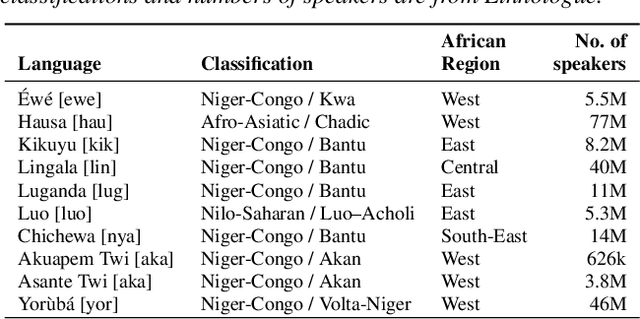
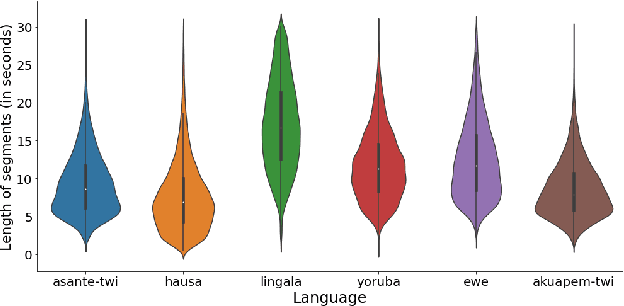
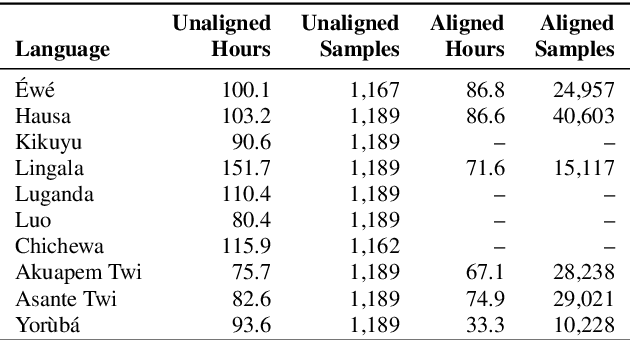
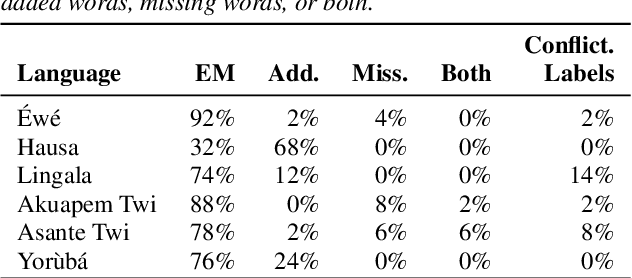
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Building African Voices
Jul 01, 2022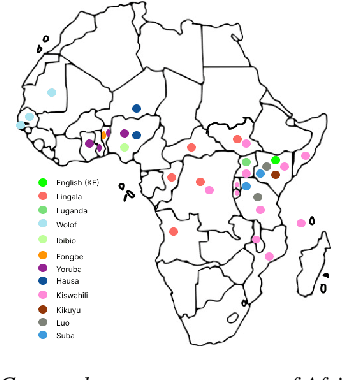
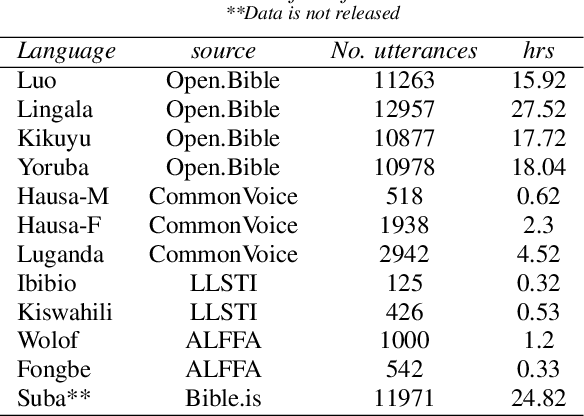
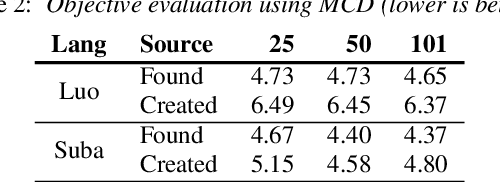
Modern speech synthesis techniques can produce natural-sounding speech given sufficient high-quality data and compute resources. However, such data is not readily available for many languages. This paper focuses on speech synthesis for low-resourced African languages, from corpus creation to sharing and deploying the Text-to-Speech (TTS) systems. We first create a set of general-purpose instructions on building speech synthesis systems with minimum technological resources and subject-matter expertise. Next, we create new datasets and curate datasets from "found" data (existing recordings) through a participatory approach while considering accessibility, quality, and breadth. We demonstrate that we can develop synthesizers that generate intelligible speech with 25 minutes of created speech, even when recorded in suboptimal environments. Finally, we release the speech data, code, and trained voices for 12 African languages to support researchers and developers.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022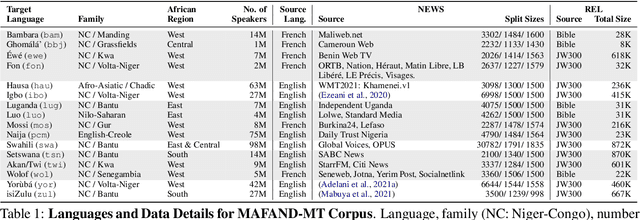
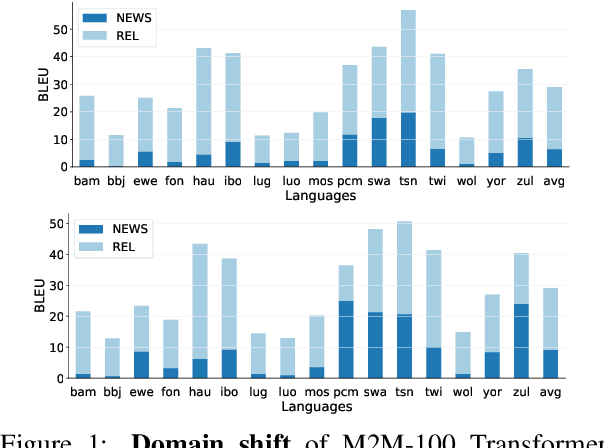

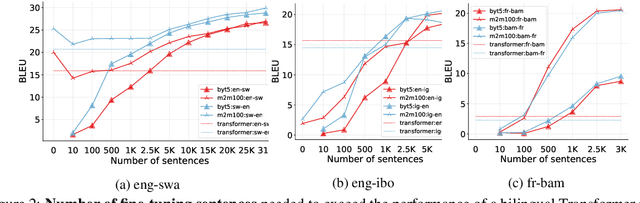
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Quality-Aware Decoding for Neural Machine Translation
May 02, 2022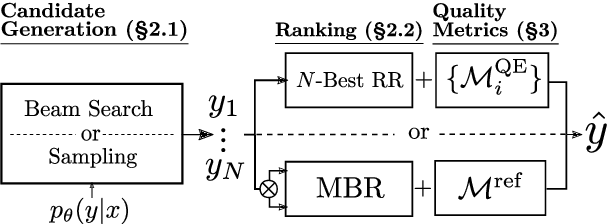
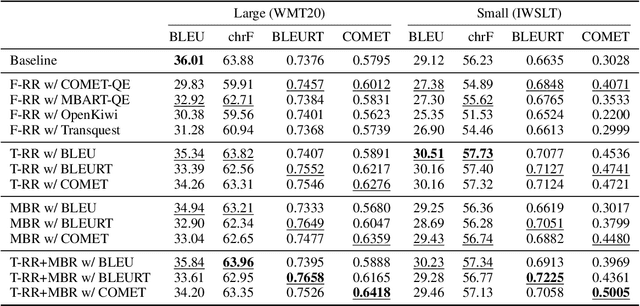
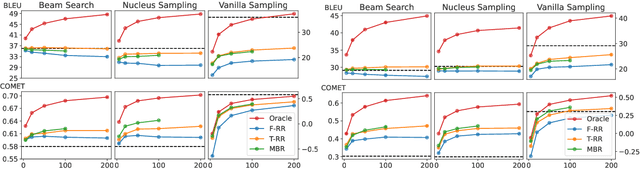
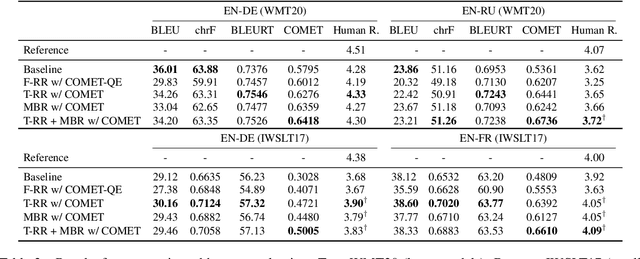
Despite the progress in machine translation quality estimation and evaluation in the last years, decoding in neural machine translation (NMT) is mostly oblivious to this and centers around finding the most probable translation according to the model (MAP decoding), approximated with beam search. In this paper, we bring together these two lines of research and propose quality-aware decoding for NMT, by leveraging recent breakthroughs in reference-free and reference-based MT evaluation through various inference methods like $N$-best reranking and minimum Bayes risk decoding. We perform an extensive comparison of various possible candidate generation and ranking methods across four datasets and two model classes and find that quality-aware decoding consistently outperforms MAP-based decoding according both to state-of-the-art automatic metrics (COMET and BLEURT) and to human assessments. Our code is available at https://github.com/deep-spin/qaware-decode.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021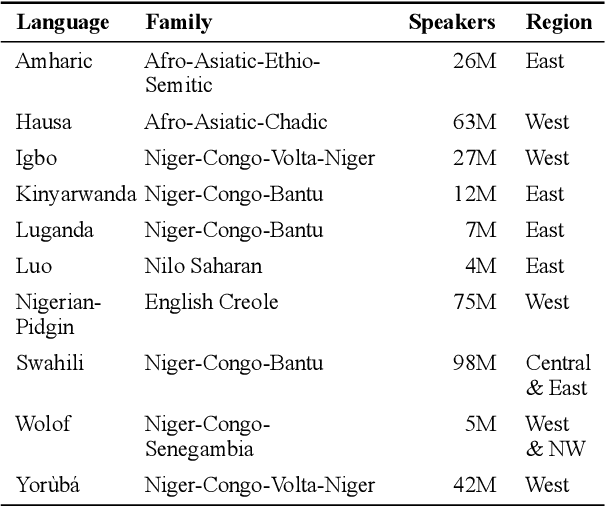

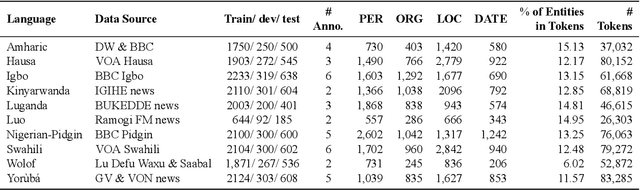
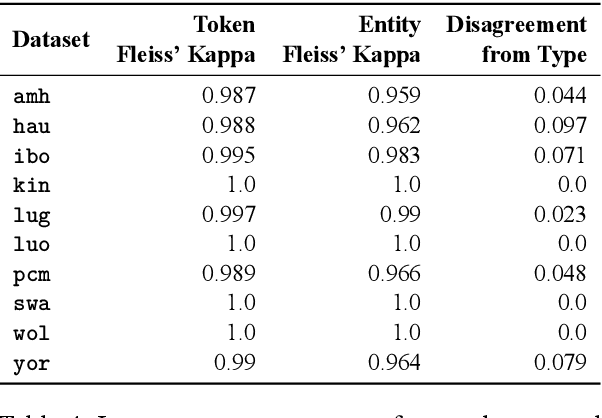
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.