 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems
Dec 19, 2025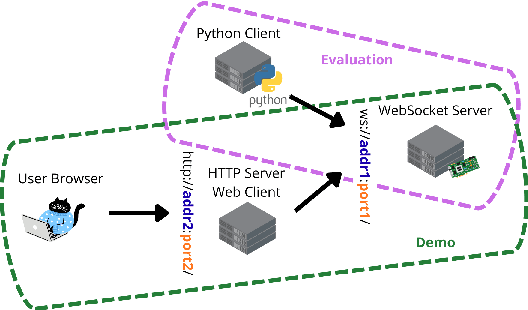
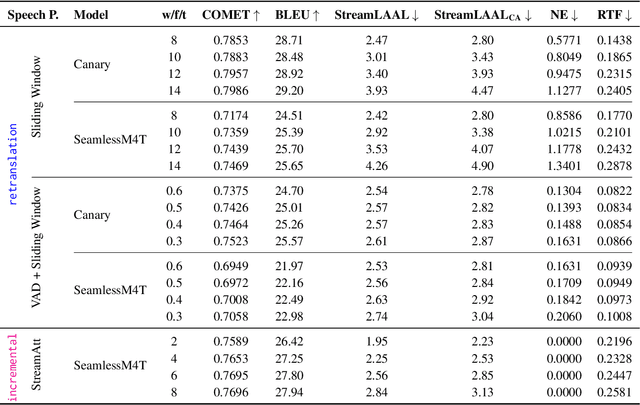
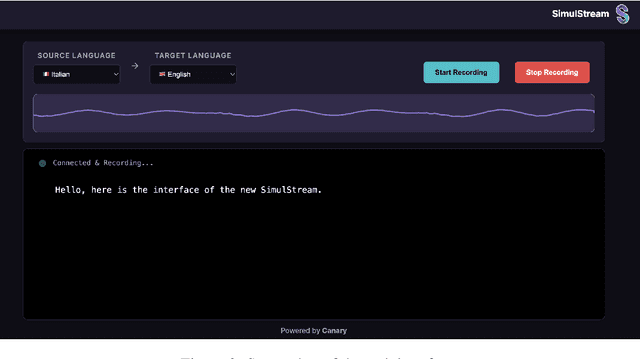
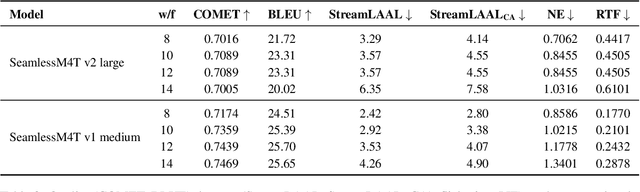
Streaming Speech-to-Text Translation (StreamST) requires producing translations concurrently with incoming speech, imposing strict latency constraints and demanding models that balance partial-information decision-making with high translation quality. Research efforts on the topic have so far relied on the SimulEval repository, which is no longer maintained and does not support systems that revise their outputs. In addition, it has been designed for simulating the processing of short segments, rather than long-form audio streams, and it does not provide an easy method to showcase systems in a demo. As a solution, we introduce simulstream, the first open-source framework dedicated to unified evaluation and demonstration of StreamST systems. Designed for long-form speech processing, it supports not only incremental decoding approaches, but also re-translation methods, enabling for their comparison within the same framework both in terms of quality and latency. In addition, it also offers an interactive web interface to demo any system built within the tool.
The Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
SPES: Spectrogram Perturbation for Explainable Speech-to-Text Generation
Nov 03, 2024



Spurred by the demand for interpretable models, research on eXplainable AI for language technologies has experienced significant growth, with feature attribution methods emerging as a cornerstone of this progress. While prior work in NLP explored such methods for classification tasks and textual applications, explainability intersecting generation and speech is lagging, with existing techniques failing to account for the autoregressive nature of state-of-the-art models and to provide fine-grained, phonetically meaningful explanations. We address this gap by introducing Spectrogram Perturbation for Explainable Speech-to-text Generation (SPES), a feature attribution technique applicable to sequence generation tasks with autoregressive models. SPES provides explanations for each predicted token based on both the input spectrogram and the previously generated tokens. Extensive evaluation on speech recognition and translation demonstrates that SPES generates explanations that are faithful and plausible to humans.
MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages
Oct 01, 2024



The rise of foundation models (FMs), coupled with regulatory efforts addressing their risks and impacts, has sparked significant interest in open-source models. However, existing speech FMs (SFMs) fall short of full compliance with the open-source principles, even if claimed otherwise, as no existing SFM has model weights, code, and training data publicly available under open-source terms. In this work, we take the first step toward filling this gap by focusing on the 24 official languages of the European Union (EU). We collect suitable training data by surveying automatic speech recognition datasets and unlabeled speech corpora under open-source compliant licenses, for a total of 950k hours. Additionally, we release automatic transcripts for 441k hours of unlabeled data under the permissive CC-BY license, thereby facilitating the creation of open-source SFMs for the EU languages.
SBAAM! Eliminating Transcript Dependency in Automatic Subtitling
May 17, 2024



Subtitling plays a crucial role in enhancing the accessibility of audiovisual content and encompasses three primary subtasks: translating spoken dialogue, segmenting translations into concise textual units, and estimating timestamps that govern their on-screen duration. Past attempts to automate this process rely, to varying degrees, on automatic transcripts, employed diversely for the three subtasks. In response to the acknowledged limitations associated with this reliance on transcripts, recent research has shifted towards transcription-free solutions for translation and segmentation, leaving the direct generation of timestamps as uncharted territory. To fill this gap, we introduce the first direct model capable of producing automatic subtitles, entirely eliminating any dependence on intermediate transcripts also for timestamp prediction. Experimental results, backed by manual evaluation, showcase our solution's new state-of-the-art performance across multiple language pairs and diverse conditions.
Integrating Language Models into Direct Speech Translation: An Inference-Time Solution to Control Gender Inflection
Oct 24, 2023



When translating words referring to the speaker, speech translation (ST) systems should not resort to default masculine generics nor rely on potentially misleading vocal traits. Rather, they should assign gender according to the speakers' preference. The existing solutions to do so, though effective, are hardly feasible in practice as they involve dedicated model re-training on gender-labeled ST data. To overcome these limitations, we propose the first inference-time solution to control speaker-related gender inflections in ST. Our approach partially replaces the (biased) internal language model (LM) implicitly learned by the ST decoder with gender-specific external LMs. Experiments on en->es/fr/it show that our solution outperforms the base models and the best training-time mitigation strategy by up to 31.0 and 1.6 points in gender accuracy, respectively, for feminine forms. The gains are even larger (up to 32.0 and 3.4) in the challenging condition where speakers' vocal traits conflict with their gender.
No Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
Oct 10, 2023



Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.
Direct Speech Translation for Automatic Subtitling
Sep 27, 2022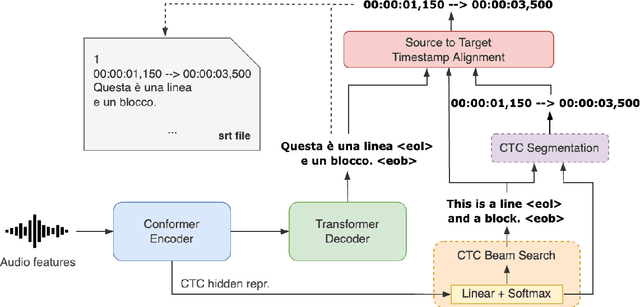
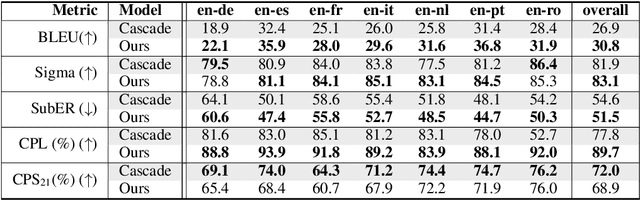
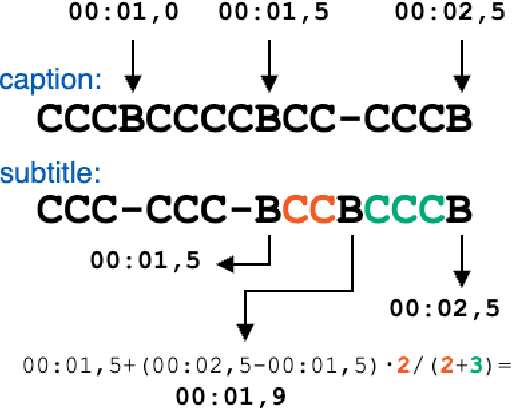
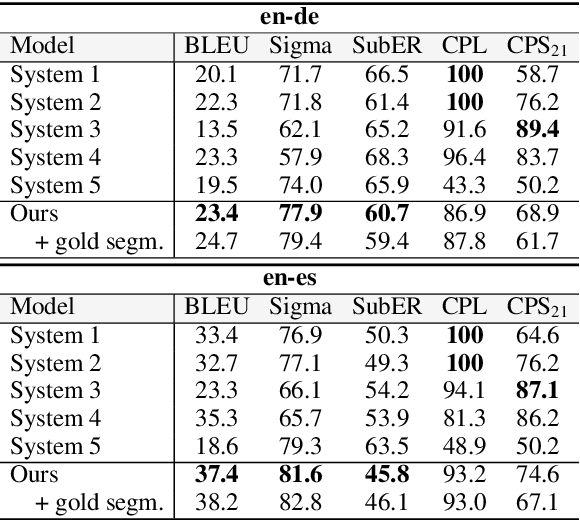
Automatic subtitling is the task of automatically translating the speech of an audiovisual product into short pieces of timed text, in other words, subtitles and their corresponding timestamps. The generated subtitles need to conform to multiple space and time requirements (length, reading speed) while being synchronised with the speech and segmented in a way that facilitates comprehension. Given its considerable complexity, automatic subtitling has so far been addressed through a pipeline of elements that deal separately with transcribing, translating, segmenting into subtitles and predicting timestamps. In this paper, we propose the first direct automatic subtitling model that generates target language subtitles and their timestamps from the source speech in a single solution. Comparisons with state-of-the-art cascaded models trained with both in- and out-domain data show that our system provides high-quality subtitles while also being competitive in terms of conformity, with all the advantages of maintaining a single model.