 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking in Dynamics: How Multimodal Large Language Models Perceive, Track, and Reason Dynamics in Physical 4D World
Mar 13, 2026Humans inhabit a physical 4D world where geometric structure and semantic content evolve over time, constituting a dynamic 4D reality (spatial with temporal dimension). While current Multimodal Large Language Models (MLLMs) excel in static visual understanding, can they also be adept at "thinking in dynamics", i.e., perceive, track and reason about spatio-temporal dynamics in evolving scenes? To systematically assess their spatio-temporal reasoning and localized dynamics perception capabilities, we introduce Dyn-Bench, a large-scale benchmark built from diverse real-world and synthetic video datasets, enabling robust and scalable evaluation of spatio-temporal understanding. Through multi-stage filtering from massive 2D and 4D data sources, Dyn-Bench provides a high-quality collection of dynamic scenes, comprising 1k videos, 7k visual question answering (VQA) pairs, and 3k dynamic object grounding pairs. We probe general, spatial and region-level MLLMs to express how they think in dynamics both linguistically and visually, and find that existing models cannot simultaneously maintain strong performance in both spatio-temporal reasoning and dynamic object grounding, often producing inconsistent interpretations of motion and interaction. Notably, conventional prompting strategies (e.g., chain-of-thought or caption-based hints) provide limited improvement, whereas structured integration approaches, including Mask-Guided Fusion and Spatio-Temporal Textual Cognitive Map (ST-TCM), significantly enhance MLLMs' dynamics perception and spatio-temporal reasoning in the physical 4D world. Code and benchmark are available at https://dyn-bench.github.io/.
RoboStream: Weaving Spatio-Temporal Reasoning with Memory in Vision-Language Models for Robotics
Mar 13, 2026Enabling reliable long-horizon robotic manipulation is a crucial step toward open-world embodied intelligence. However, VLM-based planners treat each step as an isolated observation-to-action mapping, forcing them to reinfer scene geometry from raw pixels at every decision point while remaining unaware of how prior actions have reshaped the environment. Despite strong short-horizon performance, these systems lack the spatio-temporal reasoning required for persistent geometric anchoring and memory of action-triggered state transitions. Without persistent state tracking, perceptual errors accumulate across the execution horizon, temporarily occluded objects are catastrophically forgotten, and these compounding failures lead to precondition violations that cascade through subsequent steps. In contrast, humans maintain a persistent mental model that continuously tracks spatial relations and action consequences across interactions rather than reconstructing them at each instant. Inspired by this human capacity for causal spatio-temporal reasoning with persistent memory, we propose RoboStream, a training-free framework that achieves geometric anchoring through Spatio-Temporal Fusion Tokens (STF-Tokens), which bind visual evidence to 3D geometric attributes for persistent object grounding, and maintains causal continuity via a Causal Spatio-Temporal Graph (CSTG) that records action-triggered state transitions across steps. This design enables the planner to trace causal chains and preserve object permanence under occlusion without additional training or fine-tuning. RoboStream achieves 90.5% on long-horizon RLBench and 44.4% on challenging real-world block-building tasks, where both SoFar and VoxPoser score 11.1%, demonstrating that spatio-temporal reasoning and causal memory are critical missing components for reliable long-horizon manipulation.
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025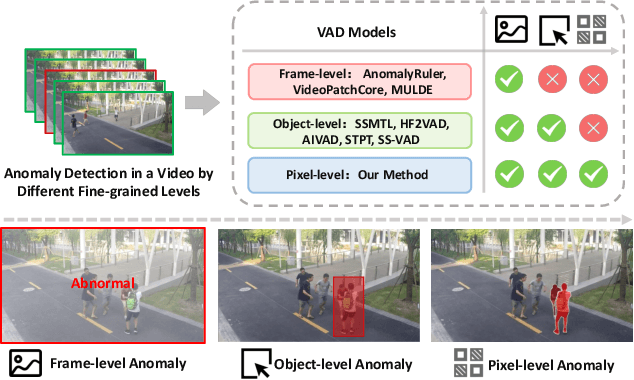
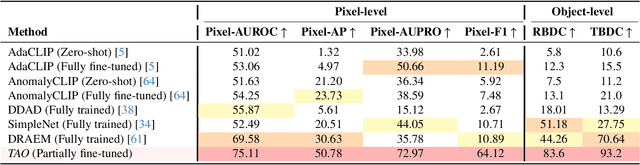
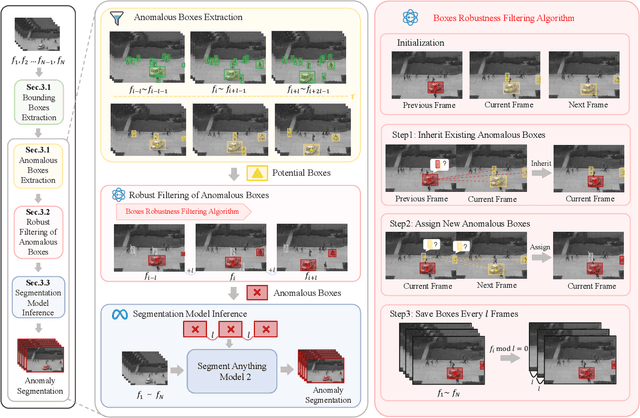
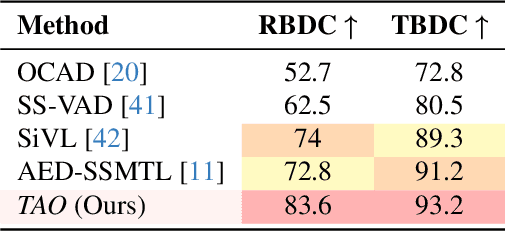
Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
Underwater Object Detection in the Era of Artificial Intelligence: Current, Challenge, and Future
Oct 08, 2024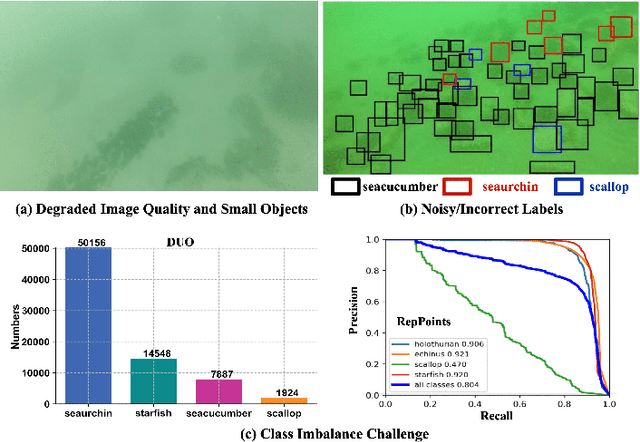

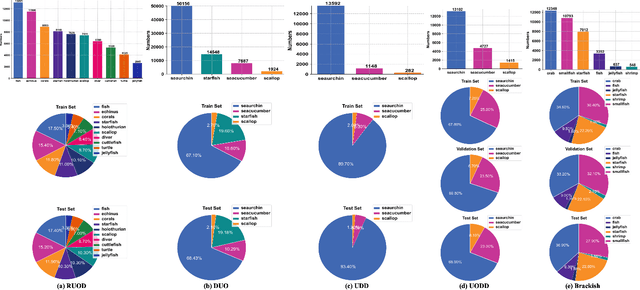
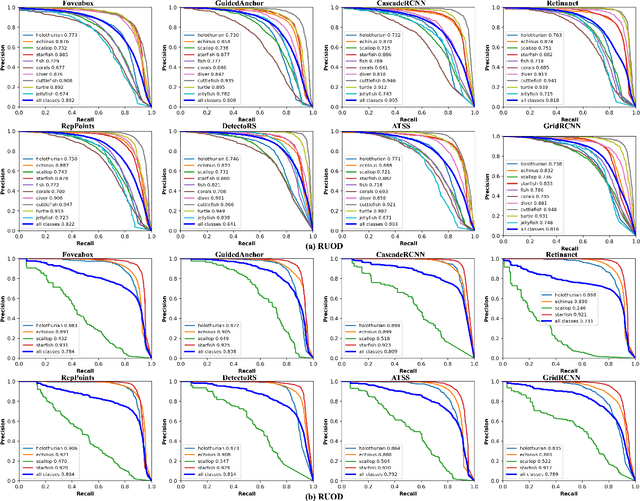
Underwater object detection (UOD), aiming to identify and localise the objects in underwater images or videos, presents significant challenges due to the optical distortion, water turbidity, and changing illumination in underwater scenes. In recent years, artificial intelligence (AI) based methods, especially deep learning methods, have shown promising performance in UOD. To further facilitate future advancements, we comprehensively study AI-based UOD. In this survey, we first categorise existing algorithms into traditional machine learning-based methods and deep learning-based methods, and summarise them by considering learning strategy, experimental dataset, utilised features or frameworks, and learning stage. Next, we discuss the potential challenges and suggest possible solutions and new directions. We also perform both quantitative and qualitative evaluations of mainstream algorithms across multiple benchmark datasets by considering the diverse and biased experimental setups. Finally, we introduce two off-the-shelf detection analysis tools, Diagnosis and TIDE, which well-examine the effects of object characteristics and various types of errors on detectors. These tools help identify the strengths and weaknesses of detectors, providing insigts for further improvement. The source codes, trained models, utilised datasets, detection results, and detection analysis tools are public available at \url{https://github.com/LongChenCV/UODReview}, and will be regularly updated.