 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO-WA: Hybrid-Attention Latent-Guided Online Reinforcement Learning for World-Action Models
Jul 05, 2026World-action (WA) models can generate long-horizon action chunks for general-purpose robotic manipulation, but they remain vulnerable to calibration, perception, and contact-dynamics errors in real-world precision tasks, often failing in the final few millimeters of alignment or insertion. We propose HALO-WA, a hybrid-attention latent-guided online reinforcement learning (RL) framework for WA models, which leverages latent features and action priors from the WA generation process through a lightweight actor-critic adapter to enable fast online adaptation to real deployment errors. HALO-WA introduces a hybrid-attention structure that preserves the temporal consistency of action chunks while reading task-relevant information from WA latents conditioned on visual context and end-stage correction requirements, thereby producing refined action chunks. We validate HALO-WA on four real-world precision manipulation tasks, where it improves the average success rate from 26.4\% for WA-base to 87.1\%, outperforming the strongest baseline by 19.2 percentage points while requiring only 45--75 minutes of online training per task. To facilitate reproducibility, we further conduct supplementary simulation experiments in RoboTwin and release the code at https://github.com/YeanRoot/HALO-WA.
GigaWorld-1: A Roadmap to Build World Models for Robot Policy Evaluation
Jul 02, 2026Evaluating embodied robot foundation models remains a critical bottleneck; unlike large language models efficiently assessed via digital benchmarks, robotic policies require slow, costly real-world rollouts limited by hardware and human supervision, which has driven interest in world models as surrogate policy evaluators, yet the key properties that make a world model reliable for policy assessment remain poorly understood. This work presents a systematic study of world models for robotic policy evaluation and introduces WMBench, a benchmark constructed from real-robot teleoperation data and matched policy rollouts covering diverse manipulation tasks to enable controlled comparisons across model families, action encodings, rollout horizons, and evaluation metrics. Using WMBench, we analyze 7 video world models, 4 action representation schemes, and over 324,000 simulated policy rollouts paired with real robot executions, further enriching our analysis with large-scale community submissions from the CVPR 2026 GigaBrain Challenge, curated synthetic trajectories, and a training videos spanning more than 12,000 hours. Our experiments deliver three core insights: evaluator quality is dominated by long-horizon, action-faithful rollout consistency rather than short-term visual realism; pretraining gains stem not only from data scale but from balancing general world knowledge with robot-specific controllability; and architectural choices including action encoding, memory design, and evaluator-focused post-training strongly determine alignment with real-world robot behavior. Drawing on these results, we derive a practical design roadmap and realize it in \textit{GigaWorld-1}, a world model specially optimized for policy evaluation, and we fully release our code, models, datasets, and toolkits to advance scalable evaluation research for embodied foundation models.
Towards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
May 31, 2026With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
VAG: Dual-Stream Video-Action Generation for Embodied Data Synthesis
Apr 10, 2026Recent advances in robot foundation models trained on large-scale human teleoperation data have enabled robots to perform increasingly complex real-world tasks. However, scaling these systems remains difficult because collecting task-specific demonstrations is expensive and labor-intensive. Synthetic data, especially generated videos, offer a promising direction, but existing World Models (WMs) are not directly suitable for policy learning since they do not provide paired action trajectories. World-Action (WA) models partially address this by predicting actions with visual outputs, yet often lack strong video-action alignment, while two-stage pipelines that generate video first and then infer actions introduce inefficiency and error accumulation. To address these limitations, we propose VAG, a unified flow-matching-based dual-stream framework that jointly generates video and action under visual and language conditioning. By synchronizing denoising in both branches and using an adaptive 3D pooling mechanism to transfer compact global video context to the action branch, VAG improves cross-modal consistency during generation. Across both simulated and real-world settings, VAG produces aligned video-action pairs with competitive prediction quality, supports executable trajectory replay, and provides useful synthetic pretraining data that improves downstream policy generalization, indicating its potential as a practical world-action model for embodied data synthesis.
ReconPhys: Reconstruct Appearance and Physical Attributes from Single Video
Apr 09, 2026Reconstructing non-rigid objects with physical plausibility remains a significant challenge. Existing approaches leverage differentiable rendering for per-scene optimization, recovering geometry and dynamics but requiring expensive tuning or manual annotation, which limits practicality and generalizability. To address this, we propose ReconPhys, the first feedforward framework that jointly learns physical attribute estimation and 3D Gaussian Splatting reconstruction from a single monocular video. Our method employs a dual-branch architecture trained via a self-supervised strategy, eliminating the need for ground-truth physics labels. Given a video sequence, ReconPhys simultaneously infers geometry, appearance, and physical attributes. Experiments on a large-scale synthetic dataset demonstrate superior performance: our method achieves 21.64 PSNR in future prediction compared to 13.27 by state-of-the-art optimization baselines, while reducing Chamfer Distance from 0.349 to 0.004. Crucially, ReconPhys enables fast inference (<1 second) versus hours required by existing methods, facilitating rapid generation of simulation-ready assets for robotics and graphics.
ViVa: A Video-Generative Value Model for Robot Reinforcement Learning
Apr 09, 2026Vision-language-action (VLA) models have advanced robot manipulation through large-scale pretraining, but real-world deployment remains challenging due to partial observability and delayed feedback. Reinforcement learning addresses this via value functions, which assess task progress and guide policy improvement. However, existing value models built on vision-language models (VLMs) struggle to capture temporal dynamics, undermining reliable value estimation in long-horizon tasks. In this paper, we propose ViVa, a video-generative value model that repurposes a pretrained video generator for value estimation. Taking the current observation and robot proprioception as input, ViVa jointly predicts future proprioception and a scalar value for the current state. By leveraging the spatiotemporal priors of a pretrained video generator, our approach grounds value estimation in anticipated embodiment dynamics, moving beyond static snapshots to intrinsically couple value with foresight. Integrated into RECAP, ViVa delivers substantial improvements on real-world box assembly. Qualitative analysis across all three tasks confirms that ViVa produces more reliable value signals, accurately reflecting task progress. By leveraging spatiotemporal priors from video corpora, ViVa also generalizes to novel objects, highlighting the promise of video-generative models for value estimation.
GigaWorld-Policy: An Efficient Action-Centered World--Action Model
Mar 18, 2026World-Action Models (WAM) initialized from pre-trained video generation backbones have demonstrated remarkable potential for robot policy learning. However, existing approaches face two critical bottlenecks that hinder performance and deployment. First, jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead. Second, joint modeling often entangles visual and motion representations, making motion prediction accuracy heavily dependent on the quality of future video forecasts. To address these issues, we introduce GigaWorld-Policy, an action-centered WAM that learns 2D pixel-action dynamics while enabling efficient action decoding, with optional video generation. Specifically, we formulate policy training into two coupled components: the model predicts future action sequences conditioned on the current observation, and simultaneously generates future videos conditioned on the predicted actions and the same observation. The policy is supervised by both action prediction and video generation, providing richer learning signals and encouraging physically plausible actions through visual-dynamics constraints. With a causal design that prevents future-video tokens from influencing action tokens, explicit future-video generation is optional at inference time, allowing faster action prediction during deployment. To support this paradigm, we curate a diverse, large-scale robot dataset to pre-train an action-centered video generation model, which is then adapted as the backbone for robot policy learning. Experimental results on real-world robotic platforms show that GigaWorld-Policy runs 9x faster than the leading WAM baseline, Motus, while improving task success rates by 7%. Moreover, compared with pi-0.5, GigaWorld-Policy improves performance by 95% on RoboTwin 2.0.
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Feb 12, 2026Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose \textit{GigaBrain-0.5M*}, a VLA model trained via world model-based reinforcement learning. Built upon \textit{GigaBrain-0.5}, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. \textit{GigaBrain-0.5M*} further integrates world model-based reinforcement learning via \textit{RAMP} (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that \textit{RAMP} achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30\% on challenging tasks including \texttt{Laundry Folding}, \texttt{Box Packing}, and \texttt{Espresso Preparation}. Critically, \textit{GigaBrain-0.5M$^*$} exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our \href{https://gigabrain05m.github.io}{project page}.
EMMA: Generalizing Real-World Robot Manipulation via Generative Visual Transfer
Sep 26, 2025
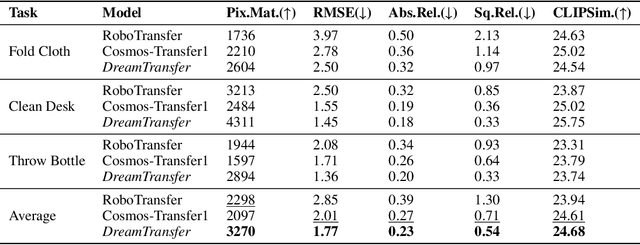
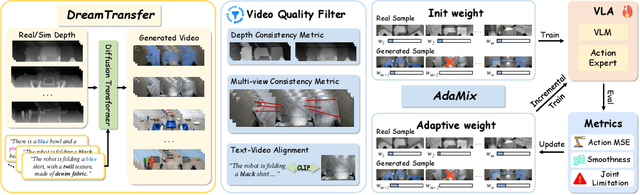
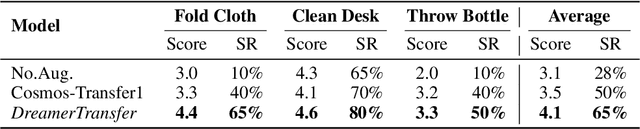
Vision-language-action (VLA) models increasingly rely on diverse training data to achieve robust generalization. However, collecting large-scale real-world robot manipulation data across varied object appearances and environmental conditions remains prohibitively time-consuming and expensive. To overcome this bottleneck, we propose Embodied Manipulation Media Adaptation (EMMA), a VLA policy enhancement framework that integrates a generative data engine with an effective training pipeline. We introduce DreamTransfer, a diffusion Transformer-based framework for generating multi-view consistent, geometrically grounded embodied manipulation videos. DreamTransfer enables text-controlled visual editing of robot videos, transforming foreground, background, and lighting conditions without compromising 3D structure or geometrical plausibility. Furthermore, we explore hybrid training with real and generated data, and introduce AdaMix, a hard-sample-aware training strategy that dynamically reweights training batches to focus optimization on perceptually or kinematically challenging samples. Extensive experiments show that videos generated by DreamTransfer significantly outperform prior video generation methods in multi-view consistency, geometric fidelity, and text-conditioning accuracy. Crucially, VLAs trained with generated data enable robots to generalize to unseen object categories and novel visual domains using only demonstrations from a single appearance. In real-world robotic manipulation tasks with zero-shot visual domains, our approach achieves over a 200% relative performance gain compared to training on real data alone, and further improves by 13% with AdaMix, demonstrating its effectiveness in boosting policy generalization.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025



Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.