 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Tools: Test-Time Tool Evolution for Scientific Reasoning
Jan 12, 2026The central challenge of AI for Science is not reasoning alone, but the ability to create computational methods in an open-ended scientific world. Existing LLM-based agents rely on static, pre-defined tool libraries, a paradigm that fundamentally fails in scientific domains where tools are sparse, heterogeneous, and intrinsically incomplete. In this paper, we propose Test-Time Tool Evolution (TTE), a new paradigm that enables agents to synthesize, verify, and evolve executable tools during inference. By transforming tools from fixed resources into problem-driven artifacts, TTE overcomes the rigidity and long-tail limitations of static tool libraries. To facilitate rigorous evaluation, we introduce SciEvo, a benchmark comprising 1,590 scientific reasoning tasks supported by 925 automatically evolved tools. Extensive experiments show that TTE achieves state-of-the-art performance in both accuracy and tool efficiency, while enabling effective cross-domain adaptation of computational tools. The code and benchmark have been released at https://github.com/lujiaxuan0520/Test-Time-Tool-Evol.
SketchThinker-R1: Towards Efficient Sketch-Style Reasoning in Large Multimodal Models
Jan 06, 2026Despite the empirical success of extensive, step-by-step reasoning in large multimodal models, long reasoning processes inevitably incur substantial computational overhead, i.e., in terms of higher token costs and increased response time, which undermines inference efficiency. In contrast, humans often employ sketch-style reasoning: a concise, goal-directed cognitive process that prioritizes salient information and enables efficient problem-solving. Inspired by this cognitive efficiency, we propose SketchThinker-R1, which incentivizes sketch-style reasoning ability in large multimodal models. Our method consists of three primary stages. In the Sketch-Mode Cold Start stage, we convert standard long reasoning process into sketch-style reasoning and finetune base multimodal model, instilling initial sketch-style reasoning capability. Next, we train SketchJudge Reward Model, which explicitly evaluates thinking process of model and assigns higher scores to sketch-style reasoning. Finally, we conduct Sketch-Thinking Reinforcement Learning under supervision of SketchJudge to further generalize sketch-style reasoning ability. Experimental evaluation on four benchmarks reveals that our SketchThinker-R1 achieves over 64% reduction in reasoning token cost without compromising final answer accuracy. Qualitative analysis further shows that sketch-style reasoning focuses more on key cues during problem solving.
SCP: Accelerating Discovery with a Global Web of Autonomous Scientific Agents
Dec 30, 2025We introduce SCP: the Science Context Protocol, an open-source standard designed to accelerate discovery by enabling a global network of autonomous scientific agents. SCP is built on two foundational pillars: (1) Unified Resource Integration: At its core, SCP provides a universal specification for describing and invoking scientific resources, spanning software tools, models, datasets, and physical instruments. This protocol-level standardization enables AI agents and applications to discover, call, and compose capabilities seamlessly across disparate platforms and institutional boundaries. (2) Orchestrated Experiment Lifecycle Management: SCP complements the protocol with a secure service architecture, which comprises a centralized SCP Hub and federated SCP Servers. This architecture manages the complete experiment lifecycle (registration, planning, execution, monitoring, and archival), enforces fine-grained authentication and authorization, and orchestrates traceable, end-to-end workflows that bridge computational and physical laboratories. Based on SCP, we have constructed a scientific discovery platform that offers researchers and agents a large-scale ecosystem of more than 1,600 tool resources. Across diverse use cases, SCP facilitates secure, large-scale collaboration between heterogeneous AI systems and human researchers while significantly reducing integration overhead and enhancing reproducibility. By standardizing scientific context and tool orchestration at the protocol level, SCP establishes essential infrastructure for scalable, multi-institution, agent-driven science.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
MiST: Understanding the Role of Mid-Stage Scientific Training in Developing Chemical Reasoning Models
Dec 24, 2025



Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.
An Agentic Framework for Autonomous Materials Computation
Dec 22, 2025



Large Language Models (LLMs) have emerged as powerful tools for accelerating scientific discovery, yet their static knowledge and hallucination issues hinder autonomous research applications. Recent advances integrate LLMs into agentic frameworks, enabling retrieval, reasoning, and tool use for complex scientific workflows. Here, we present a domain-specialized agent designed for reliable automation of first-principles materials computations. By embedding domain expertise, the agent ensures physically coherent multi-step workflows and consistently selects convergent, well-posed parameters, thereby enabling reliable end-to-end computational execution. A new benchmark of diverse computational tasks demonstrates that our system significantly outperforms standalone LLMs in both accuracy and robustness. This work establishes a verifiable foundation for autonomous computational experimentation and represents a key step toward fully automated scientific discovery.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Single-Agent Scaling Fails Multi-Agent Intelligence: Towards Foundation Models with Native Multi-Agent Intelligence
Dec 16, 2025Foundation models (FMs) are increasingly assuming the role of the ''brain'' of AI agents. While recent efforts have begun to equip FMs with native single-agent abilities -- such as GUI interaction or integrated tool use -- we argue that the next frontier is endowing FMs with native multi-agent intelligence. We identify four core capabilities of FMs in multi-agent contexts: understanding, planning, efficient communication, and adaptation. Contrary to assumptions about the spontaneous emergence of such abilities, we provide extensive empirical evidence, across 41 large language models and 7 challenging benchmarks, showing that scaling single-agent performance alone does not automatically yield robust multi-agent intelligence. To address this gap, we outline key research directions -- spanning dataset construction, evaluation, training paradigms, and safety considerations -- for building FMs with native multi-agent intelligence.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025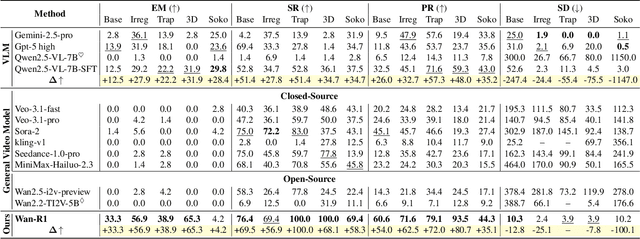

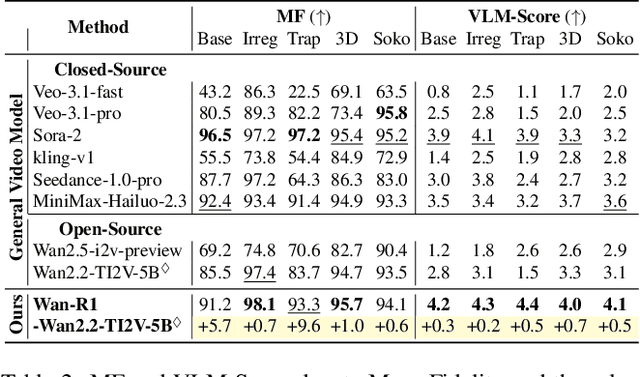
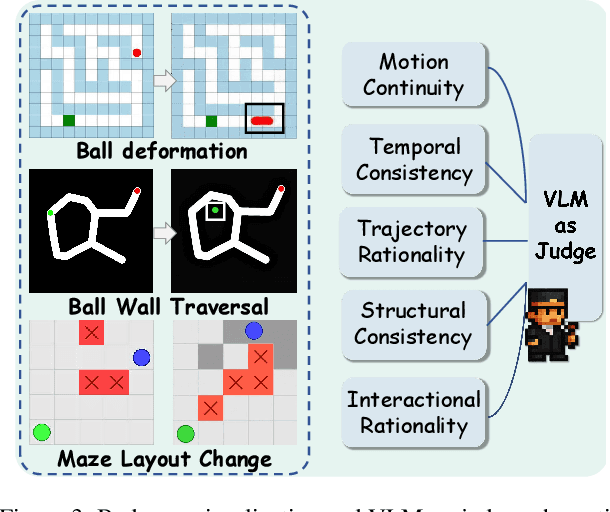
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
P1: Mastering Physics Olympiads with Reinforcement Learning
Nov 17, 2025Recent progress in large language models (LLMs) has moved the frontier from puzzle-solving to science-grade reasoning-the kind needed to tackle problems whose answers must stand against nature, not merely fit a rubric. Physics is the sharpest test of this shift, which binds symbols to reality in a fundamental way, serving as the cornerstone of most modern technologies. In this work, we manage to advance physics research by developing large language models with exceptional physics reasoning capabilities, especially excel at solving Olympiad-level physics problems. We introduce P1, a family of open-source physics reasoning models trained entirely through reinforcement learning (RL). Among them, P1-235B-A22B is the first open-source model with Gold-medal performance at the latest International Physics Olympiad (IPhO 2025), and wins 12 gold medals out of 13 international/regional physics competitions in 2024/2025. P1-30B-A3B also surpasses almost all other open-source models on IPhO 2025, getting a silver medal. Further equipped with an agentic framework PhysicsMinions, P1-235B-A22B+PhysicsMinions achieves overall No.1 on IPhO 2025, and obtains the highest average score over the 13 physics competitions. Besides physics, P1 models also present great performance on other reasoning tasks like math and coding, showing the great generalibility of P1 series.