 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Direct Preference Optimization for Distributionally Robust Generative Recommendation
Mar 21, 2026Direct Preference Optimization (DPO) guides large language models (LLMs) to generate recommendations aligned with user historical behavior distributions by minimizing preference alignment loss. However, our systematic empirical research and theoretical analysis reveal that DPO tends to amplify spurious correlations caused by environmental confounders during the alignment process, significantly undermining the generalization capability of LLM-based generative recommendation methods in out of distribution (OOD) scenarios. To mitigate this issue, we propose CausalDPO, an extension of DPO that incorporates a causal invariance learning mechanism. This method introduces a backdoor adjustment strategy during the preference alignment phase to eliminate interference from environmental confounders, explicitly models the latent environmental distribution using a soft clustering approach, and enhances robust consistency across diverse environments through invariance constraints. Theoretical analysis demonstrates that CausalDPO can effectively capture users stable preference structures across multiple environments, thereby improving the OOD generalization performance of LLM-based recommendation models. We conduct extensive experiments under four representative distribution shift settings to validate the effectiveness of CausalDPO, achieving an average performance improvement of 17.17% across four evaluation metrics.
Mitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
ECHO: Entropy-Confidence Hybrid Optimization for Test-Time Reinforcement Learning
Feb 02, 2026Test-time reinforcement learning generates multiple candidate answers via repeated rollouts and performs online updates using pseudo-labels constructed by majority voting. To reduce overhead and improve exploration, prior work introduces tree structured rollouts, which share reasoning prefixes and branch at key nodes to improve sampling efficiency. However, this paradigm still faces two challenges: (1) high entropy branching can trigger rollout collapse, where the branching budget concentrates on a few trajectories with consecutive high-entropy segments, rapidly reducing the number of effective branches; (2) early pseudo-labels are noisy and biased, which can induce self-reinforcing overfitting, causing the policy to sharpen prematurely and suppress exploration. To address these issues, we propose Entropy Confidence Hybrid Group Relative Policy Optimization (ECHO). During rollout, ECHO jointly leverages local entropy and group level confidence to adaptively control branch width, and further introduces online confidence-based pruning to terminate persistently low confidence branches, avoiding high entropy traps and mitigating collapse. During policy updates, ECHO employs confidence adaptive clipping and an entropy confidence hybrid advantage shaping approach to enhance training robustness and mitigate early stage bias. Experiments demonstrate that ECHO achieves consistent gains on multiple mathematical and visual reasoning benchmarks, and generalizes more effectively under a limited rollout budget.
MMGRid: Navigating Temporal-aware and Cross-domain Generative Recommendation via Model Merging
Jan 22, 2026Model merging (MM) offers an efficient mechanism for integrating multiple specialized models without access to original training data or costly retraining. While MM has demonstrated success in domains like computer vision, its role in recommender systems (RSs) remains largely unexplored. Recently, Generative Recommendation (GR) has emerged as a new paradigm in RSs, characterized by rapidly growing model scales and substantial computational costs, making MM particularly appealing for cost-sensitive deployment scenarios. In this work, we present the first systematic study of MM in GR through a contextual lens. We focus on a fundamental yet underexplored challenge in real-world: how to merge generative recommenders specialized to different real-world contexts, arising from temporal evolving user behaviors and heterogeneous application domains. To this end, we propose a unified framework MMGRid, a structured contextual grid of GR checkpoints that organizes models trained under diverse contexts induced by temporal evolution and domain diversity. All checkpoints are derived from a shared base LLM but fine-tuned on context-specific data, forming a realistic and controlled model space for systematically analyzing MM across GR paradigms and merging algorithms. Our investigation reveals several key insights. First, training GR models from LLMs can introduce parameter conflicts during merging due to token distribution shifts and objective disparities; such conflicts can be alleviated by disentangling task-aware and context-specific parameter changes via base model replacement. Second, incremental training across contexts induces recency bias, which can be effectively balanced through weighted contextual merging. Notably, we observe that optimal merging weights correlate with context-dependent interaction characteristics, offering practical guidance for weight selection in real-world deployments.
Breaking Expert Knowledge Limits: Self-Pruning for Large Language Models
Nov 19, 2025



Large language models (LLMs) have achieved remarkable performance on a wide range of tasks, hindering real-world deployment due to their massive size. Existing pruning methods (e.g., Wanda) tailored for LLMs rely heavily on manual design pruning algorithms, thereby leading to \textit{huge labor costs} and \textit{requires expert knowledge}. Furthermore, we are the first to identify the serious \textit{outlier value issue} behind dramatic performance degradation under high pruning ratios that are caused by uniform sparsity, raising an additional concern about how to design adaptive pruning sparsity ideal for LLMs. Can LLMs prune by themselves? In this work, we introduce an affirmative answer by proposing a novel pruning method called \textbf{AutoPrune}, which first overcomes expert knowledge limits by leveraging LLMs to design optimal pruning algorithms for themselves automatically without any expert knowledge. Specifically, to mitigate the black-box nature of LLMs, we propose a Graph-driven Chain-of-Thought (GCoT) to optimize prompts, significantly enhancing the reasoning process in learning the pruning algorithm and enabling us to generate pruning algorithms with superior performance and interpretability in the next generation. Finally, grounded in insights of outlier value issue, we introduce Skew-aware Dynamic Sparsity Allocation (SDSA) to overcome the outlier value issue, mitigating performance degradation under high pruning ratios. We conduct extensive experiments on mainstream LLMs benchmarks, demonstrating the superiority of AutoPrune, which consistently excels state-of-the-art competitors. The code is available at: https://anonymous.4open.science/r/AutoPrune.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025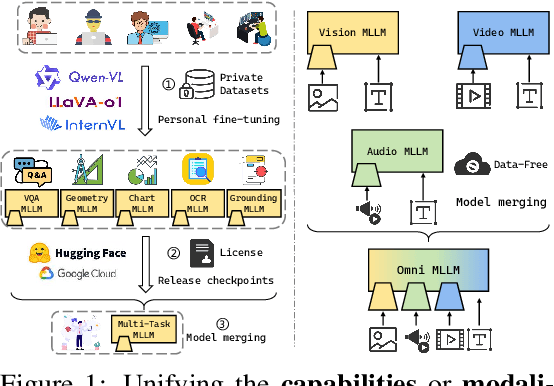

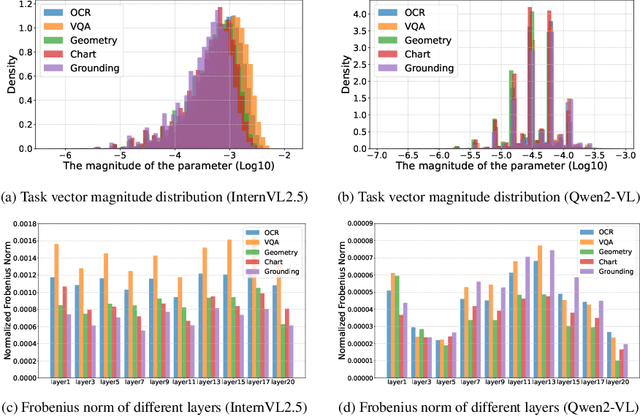
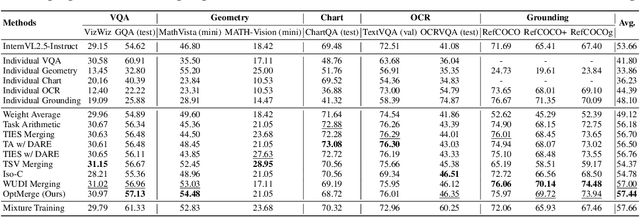
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
Apr 07, 2025Data augmentation has become a promising method of mitigating data sparsity in sequential recommendation. Existing methods generate new yet effective data during model training to improve performance. However, deploying them requires retraining, architecture modification, or introducing additional learnable parameters. The above steps are time-consuming and costly for well-trained models, especially when the model scale becomes large. In this work, we explore the test-time augmentation (TTA) for sequential recommendation, which augments the inputs during the model inference and then aggregates the model's predictions for augmented data to improve final accuracy. It avoids significant time and cost overhead from loss calculation and backward propagation. We first experimentally disclose the potential of existing augmentation operators for TTA and find that the Mask and Substitute consistently achieve better performance. Further analysis reveals that these two operators are effective because they retain the original sequential pattern while adding appropriate perturbations. Meanwhile, we argue that these two operators still face time-consuming item selection or interference information from mask tokens. Based on the analysis and limitations, we present TNoise and TMask. The former injects uniform noise into the original representation, avoiding the computational overhead of item selection. The latter blocks mask token from participating in model calculations or directly removes interactions that should have been replaced with mask tokens. Comprehensive experiments demonstrate the effectiveness, efficiency, and generalizability of our method. We provide an anonymous implementation at https://github.com/KingGugu/TTA4SR.
Can LLM-Driven Hard Negative Sampling Empower Collaborative Filtering? Findings and Potentials
Apr 07, 2025Hard negative samples can accelerate model convergence and optimize decision boundaries, which is key to improving the performance of recommender systems. Although large language models (LLMs) possess strong semantic understanding and generation capabilities, systematic research has not yet been conducted on how to generate hard negative samples effectively. To fill this gap, this paper introduces the concept of Semantic Negative Sampling and exploreshow to optimize LLMs for high-quality, hard negative sampling. Specifically, we design an experimental pipeline that includes three main modules, profile generation, semantic negative sampling, and semantic alignment, to verify the potential of LLM-driven hard negative sampling in enhancing the accuracy of collaborative filtering (CF). Experimental results indicate that hard negative samples generated based on LLMs, when semantically aligned and integrated into CF, can significantly improve CF performance, although there is still a certain gap compared to traditional negative sampling methods. Further analysis reveals that this gap primarily arises from two major challenges: noisy samples and lack of behavioral constraints. To address these challenges, we propose a framework called HNLMRec, based on fine-tuning LLMs supervised by collaborative signals. Experimental results show that this framework outperforms traditional negative sampling and other LLM-driven recommendation methods across multiple datasets, providing new solutions for empowering traditional RS with LLMs. Additionally, we validate the excellent generalization ability of the LLM-based semantic negative sampling method on new datasets, demonstrating its potential in alleviating issues such as data sparsity, popularity bias, and the problem of false hard negative samples. Our implementation code is available at https://github.com/user683/HNLMRec.
Distributionally Robust Graph Out-of-Distribution Recommendation via Diffusion Model
Jan 26, 2025The distributionally robust optimization (DRO)-based graph neural network methods improve recommendation systems' out-of-distribution (OOD) generalization by optimizing the model's worst-case performance. However, these studies fail to consider the impact of noisy samples in the training data, which results in diminished generalization capabilities and lower accuracy. Through experimental and theoretical analysis, this paper reveals that current DRO-based graph recommendation methods assign greater weight to noise distribution, leading to model parameter learning being dominated by it. When the model overly focuses on fitting noise samples in the training data, it may learn irrelevant or meaningless features that cannot be generalized to OOD data. To address this challenge, we design a Distributionally Robust Graph model for OOD recommendation (DRGO). Specifically, our method first employs a simple and effective diffusion paradigm to alleviate the noisy effect in the latent space. Additionally, an entropy regularization term is introduced in the DRO objective function to avoid extreme sample weights in the worst-case distribution. Finally, we provide a theoretical proof of the generalization error bound of DRGO as well as a theoretical analysis of how our approach mitigates noisy sample effects, which helps to better understand the proposed framework from a theoretical perspective. We conduct extensive experiments on four datasets to evaluate the effectiveness of our framework against three typical distribution shifts, and the results demonstrate its superiority in both independently and identically distributed distributions (IID) and OOD.
Merging Models on the Fly Without Retraining: A Sequential Approach to Scalable Continual Model Merging
Jan 16, 2025



Deep model merging represents an emerging research direction that combines multiple fine-tuned models to harness their specialized capabilities across different tasks and domains. Current model merging techniques focus on merging all available models simultaneously, with weight interpolation-based methods being the predominant approaches. However, these conventional approaches are not well-suited for scenarios where models become available sequentially, and they often suffer from high memory requirements and potential interference between tasks. In this study, we propose a training-free projection-based continual merging method that processes models sequentially through orthogonal projections of weight matrices and adaptive scaling mechanisms. Our method operates by projecting new parameter updates onto subspaces orthogonal to existing merged parameter updates while using an adaptive scaling mechanism to maintain stable parameter distances, enabling efficient sequential integration of task-specific knowledge. Our approach maintains constant memory complexity to the number of models, minimizes interference between tasks through orthogonal projections, and retains the performance of previously merged models through adaptive task vector scaling. Extensive experiments on CLIP-ViT models demonstrate that our method achieves a 5-8% average accuracy improvement while maintaining robust performance in different task orderings.