 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Multiplication on Quantum Computer
Aug 06, 2024This paper introduces an innovative and practical approach to universal quantum matrix multiplication. We designed optimized quantum adders and multipliers based on Quantum Fourier Transform (QFT), which significantly reduced the number of gates used compared to classical adders and multipliers. Subsequently, we construct a basic universal quantum matrix multiplication and extend it to the Strassen algorithm. We conduct comparative experiments to analyze the performance of the quantum matrix multiplication and evaluate the acceleration provided by the optimized quantum adder and multiplier. Furthermore, we investigate the advantages and disadvantages of the quantum Strassen algorithm compared to basic quantum matrix multiplication.
scRDiT: Generating single-cell RNA-seq data by diffusion transformers and accelerating sampling
Apr 09, 2024



Motivation: Single-cell RNA sequencing (scRNA-seq) is a groundbreaking technology extensively utilized in biological research, facilitating the examination of gene expression at the individual cell level within a given tissue sample. While numerous tools have been developed for scRNA-seq data analysis, the challenge persists in capturing the distinct features of such data and replicating virtual datasets that share analogous statistical properties. Results: Our study introduces a generative approach termed scRNA-seq Diffusion Transformer (scRDiT). This method generates virtual scRNA-seq data by leveraging a real dataset. The method is a neural network constructed based on Denoising Diffusion Probabilistic Models (DDPMs) and Diffusion Transformers (DiTs). This involves subjecting Gaussian noises to the real dataset through iterative noise-adding steps and ultimately restoring the noises to form scRNA-seq samples. This scheme allows us to learn data features from actual scRNA-seq samples during model training. Our experiments, conducted on two distinct scRNA-seq datasets, demonstrate superior performance. Additionally, the model sampling process is expedited by incorporating Denoising Diffusion Implicit Models (DDIM). scRDiT presents a unified methodology empowering users to train neural network models with their unique scRNA-seq datasets, enabling the generation of numerous high-quality scRNA-seq samples. Availability and implementation: https://github.com/DongShengze/scRDiT
Hierarchical Integration Diffusion Model for Realistic Image Deblurring
May 24, 2023Diffusion models (DMs) have recently been introduced in image deblurring and exhibited promising performance, particularly in terms of details reconstruction. However, the diffusion model requires a large number of inference iterations to recover the clean image from pure Gaussian noise, which consumes massive computational resources. Moreover, the distribution synthesized by the diffusion model is often misaligned with the target results, leading to restrictions in distortion-based metrics. To address the above issues, we propose the Hierarchical Integration Diffusion Model (HI-Diff), for realistic image deblurring. Specifically, we perform the DM in a highly compacted latent space to generate the prior feature for the deblurring process. The deblurring process is implemented by a regression-based method to obtain better distortion accuracy. Meanwhile, the highly compact latent space ensures the efficiency of the DM. Furthermore, we design the hierarchical integration module to fuse the prior into the regression-based model from multiple scales, enabling better generalization in complex blurry scenarios. Comprehensive experiments on synthetic and real-world blur datasets demonstrate that our HI-Diff outperforms state-of-the-art methods. Code and trained models are available at https://github.com/zhengchen1999/HI-Diff.
Graphy Analysis Using a GPU-based Parallel Algorithm: Quantum Clustering
May 24, 2023The article introduces a new method for applying Quantum Clustering to graph structures. Quantum Clustering (QC) is a novel density-based unsupervised learning method that determines cluster centers by constructing a potential function. In this method, we use the Graph Gradient Descent algorithm to find the centers of clusters. GPU parallelization is utilized for computing potential values. We also conducted experiments on five widely used datasets and evaluated using four indicators. The results show superior performance of the method. Finally, we discuss the influence of $\sigma$ on the experimental results.
ShadowFormer: Global Context Helps Image Shadow Removal
Feb 03, 2023Recent deep learning methods have achieved promising results in image shadow removal. However, most of the existing approaches focus on working locally within shadow and non-shadow regions, resulting in severe artifacts around the shadow boundaries as well as inconsistent illumination between shadow and non-shadow regions. It is still challenging for the deep shadow removal model to exploit the global contextual correlation between shadow and non-shadow regions. In this work, we first propose a Retinex-based shadow model, from which we derive a novel transformer-based network, dubbed ShandowFormer, to exploit non-shadow regions to help shadow region restoration. A multi-scale channel attention framework is employed to hierarchically capture the global information. Based on that, we propose a Shadow-Interaction Module (SIM) with Shadow-Interaction Attention (SIA) in the bottleneck stage to effectively model the context correlation between shadow and non-shadow regions. We conduct extensive experiments on three popular public datasets, including ISTD, ISTD+, and SRD, to evaluate the proposed method. Our method achieves state-of-the-art performance by using up to 150X fewer model parameters.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022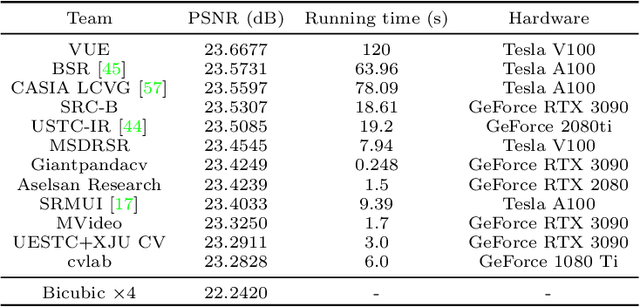
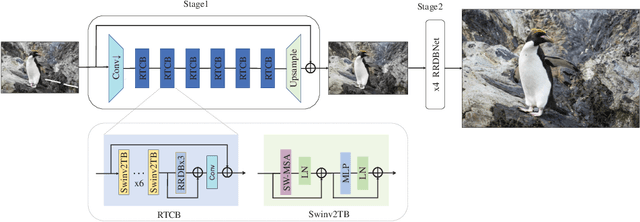

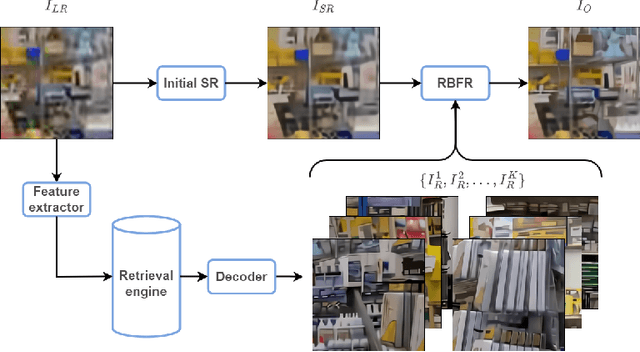
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Boosting Video Super Resolution with Patch-Based Temporal Redundancy Optimization
Jul 18, 2022

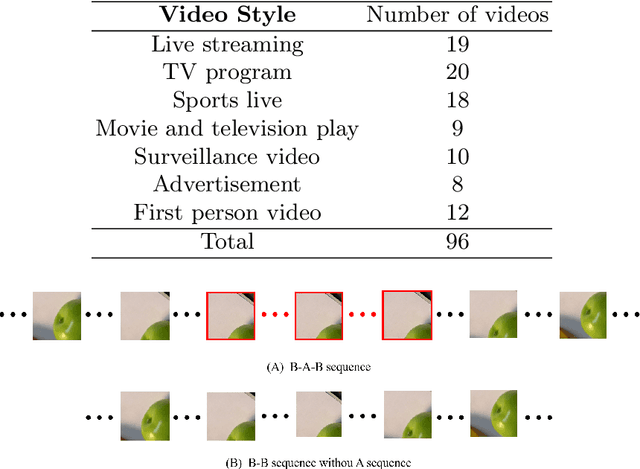

The success of existing video super-resolution (VSR) algorithms stems mainly exploiting the temporal information from the neighboring frames. However, none of these methods have discussed the influence of the temporal redundancy in the patches with stationary objects and background and usually use all the information in the adjacent frames without any discrimination. In this paper, we observe that the temporal redundancy will bring adverse effect to the information propagation,which limits the performance of the most existing VSR methods. Motivated by this observation, we aim to improve existing VSR algorithms by handling the temporal redundancy patches in an optimized manner. We develop two simple yet effective plug and play methods to improve the performance of existing local and non-local propagation-based VSR algorithms on widely-used public videos. For more comprehensive evaluating the robustness and performance of existing VSR algorithms, we also collect a new dataset which contains a variety of public videos as testing set. Extensive evaluations show that the proposed methods can significantly improve the performance of existing VSR methods on the collected videos from wild scenarios while maintain their performance on existing commonly used datasets. The code is available at https://github.com/HYHsimon/Boosted-VSR.
Dynamic Proposals for Efficient Object Detection
Jul 12, 2022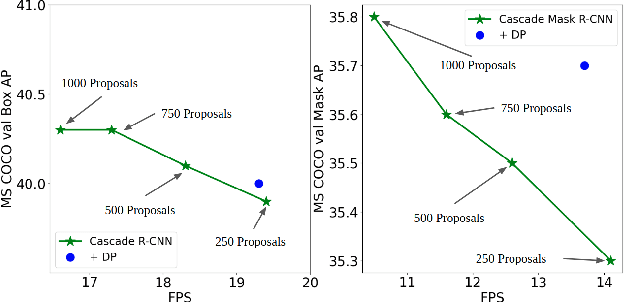
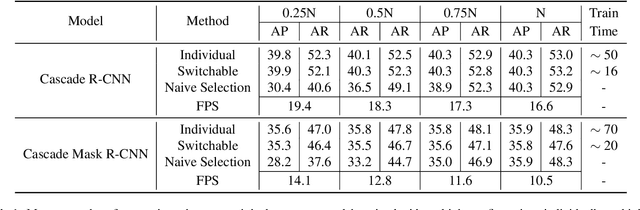
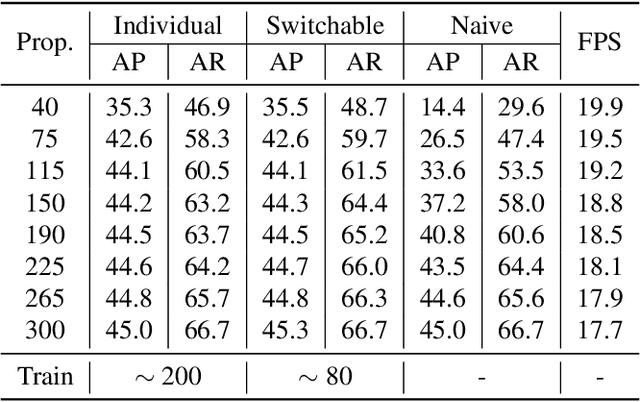
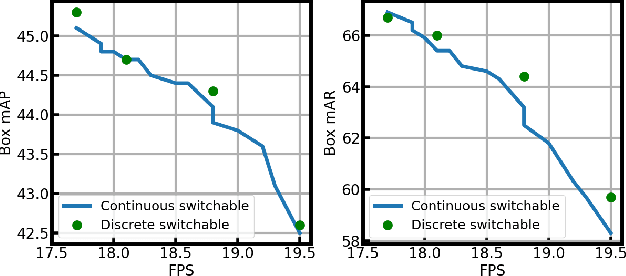
Object detection is a basic computer vision task to loccalize and categorize objects in a given image. Most state-of-the-art detection methods utilize a fixed number of proposals as an intermediate representation of object candidates, which is unable to adapt to different computational constraints during inference. In this paper, we propose a simple yet effective method which is adaptive to different computational resources by generating dynamic proposals for object detection. We first design a module to make a single query-based model to be able to inference with different numbers of proposals. Further, we extend it to a dynamic model to choose the number of proposals according to the input image, greatly reducing computational costs. Our method achieves significant speed-up across a wide range of detection models including two-stage and query-based models while obtaining similar or even better accuracy.
Residual Local Feature Network for Efficient Super-Resolution
May 16, 2022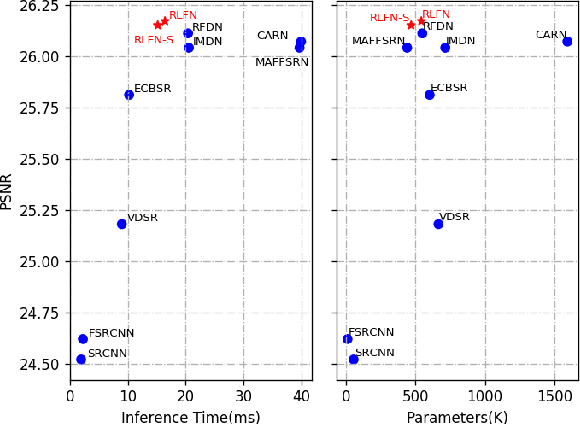
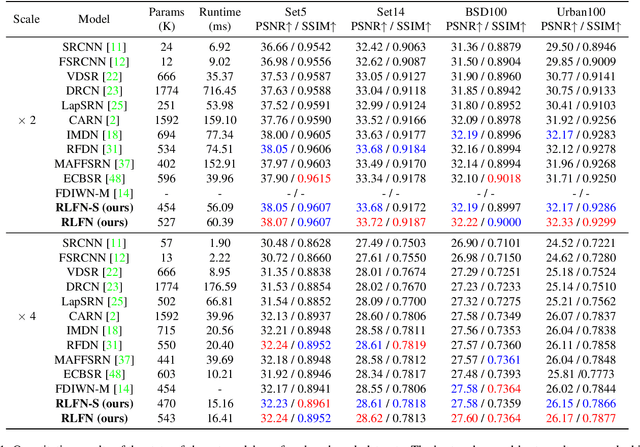
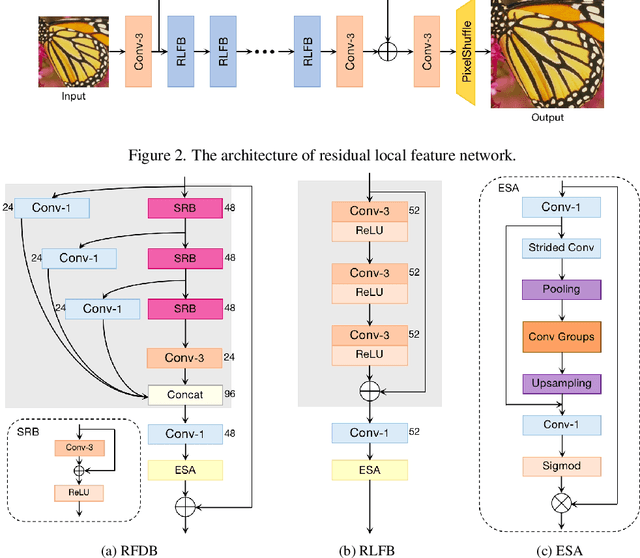
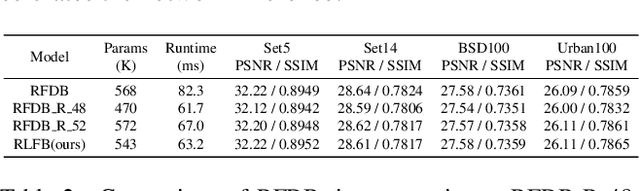
Deep learning based approaches has achieved great performance in single image super-resolution (SISR). However, recent advances in efficient super-resolution focus on reducing the number of parameters and FLOPs, and they aggregate more powerful features by improving feature utilization through complex layer connection strategies. These structures may not be necessary to achieve higher running speed, which makes them difficult to be deployed to resource-constrained devices. In this work, we propose a novel Residual Local Feature Network (RLFN). The main idea is using three convolutional layers for residual local feature learning to simplify feature aggregation, which achieves a good trade-off between model performance and inference time. Moreover, we revisit the popular contrastive loss and observe that the selection of intermediate features of its feature extractor has great influence on the performance. Besides, we propose a novel multi-stage warm-start training strategy. In each stage, the pre-trained weights from previous stages are utilized to improve the model performance. Combined with the improved contrastive loss and training strategy, the proposed RLFN outperforms all the state-of-the-art efficient image SR models in terms of runtime while maintaining both PSNR and SSIM for SR. In addition, we won the first place in the runtime track of the NTIRE 2022 efficient super-resolution challenge. Code will be available at https://github.com/fyan111/RLFN.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.