 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Pairwise Evaluation for Automatic Relative Scoring in Machine Translation
Jan 25, 2026We present PEAR (Pairwise Evaluation for Automatic Relative Scoring), a supervised Quality Estimation (QE) metric family that reframes reference-free Machine Translation (MT) evaluation as a graded pairwise comparison. Given a source segment and two candidate translations, PEAR predicts the direction and magnitude of their quality difference. The metrics are trained using pairwise supervision derived from differences in human judgments, with an additional regularization term that encourages sign inversion under candidate order reversal. On the WMT24 meta-evaluation benchmark, PEAR outperforms strictly matched single-candidate QE baselines trained with the same data and backbones, isolating the benefit of the proposed pairwise formulation. Despite using substantially fewer parameters than recent large metrics, PEAR surpasses far larger QE models and reference-based metrics. Our analysis further indicates that PEAR yields a less redundant evaluation signal relative to other top metrics. Finally, we show that PEAR is an effective utility function for Minimum Bayes Risk (MBR) decoding, reducing pairwise scoring cost at negligible impact.
Token-level Ensembling of Models with Different Vocabularies
Feb 28, 2025Model ensembling is a technique to combine the predicted distributions of two or more models, often leading to improved robustness and performance. For ensembling in text generation, the next token's probability distribution is derived from a weighted sum of the distributions of each individual model. This requires the underlying models to share the same subword vocabulary, limiting the applicability of ensembling, since many open-sourced models have distinct vocabularies. In research settings, experimentation or upgrades to vocabularies may introduce multiple vocabulary sizes. This paper proposes an inference-time only algorithm that allows for ensembling models with different vocabularies, without the need to learn additional parameters or alter the underlying models. Instead, the algorithm ensures that tokens generated by the ensembled models \textit{agree} in their surface form. We apply this technique to combinations of traditional encoder-decoder models and decoder-only LLMs and evaluate on machine translation. In addition to expanding to model pairs that were previously incapable of token-level ensembling, our algorithm frequently improves translation performance over either model individually.
CTC-GMM: CTC guided modality matching for fast and accurate streaming speech translation
Oct 07, 2024



Models for streaming speech translation (ST) can achieve high accuracy and low latency if they're developed with vast amounts of paired audio in the source language and written text in the target language. Yet, these text labels for the target language are often pseudo labels due to the prohibitive cost of manual ST data labeling. In this paper, we introduce a methodology named Connectionist Temporal Classification guided modality matching (CTC-GMM) that enhances the streaming ST model by leveraging extensive machine translation (MT) text data. This technique employs CTC to compress the speech sequence into a compact embedding sequence that matches the corresponding text sequence, allowing us to utilize matched {source-target} language text pairs from the MT corpora to refine the streaming ST model further. Our evaluations with FLEURS and CoVoST2 show that the CTC-GMM approach can increase translation accuracy relatively by 13.9% and 6.4% respectively, while also boosting decoding speed by 59.7% on GPU.
PyMarian: Fast Neural Machine Translation and Evaluation in Python
Aug 15, 2024



The deep learning language of choice these days is Python; measured by factors such as available libraries and technical support, it is hard to beat. At the same time, software written in lower-level programming languages like C++ retain advantages in speed. We describe a Python interface to Marian NMT, a C++-based training and inference toolkit for sequence-to-sequence models, focusing on machine translation. This interface enables models trained with Marian to be connected to the rich, wide range of tools available in Python. A highlight of the interface is the ability to compute state-of-the-art COMET metrics from Python but using Marian's inference engine, with a speedup factor of up to 7.8$\times$ the existing implementations. We also briefly spotlight a number of other integrations, including Jupyter notebooks, connection with prebuilt models, and a web app interface provided with the package. PyMarian is available in PyPI via $\texttt{pip install pymarian}$.
Recovering document annotations for sentence-level bitext
Jun 06, 2024



Data availability limits the scope of any given task. In machine translation, historical models were incapable of handling longer contexts, so the lack of document-level datasets was less noticeable. Now, despite the emergence of long-sequence methods, we remain within a sentence-level paradigm and without data to adequately approach context-aware machine translation. Most large-scale datasets have been processed through a pipeline that discards document-level metadata. In this work, we reconstruct document-level information for three (ParaCrawl, News Commentary, and Europarl) large datasets in German, French, Spanish, Italian, Polish, and Portuguese (paired with English). We then introduce a document-level filtering technique as an alternative to traditional bitext filtering. We present this filtering with analysis to show that this method prefers context-consistent translations rather than those that may have been sentence-level machine translated. Last we train models on these longer contexts and demonstrate improvement in document-level translation without degradation of sentence-level translation. We release our dataset, ParaDocs, and resulting models as a resource to the community.
Navigating the Metrics Maze: Reconciling Score Magnitudes and Accuracies
Jan 12, 2024Ten years ago a single metric, BLEU, governed progress in machine translation research. For better or worse, there is no such consensus today, and consequently it is difficult for researchers to develop and retain the kinds of heuristic intuitions about metric deltas that drove earlier research and deployment decisions. This paper investigates the "dynamic range" of a number of modern metrics in an effort to provide a collective understanding of the meaning of differences in scores both within and among metrics; in other words, we ask what point difference X in metric Y is required between two systems for humans to notice? We conduct our evaluation on a new large dataset, ToShip23, using it to discover deltas at which metrics achieve system-level differences that are meaningful to humans, which we measure by pairwise system accuracy. We additionally show that this method of establishing delta-accuracy is more stable than the standard use of statistical p-values in regards to testset size. Where data size permits, we also explore the effect of metric deltas and accuracy across finer-grained features such as translation direction, domain, and system closeness.
Improving Word Sense Disambiguation in Neural Machine Translation with Salient Document Context
Nov 27, 2023Lexical ambiguity is a challenging and pervasive problem in machine translation (\mt). We introduce a simple and scalable approach to resolve translation ambiguity by incorporating a small amount of extra-sentential context in neural \mt. Our approach requires no sense annotation and no change to standard model architectures. Since actual document context is not available for the vast majority of \mt training data, we collect related sentences for each input to construct pseudo-documents. Salient words from pseudo-documents are then encoded as a prefix to each source sentence to condition the generation of the translation. To evaluate, we release \docmucow, a challenge set for translation disambiguation based on the English-German \mucow \cite{raganato-etal-2020-evaluation} augmented with document IDs. Extensive experiments show that our method translates ambiguous source words better than strong sentence-level baselines and comparable document-level baselines while reducing training costs.
Identifying Context-Dependent Translations for Evaluation Set Production
Nov 04, 2023
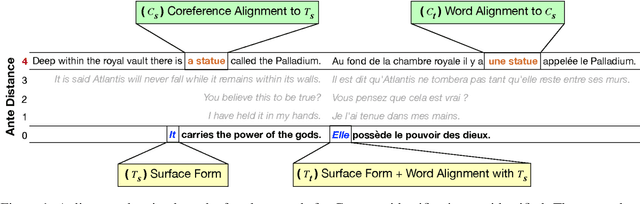
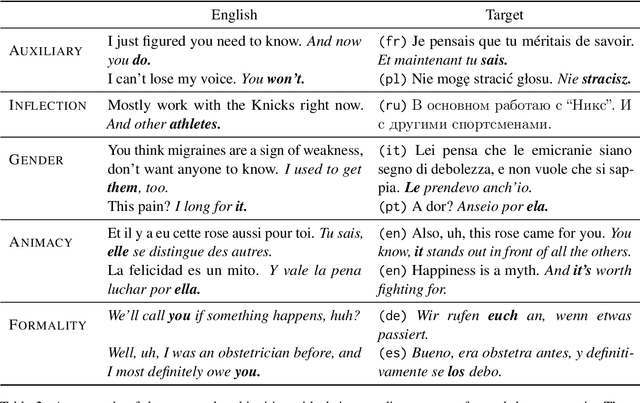
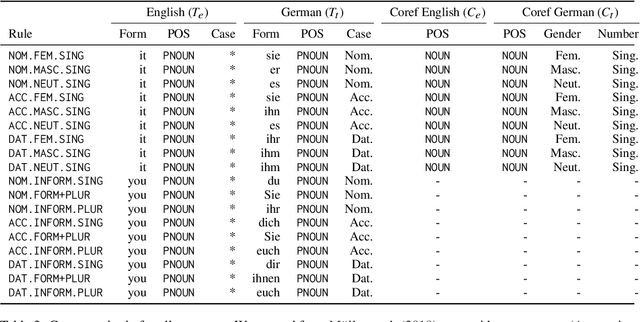
A major impediment to the transition to context-aware machine translation is the absence of good evaluation metrics and test sets. Sentences that require context to be translated correctly are rare in test sets, reducing the utility of standard corpus-level metrics such as COMET or BLEU. On the other hand, datasets that annotate such sentences are also rare, small in scale, and available for only a few languages. To address this, we modernize, generalize, and extend previous annotation pipelines to produce CTXPRO, a tool that identifies subsets of parallel documents containing sentences that require context to correctly translate five phenomena: gender, formality, and animacy for pronouns, verb phrase ellipsis, and ambiguous noun inflections. The input to the pipeline is a set of hand-crafted, per-language, linguistically-informed rules that select contextual sentence pairs using coreference, part-of-speech, and morphological features provided by state-of-the-art tools. We apply this pipeline to seven languages pairs (EN into and out-of DE, ES, FR, IT, PL, PT, and RU) and two datasets (OpenSubtitles and WMT test sets), and validate its performance using both overlap with previous work and its ability to discriminate a contextual MT system from a sentence-based one. We release the CTXPRO pipeline and data as open source.
SLIDE: Reference-free Evaluation for Machine Translation using a Sliding Document Window
Sep 16, 2023


Reference-based metrics that operate at the sentence level typically outperform quality estimation metrics, which have access only to the source and system output. This is unsurprising, since references resolve ambiguities that may be present in the source. We investigate whether additional source context can effectively substitute for a reference. We present a metric, SLIDE (SLiding Document Evaluator), which operates on blocks of sentences using a window that slides over each document in the test set, feeding each chunk into an unmodified, off-the-shelf quality estimation model. We find that SLIDE obtains significantly higher pairwise system accuracy than its sentence-level baseline, in some cases even eliminating the gap with reference-base metrics. This suggests that source context may provide the same information as a human reference.
SOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.