 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeV: Issue Resolving with Visual Data
Dec 23, 2024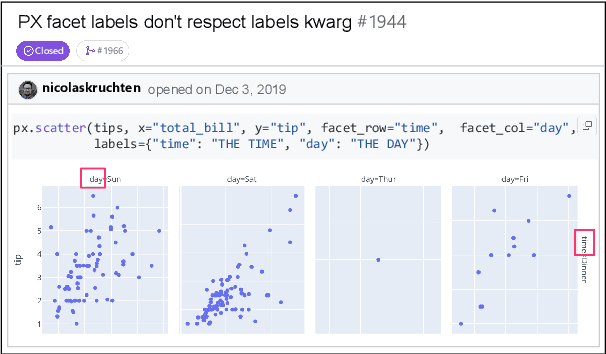
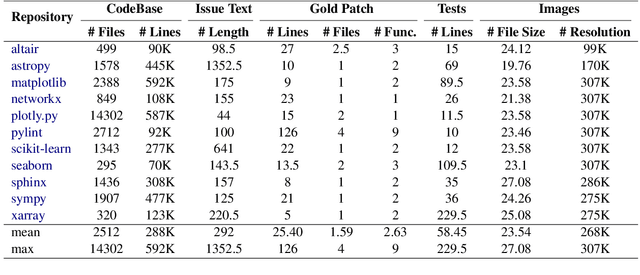


Large Language Models (LLMs) have advanced rapidly in recent years, with their applications in software engineering expanding to more complex repository-level tasks. GitHub issue resolving is a key challenge among these tasks. While recent approaches have made progress on this task, they focus on textual data within issues, neglecting visual data. However, this visual data is crucial for resolving issues as it conveys additional knowledge that text alone cannot. We propose CodeV, the first approach to leveraging visual data to enhance the issue-resolving capabilities of LLMs. CodeV resolves each issue by following a two-phase process: data processing and patch generation. To evaluate CodeV, we construct a benchmark for visual issue resolving, namely Visual SWE-bench. Through extensive experiments, we demonstrate the effectiveness of CodeV, as well as provide valuable insights into leveraging visual data to resolve GitHub issues.
Protecting Confidentiality, Privacy and Integrity in Collaborative Learning
Dec 11, 2024



A collaboration between dataset owners and model owners is needed to facilitate effective machine learning (ML) training. During this collaboration, however, dataset owners and model owners want to protect the confidentiality of their respective assets (i.e., datasets, models and training code), with the dataset owners also caring about the privacy of individual users whose data is in their datasets. Existing solutions either provide limited confidentiality for models and training code, or suffer from privacy issues due to collusion. We present Citadel++, a scalable collaborative ML training system designed to simultaneously protect the confidentiality of datasets, models and training code, as well as the privacy of individual users. Citadel++ enhances differential privacy techniques to safeguard the privacy of individual user data while maintaining model utility. By employing Virtual Machine-level Trusted Execution Environments (TEEs) and improved integrity protection techniques through various OS-level mechanisms, Citadel++ effectively preserves the confidentiality of datasets, models and training code, and enforces our privacy mechanisms even when the models and training code have been maliciously designed. Our experiments show that Citadel++ provides privacy, model utility and performance while adhering to confidentiality and privacy requirements of dataset owners and model owners, outperforming the state-of-the-art privacy-preserving training systems by up to 543x on CPU and 113x on GPU TEEs.
Structured 3D Latents for Scalable and Versatile 3D Generation
Dec 02, 2024



We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding. We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.
CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation
Nov 29, 2024



The advancement of large Vision-Language-Action (VLA) models has significantly improved robotic manipulation in terms of language-guided task execution and generalization to unseen scenarios. While existing VLAs adapted from pretrained large Vision-Language-Models (VLM) have demonstrated promising generalizability, their task performance is still unsatisfactory as indicated by the low tasks success rates in different environments. In this paper, we present a new advanced VLA architecture derived from VLM. Unlike previous works that directly repurpose VLM for action prediction by simple action quantization, we propose a omponentized VLA architecture that has a specialized action module conditioned on VLM output. We systematically study the design of the action module and demonstrates the strong performance enhancement with diffusion action transformers for action sequence modeling, as well as their favorable scaling behaviors. We also conduct comprehensive experiments and ablation studies to evaluate the efficacy of our models with varied designs. The evaluation on 5 robot embodiments in simulation and real work shows that our model not only significantly surpasses existing VLAs in task performance and but also exhibits remarkable adaptation to new robots and generalization to unseen objects and backgrounds. It exceeds the average success rates of OpenVLA which has similar model size (7B) with ours by over 35% in simulated evaluation and 55% in real robot experiments. It also outperforms the large RT-2-X model (55B) by 18% absolute success rates in simulation. Code and models can be found on our project page (https://cogact.github.io/).
Robotic transcatheter tricuspid valve replacement with hybrid enhanced intelligence: a new paradigm and first-in-vivo study
Nov 19, 2024



Transcatheter tricuspid valve replacement (TTVR) is the latest treatment for tricuspid regurgitation and is in the early stages of clinical adoption. Intelligent robotic approaches are expected to overcome the challenges of surgical manipulation and widespread dissemination, but systems and protocols with high clinical utility have not yet been reported. In this study, we propose a complete solution that includes a passive stabilizer, robotic drive, detachable delivery catheter and valve manipulation mechanism. Working towards autonomy, a hybrid augmented intelligence approach based on reinforcement learning, Monte Carlo probabilistic maps and human-robot co-piloted control was introduced. Systematic tests in phantom and first-in-vivo animal experiments were performed to verify that the system design met the clinical requirement. Furthermore, the experimental results confirmed the advantages of co-piloted control over conventional master-slave control in terms of time efficiency, control efficiency, autonomy and stability of operation. In conclusion, this study provides a comprehensive pathway for robotic TTVR and, to our knowledge, completes the first animal study that not only successfully demonstrates the application of hybrid enhanced intelligence in interventional robotics, but also provides a solution with high application value for a cutting-edge procedure.
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
SynChart: Synthesizing Charts from Language Models
Sep 25, 2024With the release of GPT-4V(O), its use in generating pseudo labels for multi-modality tasks has gained significant popularity. However, it is still a secret how to build such advanced models from its base large language models (LLMs). This work explores the potential of using LLMs alone for data generation and develop competitive multi-modality models focusing on chart understanding. We construct a large-scale chart dataset, SynChart, which contains approximately 4 million diverse chart images with over 75 million dense annotations, including data tables, code, descriptions, and question-answer sets. We trained a 4.2B chart-expert model using this dataset and achieve near-GPT-4O performance on the ChartQA task, surpassing GPT-4V.
SWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
Logic Distillation: Learning from Code Function by Function for Planning and Decision-making
Jul 28, 2024



Large language models (LLMs) have garnered increasing attention owing to their powerful logical reasoning capabilities. Generally, larger LLMs (L-LLMs) that require paid interfaces exhibit significantly superior performance compared to smaller LLMs (S-LLMs) that can be deployed on a variety of devices. Knowledge distillation (KD) aims to empower S-LLMs with the capabilities of L-LLMs, while S-LLMs merely mimic the outputs of L-LLMs, failing to get the powerful logical reasoning capabilities. Consequently, S-LLMs are helpless when it comes to planning and decision-making tasks that require logical reasoning capabilities. To tackle the identified challenges, we propose a novel framework called Logic Distillation (LD). Initially, LD employs L-LLMs to instantiate complex instructions into discrete functions and illustrates their usage to establish a function base. Subsequently, based on the function base, LD fine-tunes S-LLMs to learn the logic employed by L-LLMs in planning and decision-making. During testing, LD utilizes a retriever to identify the top-$K$ relevant functions based on instructions and current states, which will be selected and invoked by S-LLMs. Ultimately, S-LLMs yield planning and decision-making outcomes, function by function. Relevant experiments demonstrate that with the assistance of LD, S-LLMs can achieve outstanding results in planning and decision-making tasks, comparable to, or even surpassing, those of L-LLMs.
DepGAN: Leveraging Depth Maps for Handling Occlusions and Transparency in Image Composition
Jul 16, 2024



Image composition is a complex task which requires a lot of information about the scene for an accurate and realistic composition, such as perspective, lighting, shadows, occlusions, and object interactions. Previous methods have predominantly used 2D information for image composition, neglecting the potentials of 3D spatial information. In this work, we propose DepGAN, a Generative Adversarial Network that utilizes depth maps and alpha channels to rectify inaccurate occlusions and enhance transparency effects in image composition. Central to our network is a novel loss function called Depth Aware Loss which quantifies the pixel wise depth difference to accurately delineate occlusion boundaries while compositing objects at different depth levels. Furthermore, we enhance our network's learning process by utilizing opacity data, enabling it to effectively manage compositions involving transparent and semi-transparent objects. We tested our model against state-of-the-art image composition GANs on benchmark (both real and synthetic) datasets. The results reveal that DepGAN significantly outperforms existing methods in terms of accuracy of object placement semantics, transparency and occlusion handling, both visually and quantitatively. Our code is available at https://amrtsg.github.io/DepGAN/.