 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymmetric Network with Spatial Relationship Modeling for Natural Language-based Vehicle Retrieval
Jun 22, 2022


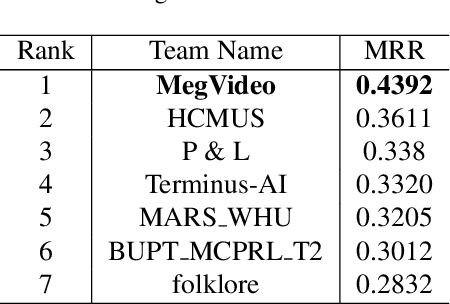
Natural language (NL) based vehicle retrieval aims to search specific vehicle given text description. Different from the image-based vehicle retrieval, NL-based vehicle retrieval requires considering not only vehicle appearance, but also surrounding environment and temporal relations. In this paper, we propose a Symmetric Network with Spatial Relationship Modeling (SSM) method for NL-based vehicle retrieval. Specifically, we design a symmetric network to learn the unified cross-modal representations between text descriptions and vehicle images, where vehicle appearance details and vehicle trajectory global information are preserved. Besides, to make better use of location information, we propose a spatial relationship modeling methods to take surrounding environment and mutual relationship between vehicles into consideration. The qualitative and quantitative experiments verify the effectiveness of the proposed method. We achieve 43.92% MRR accuracy on the test set of the 6th AI City Challenge on natural language-based vehicle retrieval track, yielding the 1st place among all valid submissions on the public leaderboard. The code is available at https://github.com/hbchen121/AICITY2022_Track2_SSM.
* 8 pages, 3 figures, publised to CVPRW
Improving Human-Object Interaction Detection via Phrase Learning and Label Composition
Dec 14, 2021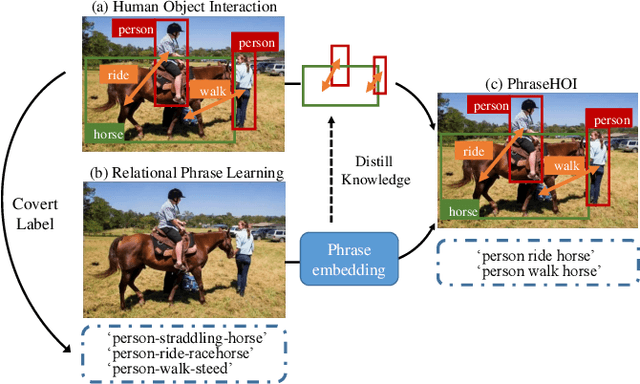
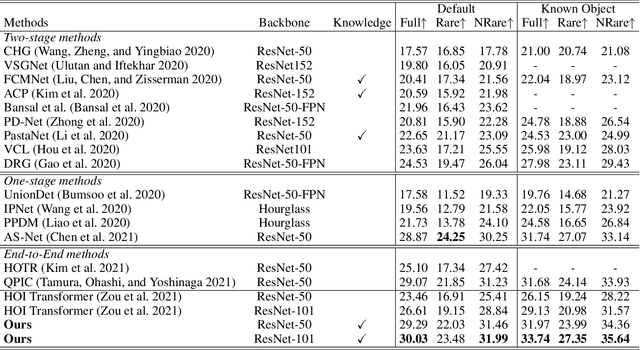
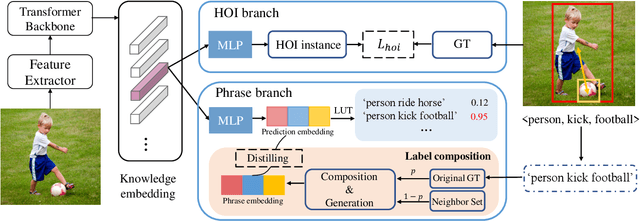

Human-Object Interaction (HOI) detection is a fundamental task in high-level human-centric scene understanding. We propose PhraseHOI, containing a HOI branch and a novel phrase branch, to leverage language prior and improve relation expression. Specifically, the phrase branch is supervised by semantic embeddings, whose ground truths are automatically converted from the original HOI annotations without extra human efforts. Meanwhile, a novel label composition method is proposed to deal with the long-tailed problem in HOI, which composites novel phrase labels by semantic neighbors. Further, to optimize the phrase branch, a loss composed of a distilling loss and a balanced triplet loss is proposed. Extensive experiments are conducted to prove the effectiveness of the proposed PhraseHOI, which achieves significant improvement over the baseline and surpasses previous state-of-the-art methods on Full and NonRare on the challenging HICO-DET benchmark.
Learning Context-Aware Embedding for Person Search
Nov 29, 2021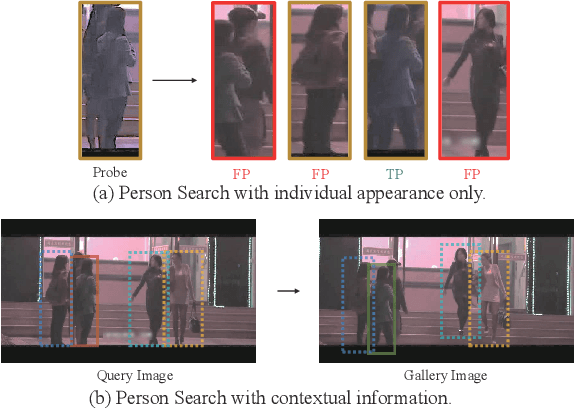
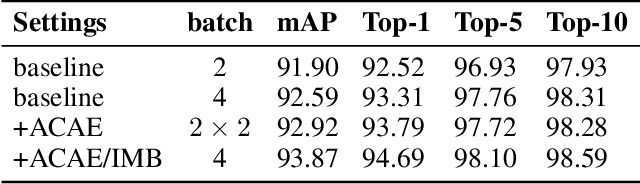
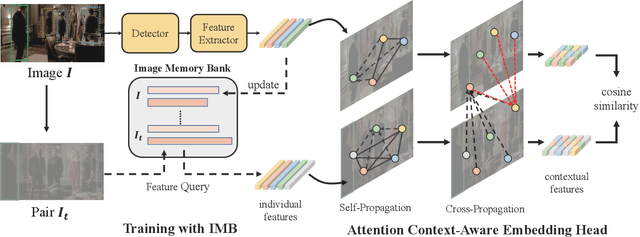
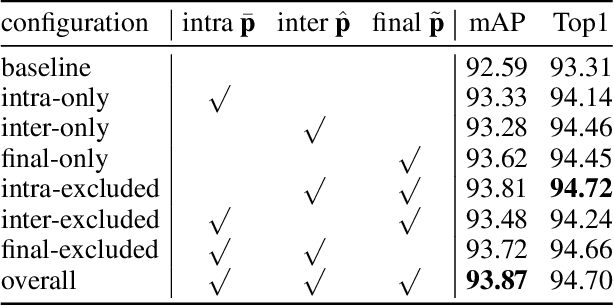
Person Search is a relevant task that aims to jointly solve Person Detection and Person Re-identification(re-ID). Though most previous methods focus on learning robust individual features for retrieval, it's still hard to distinguish confusing persons because of illumination, large pose variance, and occlusion. Contextual information is practically available in person search task which benefits searching in terms of reducing confusion. To this end, we present a novel contextual feature head named Attention Context-Aware Embedding(ACAE) which enhances contextual information. ACAE repeatedly reviews the person features within and across images to find similar pedestrian patterns, allowing it to implicitly learn to find possible co-travelers and efficiently model contextual relevant instances' relations. Moreover, we propose Image Memory Bank to improve the training efficiency. Experimentally, ACAE shows extensive promotion when built on different one-step methods. Our overall methods achieve state-of-the-art results compared with previous one-step methods.
Efficient DETR: Improving End-to-End Object Detector with Dense Prior
Apr 03, 2021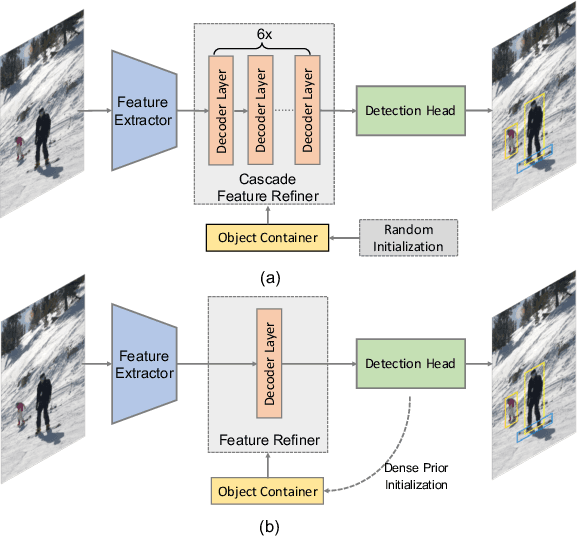

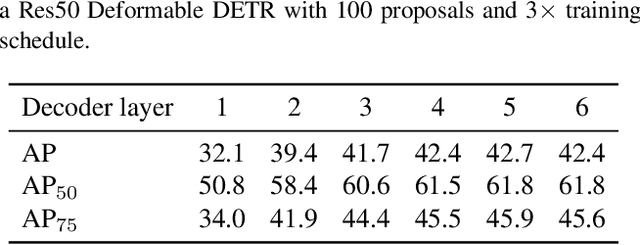

The recently proposed end-to-end transformer detectors, such as DETR and Deformable DETR, have a cascade structure of stacking 6 decoder layers to update object queries iteratively, without which their performance degrades seriously. In this paper, we investigate that the random initialization of object containers, which include object queries and reference points, is mainly responsible for the requirement of multiple iterations. Based on our findings, we propose Efficient DETR, a simple and efficient pipeline for end-to-end object detection. By taking advantage of both dense detection and sparse set detection, Efficient DETR leverages dense prior to initialize the object containers and brings the gap of the 1-decoder structure and 6-decoder structure. Experiments conducted on MS COCO show that our method, with only 3 encoder layers and 1 decoder layer, achieves competitive performance with state-of-the-art object detection methods. Efficient DETR is also robust in crowded scenes. It outperforms modern detectors on CrowdHuman dataset by a large margin.
End-to-End Human Object Interaction Detection with HOI Transformer
Mar 08, 2021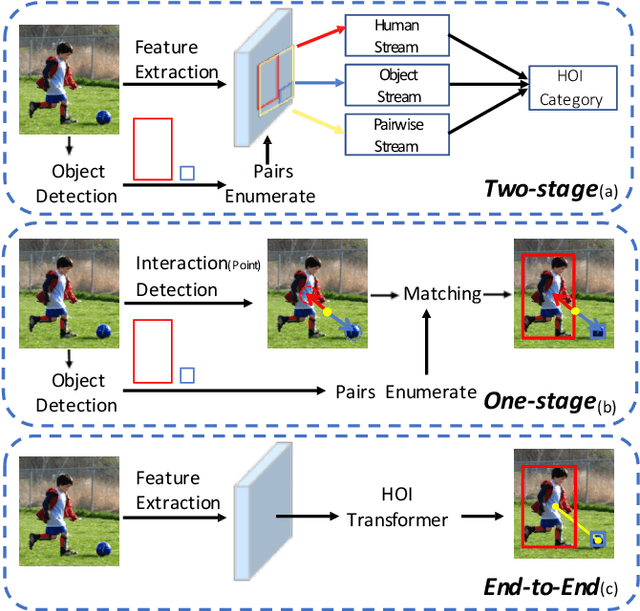
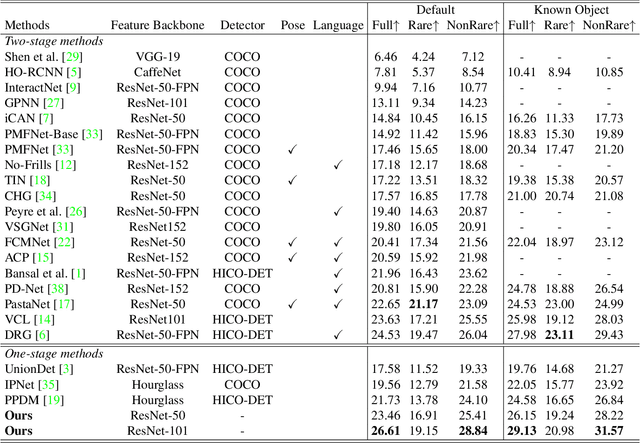
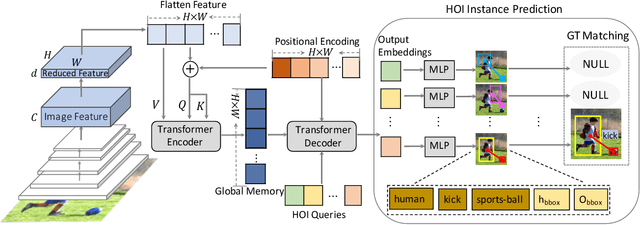

We propose HOI Transformer to tackle human object interaction (HOI) detection in an end-to-end manner. Current approaches either decouple HOI task into separated stages of object detection and interaction classification or introduce surrogate interaction problem. In contrast, our method, named HOI Transformer, streamlines the HOI pipeline by eliminating the need for many hand-designed components. HOI Transformer reasons about the relations of objects and humans from global image context and directly predicts HOI instances in parallel. A quintuple matching loss is introduced to force HOI predictions in a unified way. Our method is conceptually much simpler and demonstrates improved accuracy. Without bells and whistles, HOI Transformer achieves $26.61\% $ $ AP $ on HICO-DET and $52.9\%$ $AP_{role}$ on V-COCO, surpassing previous methods with the advantage of being much simpler. We hope our approach will serve as a simple and effective alternative for HOI tasks. Code is available at https://github.com/bbepoch/HoiTransformer .
Double Anchor R-CNN for Human Detection in a Crowd
Sep 22, 2019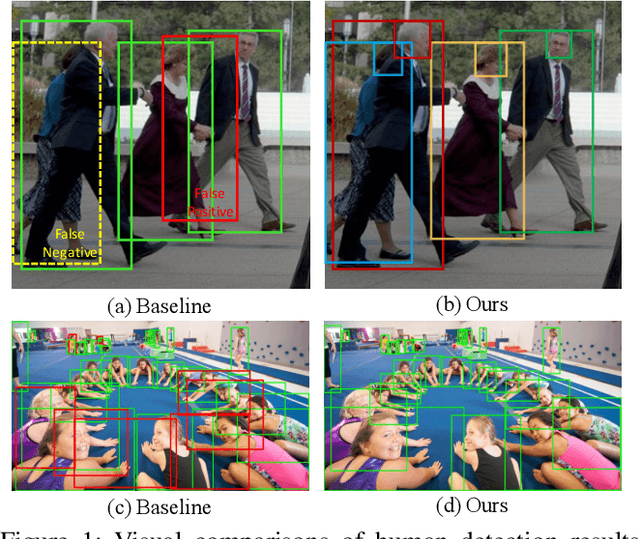

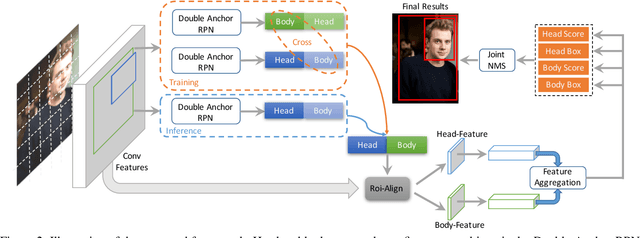
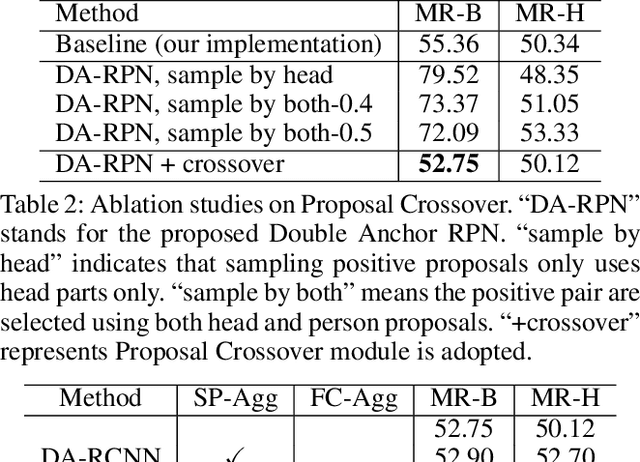
Detecting human in a crowd is a challenging problem due to the uncertainties of occlusion patterns. In this paper, we propose to handle the crowd occlusion problem in human detection by leveraging the head part. Double Anchor RPN is developed to capture body and head parts in pairs. A proposal crossover strategy is introduced to generate high-quality proposals for both parts as a training augmentation. Features of coupled proposals are then aggregated efficiently to exploit the inherent relationship. Finally, a Joint NMS module is developed for robust post-processing. The proposed framework, called Double Anchor R-CNN, is able to detect the body and head for each person simultaneously in crowded scenarios. State-of-the-art results are reported on challenging human detection datasets. Our model yields log-average miss rates (MR) of 51.79pp on CrowdHuman, 55.01pp on COCOPersons~(crowded sub-dataset) and 40.02pp on CrowdPose~(crowded sub-dataset), which outperforms previous baseline detectors by 3.57pp, 3.82pp, and 4.24pp, respectively. We hope our simple and effective approach will serve as a solid baseline and help ease future research in crowded human detection.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019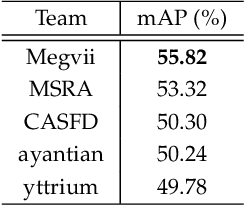

This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
CrowdHuman: A Benchmark for Detecting Human in a Crowd
Apr 30, 2018
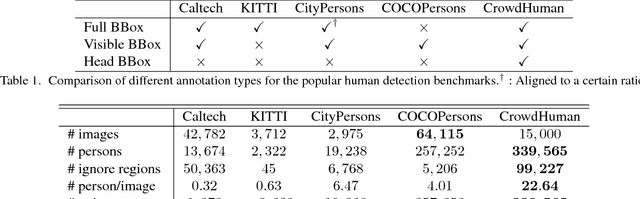

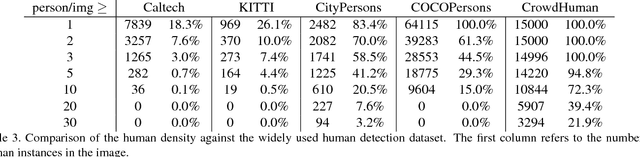
Human detection has witnessed impressive progress in recent years. However, the occlusion issue of detecting human in highly crowded environments is far from solved. To make matters worse, crowd scenarios are still under-represented in current human detection benchmarks. In this paper, we introduce a new dataset, called CrowdHuman, to better evaluate detectors in crowd scenarios. The CrowdHuman dataset is large, rich-annotated and contains high diversity. There are a total of $470K$ human instances from the train and validation subsets, and $~22.6$ persons per image, with various kinds of occlusions in the dataset. Each human instance is annotated with a head bounding-box, human visible-region bounding-box and human full-body bounding-box. Baseline performance of state-of-the-art detection frameworks on CrowdHuman is presented. The cross-dataset generalization results of CrowdHuman dataset demonstrate state-of-the-art performance on previous dataset including Caltech-USA, CityPersons, and Brainwash without bells and whistles. We hope our dataset will serve as a solid baseline and help promote future research in human detection tasks.
SFace: An Efficient Network for Face Detection in Large Scale Variations
Apr 23, 2018
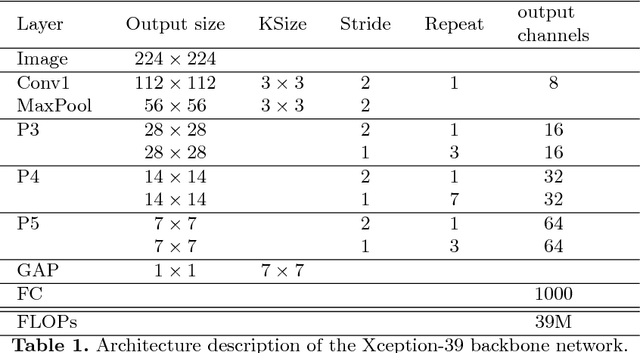
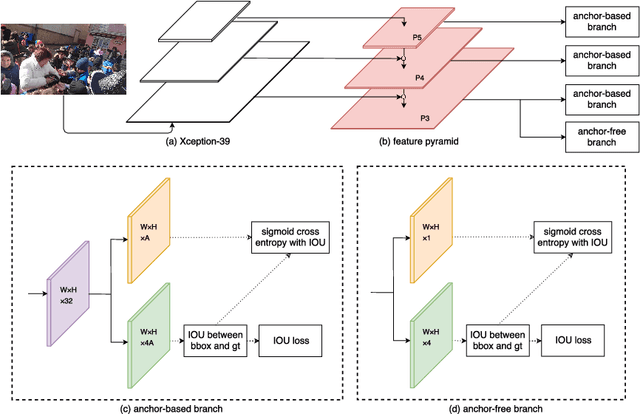
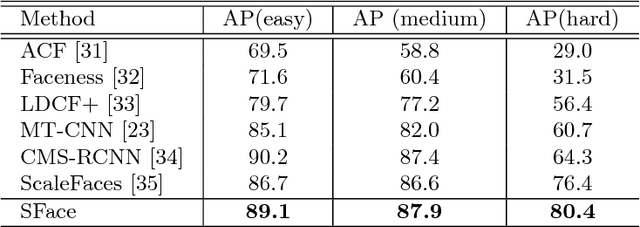
Face detection serves as a fundamental research topic for many applications like face recognition. Impressive progress has been made especially with the recent development of convolutional neural networks. However, the issue of large scale variations, which widely exists in high resolution images/videos, has not been well addressed in the literature. In this paper, we present a novel algorithm called SFace, which efficiently integrates the anchor-based method and anchor-free method to address the scale issues. A new dataset called 4K-Face is also introduced to evaluate the performance of face detection with extreme large scale variations. The SFace architecture shows promising results on the new 4K-Face benchmarks. In addition, our method can run at 50 frames per second (fps) with an accuracy of 80% AP on the standard WIDER FACE dataset, which outperforms the state-of-art algorithms by almost one order of magnitude in speed while achieves comparative performance.