 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegDINO: Introducing Multi-Scale Structure into DINO for Efficient Medical Image Segmentation
Jun 16, 2026Self-supervised DINO models provide strong transferable visual representations, yet applying them directly to image segmentation remains challenging. Existing approaches commonly rely on heavy decoders with complex upsampling, introducing substantial parameter and computational overhead. We observe that introducing scale into DINO features is far more critical than increasing decoder capacity. In this work, we present SegDINO, an efficient segmentation framework that integrates a DINOv3 backbone with lightweight scale modeling. SegDINO introduces Token Pyramid Adaptation (TPA) to reorganize intermediate DINO features into a pseudo multi-scale hierarchy, and Scale-Aware Decoding (SAD) for efficient intra-scale refinement and top-down multi-scale propagation. We further curate PanCT, a new CT dataset containing 284 patients with expert-annotated pancreatic tumors, to assess SegDINO's ability to handle difficult small-lesion cases. Extensive experiments on PanCT and three public benchmarks demonstrate that SegDINO achieves state-of-the-art results with high efficiency. The code is available at https://github.com/script-Yang/segdino_v2.
GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
May 20, 2026Open-ended image generation is no longer a simple prompt-to-image problem. High-quality generation often requires an agent to combine a model's internal generative ability with external resources. As requests become more diverse and demanding, we aim to develop a general image-generation agent that can self-evolve through trajectories and use tools more effectively across varied generation challenges. To this end, we propose GenEvolve, a self-evolving framework based on Tool-Orchestrated Visual Experience Distillation. In GenEvolve, each generation attempt is modeled as a tool-orchestrated trajectory, where the agent gathers evidence, selects references, invokes generation skills, and composes them into a prompt-reference program. Unlike existing agentic generation methods that mainly rely on image-level scalar rewards, GenEvolve compares multiple trajectories for the same request and abstracts best-worst differences into structured visual experience, provided only to a privileged teacher branch. Inspired by on-policy self-distillation, Visual Experience Distillation provides dense token-level supervision, helping the student internalize better search, knowledge activation, reference selection, and prompt construction. We further construct GenEvolve-Data and GenEvolve-Bench. Experiments on public benchmarks and GenEvolve-Bench show substantial gains over strong baselines, achieving state-of-the-art performance among current image-generation frameworks. Our website is as follows: https://ephemeral182.github.io/GenEvolve/
PosterOmni: Generalized Artistic Poster Creation via Task Distillation and Unified Reward Feedback
Feb 12, 2026Image-to-poster generation is a high-demand task requiring not only local adjustments but also high-level design understanding. Models must generate text, layout, style, and visual elements while preserving semantic fidelity and aesthetic coherence. The process spans two regimes: local editing, where ID-driven generation, rescaling, filling, and extending must preserve concrete visual entities; and global creation, where layout- and style-driven tasks rely on understanding abstract design concepts. These intertwined demands make image-to-poster a multi-dimensional process coupling entity-preserving editing with concept-driven creation under image-prompt control. To address these challenges, we propose PosterOmni, a generalized artistic poster creation framework that unlocks the potential of a base edit model for multi-task image-to-poster generation. PosterOmni integrates the two regimes, namely local editing and global creation, within a single system through an efficient data-distillation-reward pipeline: (i) constructing multi-scenario image-to-poster datasets covering six task types across entity-based and concept-based creation; (ii) distilling knowledge between local and global experts for supervised fine-tuning; and (iii) applying unified PosterOmni Reward Feedback to jointly align visual entity-preserving and aesthetic preference across all tasks. Additionally, we establish PosterOmni-Bench, a unified benchmark for evaluating both local editing and global creation. Extensive experiments show that PosterOmni significantly enhances reference adherence, global composition quality, and aesthetic harmony, outperforming all open-source baselines and even surpassing several proprietary systems.
RoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation
Dec 29, 2025The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts (approximately 1 hour of real robot interaction), while retaining strong generalization across tasks. Project website: https://robo-dopamine.github.io
AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Jul 02, 2025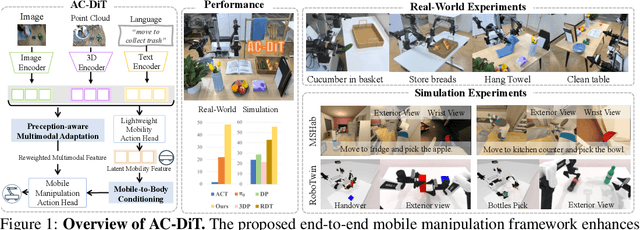
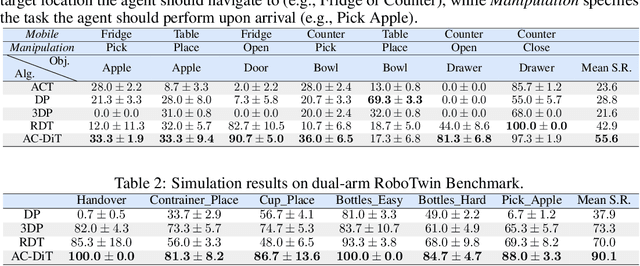
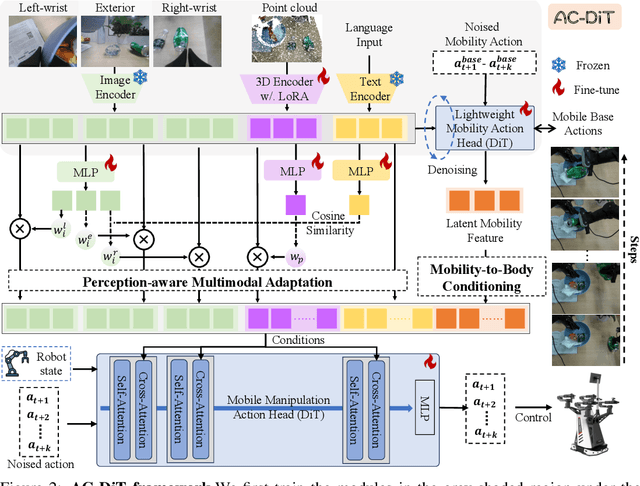

Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
Apr 05, 2025



Vision-centric perception systems struggle with unpredictable and coupled weather degradations in the wild. Current solutions are often limited, as they either depend on specific degradation priors or suffer from significant domain gaps. To enable robust and autonomous operation in real-world conditions, we propose JarvisIR, a VLM-powered agent that leverages the VLM as a controller to manage multiple expert restoration models. To further enhance system robustness, reduce hallucinations, and improve generalizability in real-world adverse weather, JarvisIR employs a novel two-stage framework consisting of supervised fine-tuning and human feedback alignment. Specifically, to address the lack of paired data in real-world scenarios, the human feedback alignment enables the VLM to be fine-tuned effectively on large-scale real-world data in an unsupervised manner. To support the training and evaluation of JarvisIR, we introduce CleanBench, a comprehensive dataset consisting of high-quality and large-scale instruction-responses pairs, including 150K synthetic entries and 80K real entries. Extensive experiments demonstrate that JarvisIR exhibits superior decision-making and restoration capabilities. Compared with existing methods, it achieves a 50% improvement in the average of all perception metrics on CleanBench-Real. Project page: https://cvpr2025-jarvisir.github.io/.
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Mar 13, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods leverage large-scale pretrained knowledge, they disrupt the continuity of actions. Meanwhile, some VLA methods incorporate an additional diffusion head to predict continuous actions, relying solely on VLM-extracted features, which limits their reasoning capabilities. In this paper, we introduce HybridVLA, a unified framework that seamlessly integrates the strengths of both autoregressive and diffusion policies within a single large language model, rather than simply connecting them. To bridge the generation gap, a collaborative training recipe is proposed that injects the diffusion modeling directly into the next-token prediction. With this recipe, we find that these two forms of action prediction not only reinforce each other but also exhibit varying performance across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses these two predictions, leading to more robust control. In experiments, HybridVLA outperforms previous state-of-the-art VLA methods across various simulation and real-world tasks, including both single-arm and dual-arm robots, while demonstrating stable manipulation in previously unseen configurations.