 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-GRM: Large Gaussian Reconstruction Model for Sparse-view X-rays to Computed Tomography
May 21, 2025



Computed Tomography serves as an indispensable tool in clinical workflows, providing non-invasive visualization of internal anatomical structures. Existing CT reconstruction works are limited to small-capacity model architecture, inflexible volume representation, and small-scale training data. In this paper, we present X-GRM (X-ray Gaussian Reconstruction Model), a large feedforward model for reconstructing 3D CT from sparse-view 2D X-ray projections. X-GRM employs a scalable transformer-based architecture to encode an arbitrary number of sparse X-ray inputs, where tokens from different views are integrated efficiently. Then, tokens are decoded into a new volume representation, named Voxel-based Gaussian Splatting (VoxGS), which enables efficient CT volume extraction and differentiable X-ray rendering. To support the training of X-GRM, we collect ReconX-15K, a large-scale CT reconstruction dataset containing around 15,000 CT/X-ray pairs across diverse organs, including the chest, abdomen, pelvis, and tooth etc. This combination of a high-capacity model, flexible volume representation, and large-scale training data empowers our model to produce high-quality reconstructions from various testing inputs, including in-domain and out-domain X-ray projections. Project Page: https://github.com/CUHK-AIM-Group/X-GRM.
Regularized Context Gates on Transformer for Machine Translation
Aug 29, 2019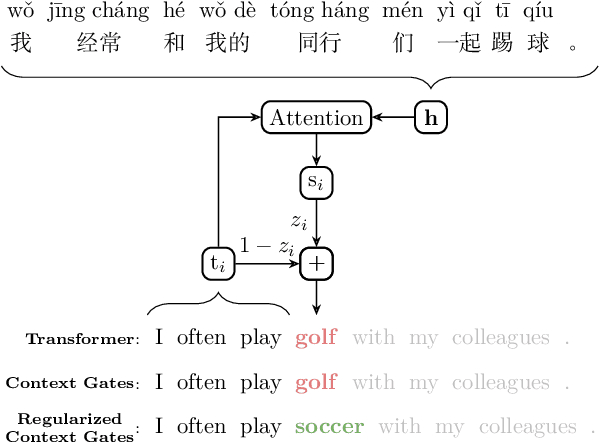
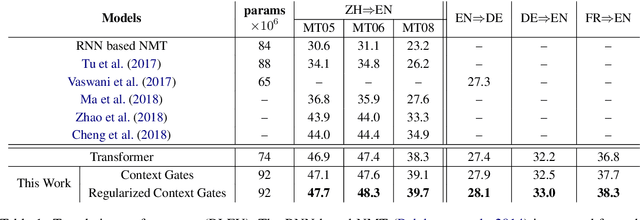
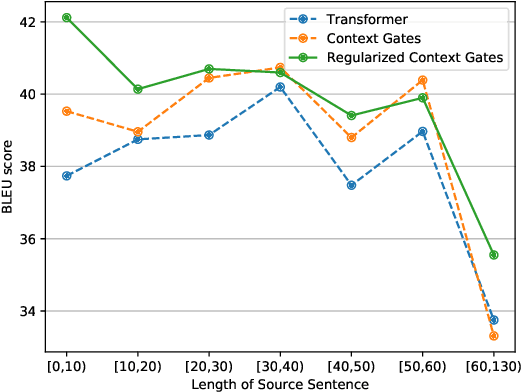
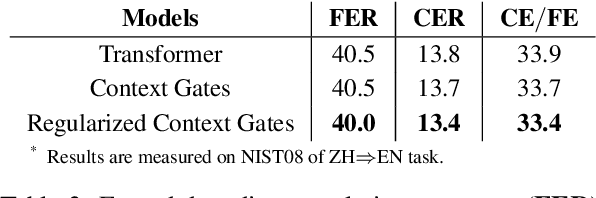
Context gates are effective to control the contributions from the source and target contexts in the recurrent neural network (RNN) based neural machine translation (NMT). However, it is challenging to extend them into the advanced Transformer architecture, which is more complicated than RNN. This paper first provides a method to identify source and target contexts and then introduce a gate mechanism to control the source and target contributions in Transformer. In addition, to further reduce the bias problem in the gate mechanism, this paper proposes a regularization method to guide the learning of the gates with supervision automatically generated using pointwise mutual information. Extensive experiments on 4 translation datasets demonstrate that the proposed model obtains an averaged gain of 1.0 BLEU score over strong Transformer baseline.