 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Implicit Aggregation: Robust Image Representation for Place Recognition in the Transformer Era
Nov 08, 2025Visual place recognition (VPR) is typically regarded as a specific image retrieval task, whose core lies in representing images as global descriptors. Over the past decade, dominant VPR methods (e.g., NetVLAD) have followed a paradigm that first extracts the patch features/tokens of the input image using a backbone, and then aggregates these patch features into a global descriptor via an aggregator. This backbone-plus-aggregator paradigm has achieved overwhelming dominance in the CNN era and remains widely used in transformer-based models. In this paper, however, we argue that a dedicated aggregator is not necessary in the transformer era, that is, we can obtain robust global descriptors only with the backbone. Specifically, we introduce some learnable aggregation tokens, which are prepended to the patch tokens before a particular transformer block. All these tokens will be jointly processed and interact globally via the intrinsic self-attention mechanism, implicitly aggregating useful information within the patch tokens to the aggregation tokens. Finally, we only take these aggregation tokens from the last output tokens and concatenate them as the global representation. Although implicit aggregation can provide robust global descriptors in an extremely simple manner, where and how to insert additional tokens, as well as the initialization of tokens, remains an open issue worthy of further exploration. To this end, we also propose the optimal token insertion strategy and token initialization method derived from empirical studies. Experimental results show that our method outperforms state-of-the-art methods on several VPR datasets with higher efficiency and ranks 1st on the MSLS challenge leaderboard. The code is available at https://github.com/lu-feng/image.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025



Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.
FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Oct 14, 2025



Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving efficiency, scalability, and real-time performance. To this end, we propose FlashVSR, the first diffusion-based one-step streaming framework towards real-time VSR. FlashVSR runs at approximately 17 FPS for 768x1408 videos on a single A100 GPU by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train-test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct VSR-120K, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves state-of-the-art performance with up to 12x speedup over prior one-step diffusion VSR models. We will release the code, pretrained models, and dataset to foster future research in efficient diffusion-based VSR.
Unified and Semantically Grounded Domain Adaptation for Medical Image Segmentation
Aug 12, 2025



Most prior unsupervised domain adaptation approaches for medical image segmentation are narrowly tailored to either the source-accessible setting, where adaptation is guided by source-target alignment, or the source-free setting, which typically resorts to implicit supervision mechanisms such as pseudo-labeling and model distillation. This substantial divergence in methodological designs between the two settings reveals an inherent flaw: the lack of an explicit, structured construction of anatomical knowledge that naturally generalizes across domains and settings. To bridge this longstanding divide, we introduce a unified, semantically grounded framework that supports both source-accessible and source-free adaptation. Fundamentally distinct from all prior works, our framework's adaptability emerges naturally as a direct consequence of the model architecture, without the need for any handcrafted adaptation strategies. Specifically, our model learns a domain-agnostic probabilistic manifold as a global space of anatomical regularities, mirroring how humans establish visual understanding. Thus, the structural content in each image can be interpreted as a canonical anatomy retrieved from the manifold and a spatial transformation capturing individual-specific geometry. This disentangled, interpretable formulation enables semantically meaningful prediction with intrinsic adaptability. Extensive experiments on challenging cardiac and abdominal datasets show that our framework achieves state-of-the-art results in both settings, with source-free performance closely approaching its source-accessible counterpart, a level of consistency rarely observed in prior works. Beyond quantitative improvement, we demonstrate strong interpretability of the proposed framework via manifold traversal for smooth shape manipulation.
Text-guided Visual Prompt DINO for Generic Segmentation
Aug 08, 2025



Recent advancements in multimodal vision models have highlighted limitations in late-stage feature fusion and suboptimal query selection for hybrid prompts open-world segmentation, alongside constraints from caption-derived vocabularies. To address these challenges, we propose Prompt-DINO, a text-guided visual Prompt DINO framework featuring three key innovations. First, we introduce an early fusion mechanism that unifies text/visual prompts and backbone features at the initial encoding stage, enabling deeper cross-modal interactions to resolve semantic ambiguities. Second, we design order-aligned query selection for DETR-based architectures, explicitly optimizing the structural alignment between text and visual queries during decoding to enhance semantic-spatial consistency. Third, we develop a generative data engine powered by the Recognize Anything via Prompting (RAP) model, which synthesizes 0.5B diverse training instances through a dual-path cross-verification pipeline, reducing label noise by 80.5% compared to conventional approaches. Extensive experiments demonstrate that Prompt-DINO achieves state-of-the-art performance on open-world detection benchmarks while significantly expanding semantic coverage beyond fixed-vocabulary constraints. Our work establishes a new paradigm for scalable multimodal detection and data generation in open-world scenarios. Data&Code are available at https://github.com/WeChatCV/WeVisionOne.
UniGlyph: Unified Segmentation-Conditioned Diffusion for Precise Visual Text Synthesis
Jul 02, 2025Text-to-image generation has greatly advanced content creation, yet accurately rendering visual text remains a key challenge due to blurred glyphs, semantic drift, and limited style control. Existing methods often rely on pre-rendered glyph images as conditions, but these struggle to retain original font styles and color cues, necessitating complex multi-branch designs that increase model overhead and reduce flexibility. To address these issues, we propose a segmentation-guided framework that uses pixel-level visual text masks -- rich in glyph shape, color, and spatial detail -- as unified conditional inputs. Our method introduces two core components: (1) a fine-tuned bilingual segmentation model for precise text mask extraction, and (2) a streamlined diffusion model augmented with adaptive glyph conditioning and a region-specific loss to preserve textual fidelity in both content and style. Our approach achieves state-of-the-art performance on the AnyText benchmark, significantly surpassing prior methods in both Chinese and English settings. To enable more rigorous evaluation, we also introduce two new benchmarks: GlyphMM-benchmark for testing layout and glyph consistency in complex typesetting, and MiniText-benchmark for assessing generation quality in small-scale text regions. Experimental results show that our model outperforms existing methods by a large margin in both scenarios, particularly excelling at small text rendering and complex layout preservation, validating its strong generalization and deployment readiness.
SCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought
May 30, 2025Chain of Thought (CoT) prompting improves the reasoning performance of large language models (LLMs) by encouraging step by step thinking. However, CoT-based methods depend on intermediate reasoning steps, which limits scalability and generalization. Recent work explores recursive reasoning, where LLMs reuse internal layers across iterations to refine latent representations without explicit CoT supervision. While promising, these approaches often require costly pretraining and lack a principled framework for how reasoning should evolve across iterations. We address this gap by introducing Flow Chain of Thought (Flow CoT), a reasoning paradigm that models recursive inference as a progressive trajectory of latent cognitive states. Flow CoT frames each iteration as a distinct cognitive stage deepening reasoning across iterations without relying on manual supervision. To realize this, we propose SCOUT (Stepwise Cognitive Optimization Using Teachers), a lightweight fine tuning framework that enables Flow CoT style reasoning without the need for pretraining. SCOUT uses progressive distillation to align each iteration with a teacher of appropriate capacity, and a cross attention based retrospective module that integrates outputs from previous iterations while preserving the models original computation flow. Experiments across eight reasoning benchmarks show that SCOUT consistently improves both accuracy and explanation quality, achieving up to 1.8% gains under fine tuning. Qualitative analyses further reveal that SCOUT enables progressively deeper reasoning across iterations refining both belief formation and explanation granularity. These results not only validate the effectiveness of SCOUT, but also demonstrate the practical viability of Flow CoT as a scalable framework for enhancing reasoning in LLMs.
A Simple Linear Patch Revives Layer-Pruned Large Language Models
May 30, 2025



Layer pruning has become a popular technique for compressing large language models (LLMs) due to its simplicity. However, existing layer pruning methods often suffer from significant performance drops. We identify that this degradation stems from the mismatch of activation magnitudes across layers and tokens at the pruning interface. To address this, we propose LinearPatch, a simple plug-and-play technique to revive the layer-pruned LLMs. The proposed method adopts Hadamard transformation to suppress massive outliers in particular tokens, and channel-wise scaling to align the activation magnitudes. These operations can be fused into a single matrix, which functions as a patch to bridge the pruning interface with negligible inference overhead. LinearPatch retains up to 94.15% performance of the original model when pruning 5 layers of LLaMA-3-8B on the question answering benchmark, surpassing existing state-of-the-art methods by 4%. In addition, the patch matrix can be further optimized with memory efficient offline knowledge distillation. With only 5K samples, the retained performance of LinearPatch can be further boosted to 95.16% within 30 minutes on a single computing card.
CLIP-AE: CLIP-assisted Cross-view Audio-Visual Enhancement for Unsupervised Temporal Action Localization
May 29, 2025Temporal Action Localization (TAL) has garnered significant attention in information retrieval. Existing supervised or weakly supervised methods heavily rely on labeled temporal boundaries and action categories, which are labor-intensive and time-consuming. Consequently, unsupervised temporal action localization (UTAL) has gained popularity. However, current methods face two main challenges: 1) Classification pre-trained features overly focus on highly discriminative regions; 2) Solely relying on visual modality information makes it difficult to determine contextual boundaries. To address these issues, we propose a CLIP-assisted cross-view audiovisual enhanced UTAL method. Specifically, we introduce visual language pre-training (VLP) and classification pre-training-based collaborative enhancement to avoid excessive focus on highly discriminative regions; we also incorporate audio perception to provide richer contextual boundary information. Finally, we introduce a self-supervised cross-view learning paradigm to achieve multi-view perceptual enhancement without additional annotations. Extensive experiments on two public datasets demonstrate our model's superiority over several state-of-the-art competitors.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025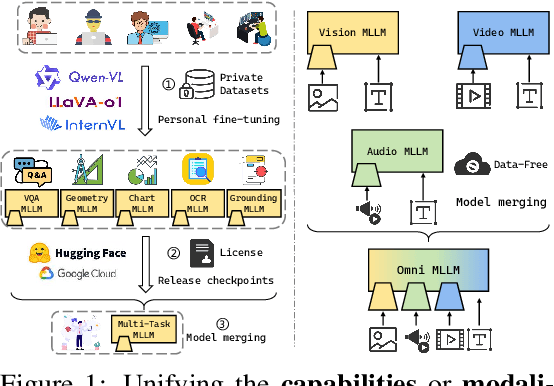

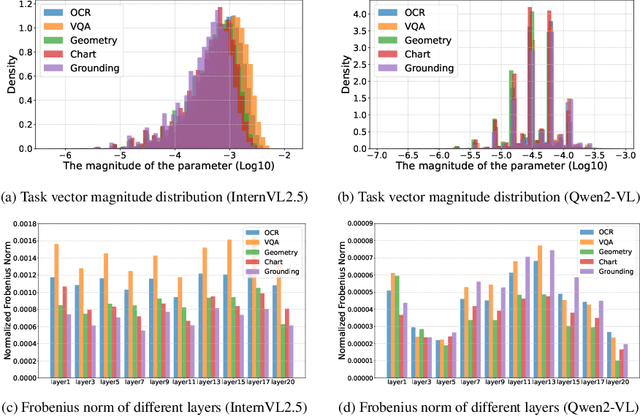
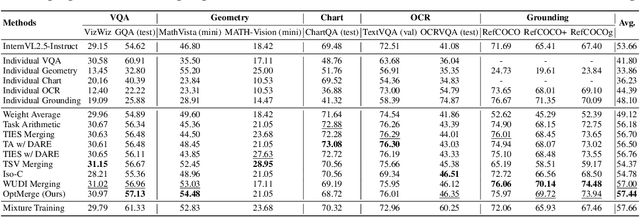
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.