 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Bridges, One Pathway: From VLMs to Generalizable VLAs with Embodied Trajectory-Coupled Data
Jun 07, 2026Vision-language models (VLMs) are powerful general-purpose reasoners, yet converting them into robot control policies (VLAs) is surprisingly difficult. The root cause is a two-fold gap: VLMs are trained on internet-scale images with language-understanding objectives, while VLAs must perceive robot scenes and predict motor actions. Fine-tuning a VLM directly on robot action data forces the model to cross both gaps at once -- the learning curve is steep and the rich generalizations learned during pretraining tend to degrade rather than transfer. We argue that this gap can be bridged gradually with the right intermediate data. We introduce \emph{embodied trajectory-coupled (ETC) data} -- vision-language supervision derived from the same robot scenes and trajectories used for action learning. Because ETC data shares the visual context of robot operation while retaining familiar language-understanding objectives, it provides a natural stepping stone between VLM pretraining and VLA fine-tuning. Building on this, we design a three-stage training recipe. Distribution Bridging first adapts the VLM to embodied visual-language semantics. Objective Bridging then gradually shifts the model toward action prediction while preserving the acquired representations. Retentive Adaptation finally specializes the policy to the target deployment domain. We further show that mixing task-relevant out-of-distribution ETC data with a small amount of action data enables the model to generalize to novel visual-language conditions without requiring additional robot demonstrations. Simulation and real-robot experiments confirm that this gradual bridging strategy is the key to transferring VLM generalization into robust, deployable robot policies.
Towards On-Policy Data Evolution for Visual-Native Multimodal Deep Search Agents
May 11, 2026Multimodal deep search requires an agent to solve open-world problems by chaining search, tool use, and visual reasoning over evolving textual and visual context. Two bottlenecks limit current systems. First, existing tool-use harnesses treat images returned by search, browsing, or transformation as transient outputs, so intermediate visual evidence cannot be re-consumed by later tools. Second, training data is usually built by fixed curation recipes that cannot track the target agent's evolving capability. To address these challenges, we first introduce a visual-native agent harness centered on an image bank reference protocol, which registers every tool-returned image as an addressable reference and makes intermediate visual evidence reusable by later tools. On top of this harness, On-policy Data Evolution (ODE) runs a closed-loop data generator that refines itself across rounds from rollouts of the policy being trained. This per-round refinement makes each round's data target what the current policy still needs to learn. The same framework supports both diverse supervised fine-tuning data and policy-aware reinforcement learning data curation, covering the full training lifecycle of the target agent. Across 8 multimodal deep search benchmarks, ODE improves the Qwen3-VL-8B agent from 24.9% to 39.0% on average, surpassing Gemini-2.5 Pro in standard agent-workflow setting (37.9%). At 30B, ODE raises the average score from 30.6% to 41.5%. Further analyses validate the effectiveness of image-bank reuse, especially on complex tasks requiring iterative visual refinement, while rollout-feedback evolution yields more grounded SFT traces and better policy-matched RL tasks than static synthesis.
Do Phone-Use Agents Respect Your Privacy?
Apr 02, 2026We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as permissioned access, minimal disclosure, and user-controlled memory through a minimal privacy contract, iMy, and pair it with instrumented mock apps plus rule-based auditing that make unnecessary permission requests, deceptive re-disclosure, and unnecessary form filling observable and reproducible. Across five frontier models on 10 mobile apps and 300 tasks, we find that task success, privacy-compliant task completion, and later-session use of saved preferences are distinct capabilities, and no single model dominates all three. Evaluating success and privacy jointly reshuffles the model ordering relative to either metric alone. The most persistent failure mode across models is simple data minimization: agents still fill optional personal entries that the task does not require. These results show that privacy failures arise from over-helpful execution of benign tasks, and that success-only evaluation overestimates the deployment readiness of current phone-use agents. All code, mock apps, and agent trajectories are publicly available at~ https://github.com/FreedomIntelligence/MyPhoneBench.
Harnessing Lightweight Transformer with Contextual Synergic Enhancement for Efficient 3D Medical Image Segmentation
Mar 24, 2026Transformers have shown remarkable performance in 3D medical image segmentation, but their high computational requirements and need for large amounts of labeled data limit their applicability. To address these challenges, we consider two crucial aspects: model efficiency and data efficiency. Specifically, we propose Light-UNETR, a lightweight transformer designed to achieve model efficiency. Light-UNETR features a Lightweight Dimension Reductive Attention (LIDR) module, which reduces spatial and channel dimensions while capturing both global and local features via multi-branch attention. Additionally, we introduce a Compact Gated Linear Unit (CGLU) to selectively control channel interaction with minimal parameters. Furthermore, we introduce a Contextual Synergic Enhancement (CSE) learning strategy, which aims to boost the data efficiency of Transformers. It first leverages the extrinsic contextual information to support the learning of unlabeled data with Attention-Guided Replacement, then applies Spatial Masking Consistency that utilizes intrinsic contextual information to enhance the spatial context reasoning for unlabeled data. Extensive experiments on various benchmarks demonstrate the superiority of our approach in both performance and efficiency. For example, with only 10% labeled data on the Left Atrial Segmentation dataset, our method surpasses BCP by 1.43% Jaccard while drastically reducing the FLOPs by 90.8% and parameters by 85.8%. Code is released at https://github.com/CUHK-AIM-Group/Light-UNETR.
Thinking in Dynamics: How Multimodal Large Language Models Perceive, Track, and Reason Dynamics in Physical 4D World
Mar 13, 2026Humans inhabit a physical 4D world where geometric structure and semantic content evolve over time, constituting a dynamic 4D reality (spatial with temporal dimension). While current Multimodal Large Language Models (MLLMs) excel in static visual understanding, can they also be adept at "thinking in dynamics", i.e., perceive, track and reason about spatio-temporal dynamics in evolving scenes? To systematically assess their spatio-temporal reasoning and localized dynamics perception capabilities, we introduce Dyn-Bench, a large-scale benchmark built from diverse real-world and synthetic video datasets, enabling robust and scalable evaluation of spatio-temporal understanding. Through multi-stage filtering from massive 2D and 4D data sources, Dyn-Bench provides a high-quality collection of dynamic scenes, comprising 1k videos, 7k visual question answering (VQA) pairs, and 3k dynamic object grounding pairs. We probe general, spatial and region-level MLLMs to express how they think in dynamics both linguistically and visually, and find that existing models cannot simultaneously maintain strong performance in both spatio-temporal reasoning and dynamic object grounding, often producing inconsistent interpretations of motion and interaction. Notably, conventional prompting strategies (e.g., chain-of-thought or caption-based hints) provide limited improvement, whereas structured integration approaches, including Mask-Guided Fusion and Spatio-Temporal Textual Cognitive Map (ST-TCM), significantly enhance MLLMs' dynamics perception and spatio-temporal reasoning in the physical 4D world. Code and benchmark are available at https://dyn-bench.github.io/.
MedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning
Feb 03, 2026Medical image segmentation is evolving from task-specific models toward generalizable frameworks. Recent research leverages Multi-modal Large Language Models (MLLMs) as autonomous agents, employing reinforcement learning with verifiable reward (RLVR) to orchestrate specialized tools like the Segment Anything Model (SAM). However, these approaches often rely on single-turn, rigid interaction strategies and lack process-level supervision during training, which hinders their ability to fully exploit the dynamic potential of interactive tools and leads to redundant actions. To bridge this gap, we propose MedSAM-Agent, a framework that reformulates interactive segmentation as a multi-step autonomous decision-making process. First, we introduce a hybrid prompting strategy for expert-curated trajectory generation, enabling the model to internalize human-like decision heuristics and adaptive refinement strategies. Furthermore, we develop a two-stage training pipeline that integrates multi-turn, end-to-end outcome verification with a clinical-fidelity process reward design to promote interaction parsimony and decision efficiency. Extensive experiments across 6 medical modalities and 21 datasets demonstrate that MedSAM-Agent achieves state-of-the-art performance, effectively unifying autonomous medical reasoning with robust, iterative optimization. Code is available \href{https://github.com/CUHK-AIM-Group/MedSAM-Agent}{here}.
WonderFree: Enhancing Novel View Quality and Cross-View Consistency for 3D Scene Exploration
Jun 25, 2025Interactive 3D scene generation from a single image has gained significant attention due to its potential to create immersive virtual worlds. However, a key challenge in current 3D generation methods is the limited explorability, which cannot render high-quality images during larger maneuvers beyond the original viewpoint, particularly when attempting to move forward into unseen areas. To address this challenge, we propose WonderFree, the first model that enables users to interactively generate 3D worlds with the freedom to explore from arbitrary angles and directions. Specifically, we decouple this challenge into two key subproblems: novel view quality, which addresses visual artifacts and floating issues in novel views, and cross-view consistency, which ensures spatial consistency across different viewpoints. To enhance rendering quality in novel views, we introduce WorldRestorer, a data-driven video restoration model designed to eliminate floaters and artifacts. In addition, a data collection pipeline is presented to automatically gather training data for WorldRestorer, ensuring it can handle scenes with varying styles needed for 3D scene generation. Furthermore, to improve cross-view consistency, we propose ConsistView, a multi-view joint restoration mechanism that simultaneously restores multiple perspectives while maintaining spatiotemporal coherence. Experimental results demonstrate that WonderFree not only enhances rendering quality across diverse viewpoints but also significantly improves global coherence and consistency. These improvements are confirmed by CLIP-based metrics and a user study showing a 77.20% preference for WonderFree over WonderWorld enabling a seamless and immersive 3D exploration experience. The code, model, and data will be publicly available.
Towards a general-purpose foundation model for fMRI analysis
Jun 11, 2025



Functional Magnetic Resonance Imaging (fMRI) is essential for studying brain function and diagnosing neurological disorders, but current analysis methods face reproducibility and transferability issues due to complex pre-processing and task-specific models. We introduce NeuroSTORM (Neuroimaging Foundation Model with Spatial-Temporal Optimized Representation Modeling), a generalizable framework that directly learns from 4D fMRI volumes and enables efficient knowledge transfer across diverse applications. NeuroSTORM is pre-trained on 28.65 million fMRI frames (>9,000 hours) from over 50,000 subjects across multiple centers and ages 5 to 100. Using a Mamba backbone and a shifted scanning strategy, it efficiently processes full 4D volumes. We also propose a spatial-temporal optimized pre-training approach and task-specific prompt tuning to improve transferability. NeuroSTORM outperforms existing methods across five tasks: age/gender prediction, phenotype prediction, disease diagnosis, fMRI-to-image retrieval, and task-based fMRI classification. It demonstrates strong clinical utility on datasets from hospitals in the U.S., South Korea, and Australia, achieving top performance in disease diagnosis and cognitive phenotype prediction. NeuroSTORM provides a standardized, open-source foundation model to improve reproducibility and transferability in fMRI-based clinical research.
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025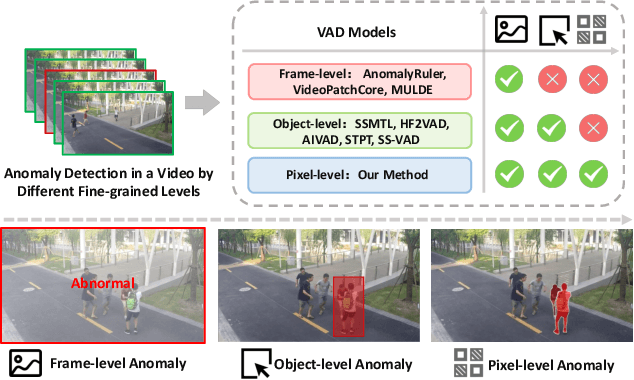
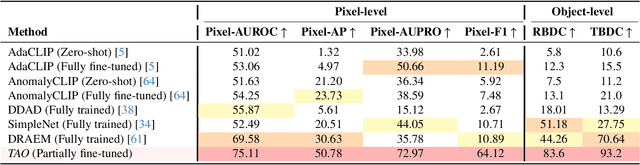
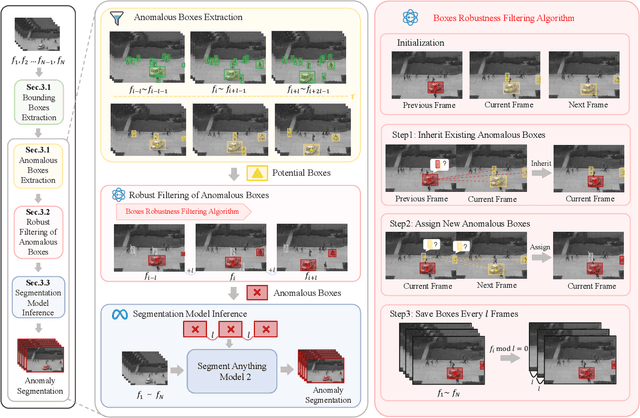
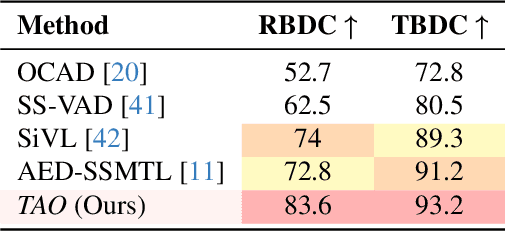
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
FlexGS: Train Once, Deploy Everywhere with Many-in-One Flexible 3D Gaussian Splatting
Jun 04, 20253D Gaussian splatting (3DGS) has enabled various applications in 3D scene representation and novel view synthesis due to its efficient rendering capabilities. However, 3DGS demands relatively significant GPU memory, limiting its use on devices with restricted computational resources. Previous approaches have focused on pruning less important Gaussians, effectively compressing 3DGS but often requiring a fine-tuning stage and lacking adaptability for the specific memory needs of different devices. In this work, we present an elastic inference method for 3DGS. Given an input for the desired model size, our method selects and transforms a subset of Gaussians, achieving substantial rendering performance without additional fine-tuning. We introduce a tiny learnable module that controls Gaussian selection based on the input percentage, along with a transformation module that adjusts the selected Gaussians to complement the performance of the reduced model. Comprehensive experiments on ZipNeRF, MipNeRF and Tanks\&Temples scenes demonstrate the effectiveness of our approach. Code is available at https://flexgs.github.io.