 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-Form Spectral Regularization for Multi-Task Model Merging
Jun 05, 2026Model merging combines several independently fine-tuned experts into a single multi-task model without any training data, reducing the storage, serving, and decentralized-development costs of large foundation models. State-of-the-art merging methods formulate merging as a layer-wise quadratic interference minimization problem. Although this problem admits an exact closed-form pseudoinverse solution, that solution underperforms hundreds of iterations of gradient descent in practice. The iterative loop dominates the cost of the pipeline, yet its effectiveness has remained unexplained. We revisit this regime and show that the iterative solver does not primarily act as an optimizer; rather, it serves as an implicit spectral regularizer for an ill-posed normal equation, where small-eigenvalue directions of the per-layer interference operator amplify proxy noise. Building on this finding, we formalize multi-task model merging as a noisy linear inverse problem and propose a spectral filtering estimator parameterized by a per-direction filter. We instantiate this estimator with SWUDI, a closed-form method that combines a soft exponential filter, which matches the gradient-flow trajectory of iterative descent, with a hard top-K truncation that suppresses noise-amplifying small-eigenvalue directions. Furthermore, we propose SWUDI-A, an adaptive variant that replaces the global rank hyperparameter with per-layer rank rules, further improving robustness across architectures. Both variants share a single symmetric eigendecomposition per linear layer and require no training data or optimizer state. Across four general benchmarks and a multimodal merging benchmark spanning VQA, Geometry, Chart, OCR, Grounding, and modality merging, our proposed spectral solvers match or outperform state-of-the-art merging methods. Crucially, they reduce wall-clock time by 28-72x and peak GPU memory by up to 50%.
Memory Grafting: Scaling Language Model Pre-training via Offline Conditional Memory
May 20, 2026Scaling conditional memory offers a promising way to increase language-model capacity, but existing methods such as Engram learn large memory tables from scratch during pre-training, making memory scaling expensive and sometimes ineffective. We propose Memory Grafting, a conditional memory scaling method that utilizes frozen hidden states from a grafting model as conditional n-gram memory. Given frequent local n-grams, we run the grafting model offline, store final-token hidden representations as memory values, and let the recipient model retrieve them through exact longest-match suffix lookup. Retrieved memories are adapted by lightweight projections and gates, while a hash-based Engram fallback preserves coverage for unmatched contexts. Since the grafting model is only run offline and exact lookup has expected O(1) complexity with respect to memory-bank size, Memory Grafting expands external latent capacity with limited training and inference overhead. Experiments under matched recipient architectures and pre-training budgets show that Memory Grafting improves over both MoE and vanilla Engram baselines. In the 2.8B-scale setting, it improves the average benchmark score from 51.95 for MoE and 52.43 for vanilla Engram to 53.86. In the 0.92B-scale setting, all grafting-model variants improve over the baselines, with Qwen3.5-35B-A3B giving the strongest gains. These results suggest that pretrained models can serve as reusable constructors of external latent memory, providing a practical step toward scaling future language models beyond trainable parameters alone.
Spectral Characterization and Mitigation of Sequential Knowledge Editing Collapse
Jan 16, 2026Sequential knowledge editing in large language models often causes catastrophic collapse of the model's general abilities, especially for parameter-modifying methods. Existing approaches mitigate this issue through heuristic constraints on parameter updates, yet the mechanisms underlying such degradation remain insufficiently understood. In this work, we present a spectral analysis of sequential knowledge editing and show that a model's general abilities are closely associated with dominant singular directions of pretrained weight matrices. These directions are highly sensitive to perturbations and are progressively disrupted by repeated edits, closely tracking the collapse in both editing efficacy and general performance. Building on this insight, we propose REVIVE, a plug-and-play framework that stabilizes sequential editing by explicitly preserving the dominant singular subspace. REVIVE represents parameter updates in the spectral basis of the original weights and filters components that would interfere with the protected region. Extensive experiments across multiple models and benchmarks show that REVIVE consistently improves editing efficacy while substantially preserving general abilities under long-horizon sequential editing, including extreme settings with up to 20,000 edits.
Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models
Nov 13, 2025



Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data bootstrap problem-design strategies from the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our method achieves an average improvement of 2.5% and generalizes to both language and vision-language models. Moreover, a solver trained on the synthesized data provides improved rewards for continued generator training, enabling co-evolution and yielding a further 0.7% performance gain. Our code will be made publicly available here.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025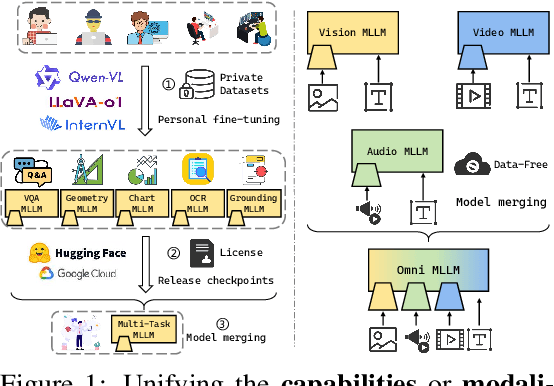

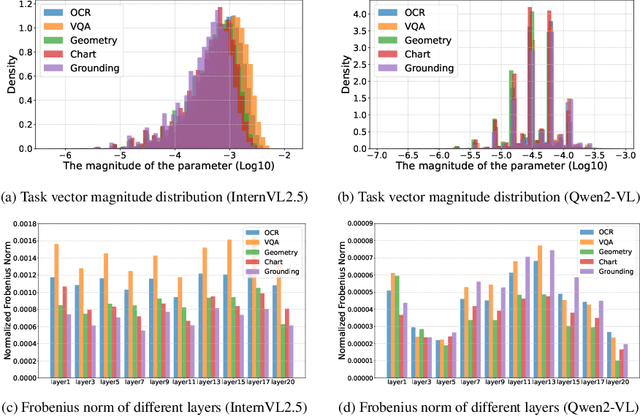
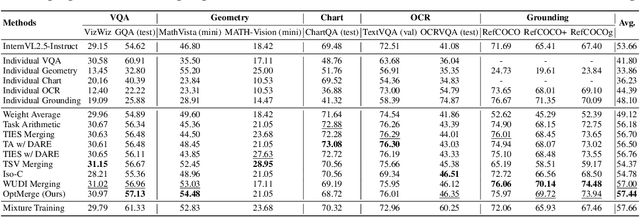
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
HS-STAR: Hierarchical Sampling for Self-Taught Reasoners via Difficulty Estimation and Budget Reallocation
May 26, 2025Self-taught reasoners (STaRs) enhance the mathematical reasoning abilities of large language models (LLMs) by leveraging self-generated responses for self-training. Recent studies have incorporated reward models to guide response selection or decoding, aiming to obtain higher-quality data. However, they typically allocate a uniform sampling budget across all problems, overlooking the varying utility of problems at different difficulty levels. In this work, we conduct an empirical study and find that problems near the boundary of the LLM's reasoning capability offer significantly greater learning utility than both easy and overly difficult ones. To identify and exploit such problems, we propose HS-STaR, a Hierarchical Sampling framework for Self-Taught Reasoners. Given a fixed sampling budget, HS-STaR first performs lightweight pre-sampling with a reward-guided difficulty estimation strategy to efficiently identify boundary-level problems. Subsequently, it dynamically reallocates the remaining budget toward these high-utility problems during a re-sampling phase, maximizing the generation of valuable training data. Extensive experiments across multiple reasoning benchmarks and backbone LLMs demonstrate that HS-STaR significantly outperforms other baselines without requiring additional sampling budget.
Whoever Started the Interference Should End It: Guiding Data-Free Model Merging via Task Vectors
Mar 11, 2025



Model merging seeks to integrate task-specific expert models into a unified architecture while preserving multi-task generalization capabilities, yet parameter interference between constituent models frequently induces performance degradation. Although prior work has explored many merging strategies, resolving interference without additional data for retraining or test-time computation remains challenging. In this paper, we theoretically demonstrate that the task vectors of the linear layer constitute an approximate linear subspace for its corresponding input. Therefore, we can minimize interference under the guidance of task vectors. Based on this insight, we propose \textbf{WUDI-Merging} (\textbf{W}hoever started the interference sho\textbf{U}ld en\textbf{D} \textbf{I}t), a simple yet effective model merging method that eliminates interference without any additional data or rescaling coefficients. Comprehensive empirical evaluations across vision and language benchmarks demonstrate our method's superiority, achieving state-of-the-art performance in data-free model merging scenarios (average 10.9\% improvement versus baseline methods) while even outperforming mainstream test-time adaptation approaches by 3.3\%, and only very few computing resources are required. The code will be publicly available soon.
Multi-Task Model Merging via Adaptive Weight Disentanglement
Nov 27, 2024



Model merging has gained increasing attention as an efficient and effective technique for integrating task-specific weights from various tasks into a unified multi-task model without retraining or additional data. As a representative approach, Task Arithmetic (TA) has demonstrated that combining task vectors through arithmetic operations facilitates efficient capability transfer between different tasks. In this framework, task vectors are obtained by subtracting the parameter values of a pre-trained model from those of individually fine-tuned models initialized from it. Despite the notable effectiveness of TA, interference among task vectors can adversely affect the performance of the merged model. In this paper, we relax the constraints of Task Arithmetic Property and propose Task Consistency Property, which can be regarded as being free from task interference. Through theoretical derivation, we show that such a property can be approximately achieved by seeking orthogonal task vectors. Guiding by this insight, we propose Adaptive Weight Disentanglement (AWD), which decomposes traditional task vectors into a redundant vector and several disentangled task vectors. The primary optimization objective of AWD is to achieve orthogonality among the disentangled task vectors, thereby closely approximating the desired solution. Notably, these disentangled task vectors can be seamlessly integrated into existing merging methodologies. Experimental results demonstrate that our AWD consistently and significantly improves upon previous merging approaches, achieving state-of-the-art results. Our code is available at \href{https://github.com/FarisXiong/AWD.git}{https://github.com/FarisXiong/AWD.git}.
Kendall's $τ$ Coefficient for Logits Distillation
Sep 26, 2024



Knowledge distillation typically employs the Kullback-Leibler (KL) divergence to constrain the student model's output to match the soft labels provided by the teacher model exactly. However, sometimes the optimization direction of the KL divergence loss is not always aligned with the task loss, where a smaller KL divergence could lead to erroneous predictions that diverge from the soft labels. This limitation often results in suboptimal optimization for the student. Moreover, even under temperature scaling, the KL divergence loss function tends to overly focus on the larger-valued channels in the logits, disregarding the rich inter-class information provided by the multitude of smaller-valued channels. This hard constraint proves too challenging for lightweight students, hindering further knowledge distillation. To address this issue, we propose a plug-and-play ranking loss based on Kendall's $\tau$ coefficient, called Rank-Kendall Knowledge Distillation (RKKD). RKKD balances the attention to smaller-valued channels by constraining the order of channel values in student logits, providing more inter-class relational information. The rank constraint on the top-valued channels helps avoid suboptimal traps during optimization. We also discuss different differentiable forms of Kendall's $\tau$ coefficient and demonstrate that the proposed ranking loss function shares a consistent optimization objective with the KL divergence. Extensive experiments on the CIFAR-100 and ImageNet datasets show that our RKKD can enhance the performance of various knowledge distillation baselines and offer broad improvements across multiple teacher-student architecture combinations.
Learn To Learn More Precisely
Aug 08, 2024



Meta-learning has been extensively applied in the domains of few-shot learning and fast adaptation, achieving remarkable performance. While Meta-learning methods like Model-Agnostic Meta-Learning (MAML) and its variants provide a good set of initial parameters for the model, the model still tends to learn shortcut features, which leads to poor generalization. In this paper, we propose the formal conception of "learn to learn more precisely", which aims to make the model learn precise target knowledge from data and reduce the effect of noisy knowledge, such as background and noise. To achieve this target, we proposed a simple and effective meta-learning framework named Meta Self-Distillation(MSD) to maximize the consistency of learned knowledge, enhancing the models' ability to learn precise target knowledge. In the inner loop, MSD uses different augmented views of the same support data to update the model respectively. Then in the outer loop, MSD utilizes the same query data to optimize the consistency of learned knowledge, enhancing the model's ability to learn more precisely. Our experiment demonstrates that MSD exhibits remarkable performance in few-shot classification tasks in both standard and augmented scenarios, effectively boosting the accuracy and consistency of knowledge learned by the model.