 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners
May 14, 2026Recent unified models integrate multimodal understanding and generation within a single framework. However, an "understanding-generation gap" persists, where models can capture user intent but often fail to translate this semantic knowledge into precise pixel-level manipulation. This gap results in two bottlenecks in anything-to-image task (X2I): the attention entanglement bottleneck, where blind planning struggles with complex prompts, and the visual refinement bottleneck, where unstructured feedback fails to correct imperfections efficiently. In this paper, we propose a novel framework that empowers unified models to autonomously switch between generation strategies based on instruction complexity and model capability. To achieve this, we construct a hierarchical data pipeline that constructs execution paths across three adaptive modes: direct generation for simple cases, self-reflection for quality refinement, and multi-step planning for decomposing complex scenarios. Building on this pipeline, we contribute a high-quality dataset with over 50,000 samples and implement a two-stage training strategy comprising SFT and RL. Specifically, we design step-wise reasoning rewards to ensure logical consistency and intra-group complexity penalty to prevent redundant computational overhead. Extensive experiments demonstrate that our method outperforms existing baselines on X2I, achieving superior generation fidelity among simple-to-complex instructions. The code is released at https://github.com/WeChatCV/Interleaved_Visual_Reasoner.
Text-guided Visual Prompt DINO for Generic Segmentation
Aug 08, 2025



Recent advancements in multimodal vision models have highlighted limitations in late-stage feature fusion and suboptimal query selection for hybrid prompts open-world segmentation, alongside constraints from caption-derived vocabularies. To address these challenges, we propose Prompt-DINO, a text-guided visual Prompt DINO framework featuring three key innovations. First, we introduce an early fusion mechanism that unifies text/visual prompts and backbone features at the initial encoding stage, enabling deeper cross-modal interactions to resolve semantic ambiguities. Second, we design order-aligned query selection for DETR-based architectures, explicitly optimizing the structural alignment between text and visual queries during decoding to enhance semantic-spatial consistency. Third, we develop a generative data engine powered by the Recognize Anything via Prompting (RAP) model, which synthesizes 0.5B diverse training instances through a dual-path cross-verification pipeline, reducing label noise by 80.5% compared to conventional approaches. Extensive experiments demonstrate that Prompt-DINO achieves state-of-the-art performance on open-world detection benchmarks while significantly expanding semantic coverage beyond fixed-vocabulary constraints. Our work establishes a new paradigm for scalable multimodal detection and data generation in open-world scenarios. Data&Code are available at https://github.com/WeChatCV/WeVisionOne.
WeTok: Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
Aug 07, 2025Visual tokenizer is a critical component for vision generation. However, the existing tokenizers often face unsatisfactory trade-off between compression ratios and reconstruction fidelity. To fill this gap, we introduce a powerful and concise WeTok tokenizer, which surpasses the previous leading tokenizers via two core innovations. (1) Group-wise lookup-free Quantization (GQ). We partition the latent features into groups, and perform lookup-free quantization for each group. As a result, GQ can efficiently overcome memory and computation limitations of prior tokenizers, while achieving a reconstruction breakthrough with more scalable codebooks. (2) Generative Decoding (GD). Different from prior tokenizers, we introduce a generative decoder with a prior of extra noise variable. In this case, GD can probabilistically model the distribution of visual data conditioned on discrete tokens, allowing WeTok to reconstruct visual details, especially at high compression ratios. Extensive experiments on mainstream benchmarks show superior performance of our WeTok. On the ImageNet 50k validation set, WeTok achieves a record-low zero-shot rFID (WeTok: 0.12 vs. FLUX-VAE: 0.18 vs. SD-VAE 3.5: 0.19). Furthermore, our highest compression model achieves a zero-shot rFID of 3.49 with a compression ratio of 768, outperforming Cosmos (384) 4.57 which has only 50% compression rate of ours. Code and models are available: https://github.com/zhuangshaobin/WeTok.
LIT-LVM: Structured Regularization for Interaction Terms in Linear Predictors using Latent Variable Models
Jun 18, 2025Some of the simplest, yet most frequently used predictors in statistics and machine learning use weighted linear combinations of features. Such linear predictors can model non-linear relationships between features by adding interaction terms corresponding to the products of all pairs of features. We consider the problem of accurately estimating coefficients for interaction terms in linear predictors. We hypothesize that the coefficients for different interaction terms have an approximate low-dimensional structure and represent each feature by a latent vector in a low-dimensional space. This low-dimensional representation can be viewed as a structured regularization approach that further mitigates overfitting in high-dimensional settings beyond standard regularizers such as the lasso and elastic net. We demonstrate that our approach, called LIT-LVM, achieves superior prediction accuracy compared to elastic net and factorization machines on a wide variety of simulated and real data, particularly when the number of interaction terms is high compared to the number of samples. LIT-LVM also provides low-dimensional latent representations for features that are useful for visualizing and analyzing their relationships.
Video-GPT via Next Clip Diffusion
May 18, 2025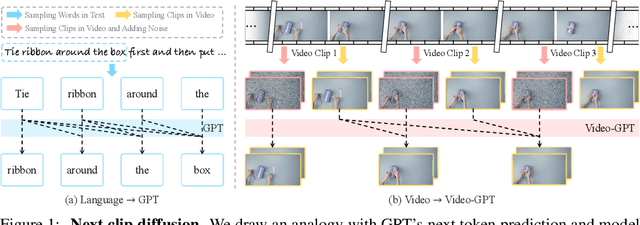

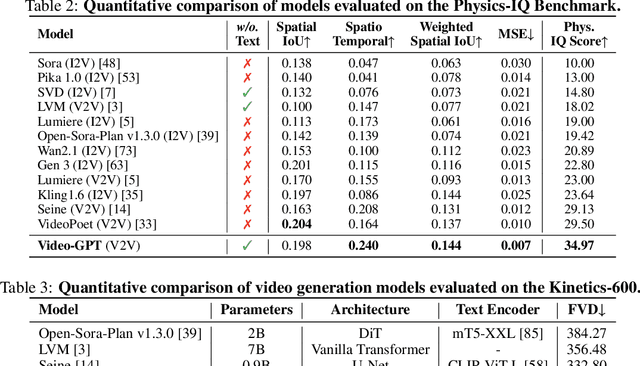
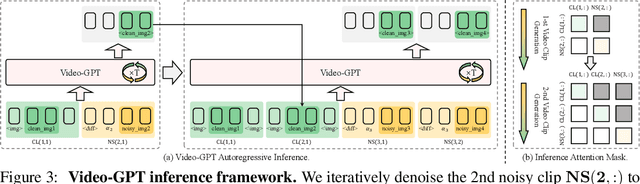
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.
Get In Video: Add Anything You Want to the Video
Mar 08, 2025



Video editing increasingly demands the ability to incorporate specific real-world instances into existing footage, yet current approaches fundamentally fail to capture the unique visual characteristics of particular subjects and ensure natural instance/scene interactions. We formalize this overlooked yet critical editing paradigm as "Get-In-Video Editing", where users provide reference images to precisely specify visual elements they wish to incorporate into videos. Addressing this task's dual challenges, severe training data scarcity and technical challenges in maintaining spatiotemporal coherence, we introduce three key contributions. First, we develop GetIn-1M dataset created through our automated Recognize-Track-Erase pipeline, which sequentially performs video captioning, salient instance identification, object detection, temporal tracking, and instance removal to generate high-quality video editing pairs with comprehensive annotations (reference image, tracking mask, instance prompt). Second, we present GetInVideo, a novel end-to-end framework that leverages a diffusion transformer architecture with 3D full attention to process reference images, condition videos, and masks simultaneously, maintaining temporal coherence, preserving visual identity, and ensuring natural scene interactions when integrating reference objects into videos. Finally, we establish GetInBench, the first comprehensive benchmark for Get-In-Video Editing scenario, demonstrating our approach's superior performance through extensive evaluations. Our work enables accessible, high-quality incorporation of specific real-world subjects into videos, significantly advancing personalized video editing capabilities.
WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
Mar 03, 2025Existing multimodal generative models fall short as qualified design copilots, as they often struggle to generate imaginative outputs once instructions are less detailed or lack the ability to maintain consistency with the provided references. In this work, we introduce WeGen, a model that unifies multimodal generation and understanding, and promotes their interplay in iterative generation. It can generate diverse results with high creativity for less detailed instructions. And it can progressively refine prior generation results or integrating specific contents from references following the instructions in its chat with users. During this process, it is capable of preserving consistency in the parts that the user is already satisfied with. To this end, we curate a large-scale dataset, extracted from Internet videos, containing rich object dynamics and auto-labeled dynamics descriptions by advanced foundation models to date. These two information are interleaved into a single sequence to enable WeGen to learn consistency-aware generation where the specified dynamics are generated while the consistency of unspecified content is preserved aligned with instructions. Besides, we introduce a prompt self-rewriting mechanism to enhance generation diversity. Extensive experiments demonstrate the effectiveness of unifying multimodal understanding and generation in WeGen and show it achieves state-of-the-art performance across various visual generation benchmarks. These also demonstrate the potential of WeGen as a user-friendly design copilot as desired. The code and models will be available at https://github.com/hzphzp/WeGen.
RoomPainter: View-Integrated Diffusion for Consistent Indoor Scene Texturing
Dec 21, 2024Indoor scene texture synthesis has garnered significant interest due to its important potential applications in virtual reality, digital media, and creative arts. Existing diffusion model-based researches either rely on per-view inpainting techniques, which are plagued by severe cross-view inconsistencies and conspicuous seams, or they resort to optimization-based approaches that entail substantial computational overhead. In this work, we present RoomPainter, a framework that seamlessly integrates efficiency and consistency to achieve high-fidelity texturing of indoor scenes. The core of RoomPainter features a zero-shot technique that effectively adapts a 2D diffusion model for 3D-consistent texture synthesis, along with a two-stage generation strategy that ensures both global and local consistency. Specifically, we introduce Attention-Guided Multi-View Integrated Sampling (MVIS) combined with a neighbor-integrated attention mechanism for zero-shot texture map generation. Using the MVIS, we firstly generate texture map for the entire room to ensure global consistency, then adopt its variant, namely an attention-guided multi-view integrated repaint sampling (MVRS) to repaint individual instances within the room, thereby further enhancing local consistency. Experiments demonstrate that RoomPainter achieves superior performance for indoor scene texture synthesis in visual quality, global consistency, and generation efficiency.
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Sep 03, 2024



Despite recent advancements in neural 3D reconstruction, the dependence on dense multi-view captures restricts their broader applicability. In this work, we propose \textbf{ViewCrafter}, a novel method for synthesizing high-fidelity novel views of generic scenes from single or sparse images with the prior of video diffusion model. Our method takes advantage of the powerful generation capabilities of video diffusion model and the coarse 3D clues offered by point-based representation to generate high-quality video frames with precise camera pose control. To further enlarge the generation range of novel views, we tailored an iterative view synthesis strategy together with a camera trajectory planning algorithm to progressively extend the 3D clues and the areas covered by the novel views. With ViewCrafter, we can facilitate various applications, such as immersive experiences with real-time rendering by efficiently optimizing a 3D-GS representation using the reconstructed 3D points and the generated novel views, and scene-level text-to-3D generation for more imaginative content creation. Extensive experiments on diverse datasets demonstrate the strong generalization capability and superior performance of our method in synthesizing high-fidelity and consistent novel views.
Converting High-Performance and Low-Latency SNNs through Explicit Modelling of Residual Error in ANNs
Apr 26, 2024



Spiking neural networks (SNNs) have garnered interest due to their energy efficiency and superior effectiveness on neuromorphic chips compared with traditional artificial neural networks (ANNs). One of the mainstream approaches to implementing deep SNNs is the ANN-SNN conversion, which integrates the efficient training strategy of ANNs with the energy-saving potential and fast inference capability of SNNs. However, under extreme low-latency conditions, the existing conversion theory suggests that the problem of misrepresentation of residual membrane potentials in SNNs, i.e., the inability of IF neurons with a reset-by-subtraction mechanism to respond to residual membrane potentials beyond the range from resting potential to threshold, leads to a performance gap in the converted SNNs compared to the original ANNs. This severely limits the possibility of practical application of SNNs on delay-sensitive edge devices. Existing conversion methods addressing this problem usually involve modifying the state of the conversion spiking neurons. However, these methods do not consider their adaptability and compatibility with neuromorphic chips. We propose a new approach based on explicit modeling of residual errors as additive noise. The noise is incorporated into the activation function of the source ANN, which effectively reduces the residual error. Our experiments on the CIFAR10/100 dataset verify that our approach exceeds the prevailing ANN-SNN conversion methods and directly trained SNNs concerning accuracy and the required time steps. Overall, our method provides new ideas for improving SNN performance under ultra-low-latency conditions and is expected to promote practical neuromorphic hardware applications for further development.