 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCL-COD: Weakly Supervised Camouflaged Object Detection with Frequency-aware and Contrastive Learning
Mar 24, 2026Existing camouflage object detection (COD) methods typically rely on fully-supervised learning guided by mask annotations. However, obtaining mask annotations is time-consuming and labor-intensive. Compared to fully-supervised methods, existing weakly-supervised COD methods exhibit significantly poorer performance. Even for the Segment Anything Model (SAM), there are still challenges in handling weakly-supervised camouflage object detection (WSCOD), such as: a. non-camouflage target responses, b. local responses, c. extreme responses, and d. lack of refined boundary awareness, which leads to unsatisfactory results in camouflage scenes. To alleviate these issues, we propose a frequency-aware and contrastive learning-based WSCOD framework in this paper, named FCL-COD. To mitigate the problem of non-camouflaged object responses, we propose the Frequency-aware Low-rank Adaptation (FoRA) method, which incorporates frequency-aware camouflage scene knowledge into SAM. To overcome the challenges of local and extreme responses, we introduce a gradient-aware contrastive learning approach that effectively delineates precise foreground-background boundaries. Additionally, to address the lack of refined boundary perception, we present a multi-scale frequency-aware representation learning strategy that facilitates the modeling of more refined boundaries. We validate the effectiveness of our approach through extensive empirical experiments on three widely recognized COD benchmarks. The results confirm that our method surpasses both state-of-the-art weakly supervised and even fully supervised techniques.
CLIP-AE: CLIP-assisted Cross-view Audio-Visual Enhancement for Unsupervised Temporal Action Localization
May 29, 2025Temporal Action Localization (TAL) has garnered significant attention in information retrieval. Existing supervised or weakly supervised methods heavily rely on labeled temporal boundaries and action categories, which are labor-intensive and time-consuming. Consequently, unsupervised temporal action localization (UTAL) has gained popularity. However, current methods face two main challenges: 1) Classification pre-trained features overly focus on highly discriminative regions; 2) Solely relying on visual modality information makes it difficult to determine contextual boundaries. To address these issues, we propose a CLIP-assisted cross-view audiovisual enhanced UTAL method. Specifically, we introduce visual language pre-training (VLP) and classification pre-training-based collaborative enhancement to avoid excessive focus on highly discriminative regions; we also incorporate audio perception to provide richer contextual boundary information. Finally, we introduce a self-supervised cross-view learning paradigm to achieve multi-view perceptual enhancement without additional annotations. Extensive experiments on two public datasets demonstrate our model's superiority over several state-of-the-art competitors.
Off-Policy Evaluation of Probabilistic Identity Data in Lookalike Modeling
Jan 04, 2019
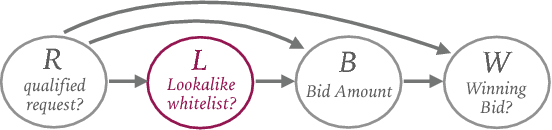
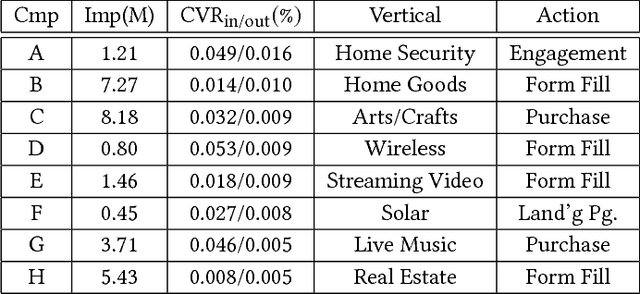
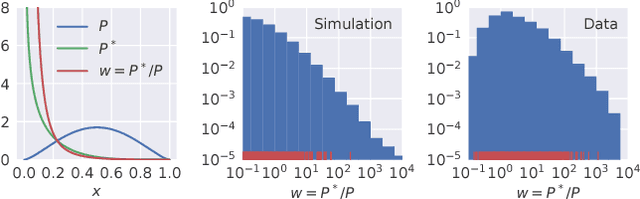
We evaluate the impact of probabilistically-constructed digital identity data collected from Sep. to Dec. 2017 (approx.), in the context of Lookalike-targeted campaigns. The backbone of this study is a large set of probabilistically-constructed "identities", represented as small bags of cookies and mobile ad identifiers with associated metadata, that are likely all owned by the same underlying user. The identity data allows to generate "identity-based", rather than "identifier-based", user models, giving a fuller picture of the interests of the users underlying the identifiers. We employ off-policy techniques to evaluate the potential of identity-powered lookalike models without incurring the risk of allowing untested models to direct large amounts of ad spend or the large cost of performing A/B tests. We add to historical work on off-policy evaluation by noting a significant type of "finite-sample bias" that occurs for studies combining modestly-sized datasets and evaluation metrics involving rare events (e.g., conversions). We illustrate this bias using a simulation study that later informs the handling of inverse propensity weights in our analyses on real data. We demonstrate significant lift in identity-powered lookalikes versus an identity-ignorant baseline: on average ~70% lift in conversion rate. This rises to factors of ~(4-32)x for identifiers having little data themselves, but that can be inferred to belong to users with substantial data to aggregate across identifiers. This implies that identity-powered user modeling is especially important in the context of identifiers having very short lifespans (i.e., frequently churned cookies). Our work motivates and informs the use of probabilistically-constructed identities in marketing. It also deepens the canon of examples in which off-policy learning has been employed to evaluate the complex systems of the internet economy.