 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting weight-space symmetries for approximating curvature
May 30, 2026Many machine learning techniques rely on approximating a loss function's curvature, but this is notoriously hard to do at the scale of modern deep networks. Surprisingly, no previous work has exploited the curvature constraints that arise from well known weight-space symmetries in loss landscapes. By analytically averaging over group actions that leave the loss invariant, we construct structured Hessian approximations from single gradients that can be tractably estimated, stored, and inverted. The choice of user-specified symmetry group directly governs the trade-off between approximation accuracy and computational cost. Moreover, our framework provides a unifying theoretical lens for viewing existing methods; in particular, a specific choice of symmetry group recovers Shampoo/Muon-like curvature estimates. We validate our method on a range of network architectures, and deploy it to second-order optimization benchmarks, including a small language model. Our curvature estimation framework might find applications in other machine learning problems such as uncertainty estimation, continual learning, compression/pruning, training data attribution, and more.
Optimizing RAG Rerankers with LLM Feedback via Reinforcement Learning
Apr 02, 2026Rerankers play a pivotal role in refining retrieval results for Retrieval-Augmented Generation. However, current reranking models are typically optimized on static human annotated relevance labels in isolation, decoupled from the downstream generation process. This isolation leads to a fundamental misalignment: documents identified as topically relevant by information retrieval metrics often fail to provide the actual utility required by the LLM for precise answer generation. To bridge this gap, we introduce ReRanking Preference Optimization (RRPO), a reinforcement learning framework that directly aligns reranking with the LLM's generation quality. By formulating reranking as a sequential decision-making process, RRPO optimizes for context utility using LLM feedback, thereby eliminating the need for expensive human annotations. To ensure training stability, we further introduce a reference-anchored deterministic baseline. Extensive experiments on knowledge-intensive benchmarks demonstrate that RRPO significantly outperforms strong baselines, including the powerful list-wise reranker RankZephyr. Further analysis highlights the versatility of our framework: it generalizes seamlessly to diverse readers (e.g., GPT-4o), integrates orthogonally with query expansion modules like Query2Doc, and remains robust even when trained with noisy supervisors.
Execution-Verified Reinforcement Learning for Optimization Modeling
Apr 01, 2026Automating optimization modeling with LLMs is a promising path toward scalable decision intelligence, but existing approaches either rely on agentic pipelines built on closed-source LLMs with high inference latency, or fine-tune smaller LLMs using costly process supervision that often overfits to a single solver API. Inspired by reinforcement learning with verifiable rewards, we propose Execution-Verified Optimization Modeling (EVOM), an execution-verified learning framework that treats a mathematical programming solver as a deterministic, interactive verifier. Given a natural-language problem and a target solver, EVOM generates solver-specific code, executes it in a sandboxed harness, and converts execution outcomes into scalar rewards, optimized with GRPO and DAPO in a closed-loop generate-execute-feedback-update process. This outcome-only formulation removes the need for process-level supervision, and enables cross-solver generalization by switching the verification environment rather than reconstructing solver-specific datasets. Experiments on NL4OPT, MAMO, IndustryOR, and OptiBench across Gurobi, OR-Tools, and COPT show that EVOM matches or outperforms process-supervised SFT, supports zero-shot solver transfer, and achieves effective low-cost solver adaptation by continuing training under the target solver backend.
LLM4Fluid: Large Language Models as Generalizable Neural Solvers for Fluid Dynamics
Jan 29, 2026Deep learning has emerged as a promising paradigm for spatio-temporal modeling of fluid dynamics. However, existing approaches often suffer from limited generalization to unseen flow conditions and typically require retraining when applied to new scenarios. In this paper, we present LLM4Fluid, a spatio-temporal prediction framework that leverages Large Language Models (LLMs) as generalizable neural solvers for fluid dynamics. The framework first compresses high-dimensional flow fields into a compact latent space via reduced-order modeling enhanced with a physics-informed disentanglement mechanism, effectively mitigating spatial feature entanglement while preserving essential flow structures. A pretrained LLM then serves as a temporal processor, autoregressively predicting the dynamics of physical sequences with time series prompts. To bridge the modality gap between prompts and physical sequences, which can otherwise degrade prediction accuracy, we propose a dedicated modality alignment strategy that resolves representational mismatch and stabilizes long-term prediction. Extensive experiments across diverse flow scenarios demonstrate that LLM4Fluid functions as a robust and generalizable neural solver without retraining, achieving state-of-the-art accuracy while exhibiting powerful zero-shot and in-context learning capabilities. Code and datasets are publicly available at https://github.com/qisongxiao/LLM4Fluid.
CLIP-AE: CLIP-assisted Cross-view Audio-Visual Enhancement for Unsupervised Temporal Action Localization
May 29, 2025Temporal Action Localization (TAL) has garnered significant attention in information retrieval. Existing supervised or weakly supervised methods heavily rely on labeled temporal boundaries and action categories, which are labor-intensive and time-consuming. Consequently, unsupervised temporal action localization (UTAL) has gained popularity. However, current methods face two main challenges: 1) Classification pre-trained features overly focus on highly discriminative regions; 2) Solely relying on visual modality information makes it difficult to determine contextual boundaries. To address these issues, we propose a CLIP-assisted cross-view audiovisual enhanced UTAL method. Specifically, we introduce visual language pre-training (VLP) and classification pre-training-based collaborative enhancement to avoid excessive focus on highly discriminative regions; we also incorporate audio perception to provide richer contextual boundary information. Finally, we introduce a self-supervised cross-view learning paradigm to achieve multi-view perceptual enhancement without additional annotations. Extensive experiments on two public datasets demonstrate our model's superiority over several state-of-the-art competitors.
Reason-Align-Respond: Aligning LLM Reasoning with Knowledge Graphs for KGQA
May 27, 2025LLMs have demonstrated remarkable capabilities in complex reasoning tasks, yet they often suffer from hallucinations and lack reliable factual grounding. Meanwhile, knowledge graphs (KGs) provide structured factual knowledge but lack the flexible reasoning abilities of LLMs. In this paper, we present Reason-Align-Respond (RAR), a novel framework that systematically integrates LLM reasoning with knowledge graphs for KGQA. Our approach consists of three key components: a Reasoner that generates human-like reasoning chains, an Aligner that maps these chains to valid KG paths, and a Responser that synthesizes the final answer. We formulate this process as a probabilistic model and optimize it using the Expectation-Maximization algorithm, which iteratively refines the reasoning chains and knowledge paths. Extensive experiments on multiple benchmarks demonstrate the effectiveness of RAR, achieving state-of-the-art performance with Hit@1 scores of 93.3% and 91.0% on WebQSP and CWQ respectively. Human evaluation confirms that RAR generates high-quality, interpretable reasoning chains well-aligned with KG paths. Furthermore, RAR exhibits strong zero-shot generalization capabilities and maintains computational efficiency during inference.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025
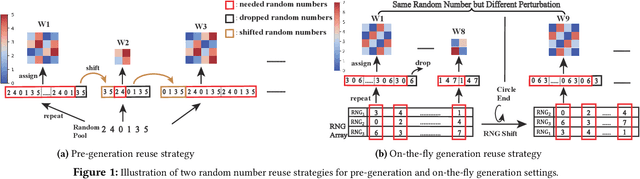


Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.
DPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving
Apr 23, 2025



Modern robots must coexist with humans in dense urban environments. A key challenge is the ghost probe problem, where pedestrians or objects unexpectedly rush into traffic paths. This issue affects both autonomous vehicles and human drivers. Existing works propose vehicle-to-everything (V2X) strategies and non-line-of-sight (NLOS) imaging for ghost probe zone detection. However, most require high computational power or specialized hardware, limiting real-world feasibility. Additionally, many methods do not explicitly address this issue. To tackle this, we propose DPGP, a hybrid 2D-3D fusion framework for ghost probe zone prediction using only a monocular camera during training and inference. With unsupervised depth prediction, we observe ghost probe zones align with depth discontinuities, but different depth representations offer varying robustness. To exploit this, we fuse multiple feature embeddings to improve prediction. To validate our approach, we created a 12K-image dataset annotated with ghost probe zones, carefully sourced and cross-checked for accuracy. Experimental results show our framework outperforms existing methods while remaining cost-effective. To our knowledge, this is the first work extending ghost probe zone prediction beyond vehicles, addressing diverse non-vehicle objects. We will open-source our code and dataset for community benefit.
MEMIT-Merge: Addressing MEMIT's Key-Value Conflicts in Same-Subject Batch Editing for LLMs
Feb 11, 2025



As large language models continue to scale up, knowledge editing techniques that modify models' internal knowledge without full retraining have gained significant attention. MEMIT, a prominent batch editing algorithm, stands out for its capability to perform mass knowledge modifications. However, we uncover a critical limitation that MEMIT's editing efficacy significantly deteriorates when processing batches containing multiple edits sharing the same subject. Our analysis reveals that the root cause lies in MEMIT's key value modeling framework: When multiple facts with the same subject in a batch are modeled through MEMIT's key value mechanism, identical keys (derived from the shared subject) are forced to represent different values (corresponding to different knowledge), resulting in updates conflicts during editing. Addressing this issue, we propose MEMIT-Merge, an enhanced approach that merges value computation processes for facts sharing the same subject, effectively resolving the performance degradation in same-subject batch editing scenarios. Experimental results demonstrate that when MEMIT's edit success rate drops to around 50% at larger batch sizes, MEMIT-Merge maintains a success rate exceeding 90%, showcasing remarkable robustness to subject entity collisions.
Towards Explainable Multimodal Depression Recognition for Clinical Interviews
Jan 27, 2025



Recently, multimodal depression recognition for clinical interviews (MDRC) has recently attracted considerable attention. Existing MDRC studies mainly focus on improving task performance and have achieved significant development. However, for clinical applications, model transparency is critical, and previous works ignore the interpretability of decision-making processes. To address this issue, we propose an Explainable Multimodal Depression Recognition for Clinical Interviews (EMDRC) task, which aims to provide evidence for depression recognition by summarizing symptoms and uncovering underlying causes. Given an interviewer-participant interaction scenario, the goal of EMDRC is to structured summarize participant's symptoms based on the eight-item Patient Health Questionnaire depression scale (PHQ-8), and predict their depression severity. To tackle the EMDRC task, we construct a new dataset based on an existing MDRC dataset. Moreover, we utilize the PHQ-8 and propose a PHQ-aware multimodal multi-task learning framework, which captures the utterance-level symptom-related semantic information to help generate dialogue-level summary. Experiment results on our annotated dataset demonstrate the superiority of our proposed methods over baseline systems on the EMDRC task.