 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Impact of Lossy Compression on Neural Generative Surrogate Modeling
Jun 14, 2026Neural networks are used as generative surrogate models for scientific discovery, which are trainable approximations of scientific simulations. These models enable users to replace time-consuming numerical simulations with learned alternatives, providing quick solutions. However, high-fidelity generative surrogate models require massive training datasets, which can create storage and I/O challenges. Lossy compression is a promising way to reduce this burden, but compression errors may affect the model quality in subtle ways, making it challenging to quantify their impact. In this work, we examine how lossy compression of training data impacts the quality of generative surrogate models. We begin by characterizing the uncertainty inherent in training neural networks, showing that identical training configurations can produce different models. By exploiting this variability, we propose a method to estimate how much compression-induced error a surrogate model can tolerate without affecting its accuracy. Evaluation of two application simulations demonstrates that our approach significantly reduces memory/storage requirements and speeds up training while producing high-quality surrogate models. These results show that lossy compression saves data storage up to 23.7x and 39x with negligible impact on the quality of the surrogate model. Meanwhile, reducing the size of the training data set also enhances the data loading speed and reduces the training time by up to 3x.
Toward AI VIS Co-Scientists: A General and End-to-End Agent Harness for Solving Complex Data Visualization Tasks
May 20, 2026The ability to inspect, interpret, and communicate complex data is crucial for virtually any scientific endeavor, but often requires significant expertise outside the core domain ranging from data management and analysis to visualization design and implementation. We present an end-to-end agentic harness that, based on only the data and a high level description of the tasks, independently designs custom visual analysis applications (VIS apps). This represents an important step towards a general AI co-scientist envisioned by many as an autonomous system that can autonomously execute long horizon tasks based on high-level directions. Our proposed VIS co-scientist is an essential component of this broader AI co-scientist vision: a harness that can autonomously analyze data and design visualization solutions using a collection of agents and specialized skills that coordinate exploratory analysis, plan, configure the environment, implement, validate the interface, and most importantly evaluate the overall task completion. Each stage produces document and instruction artifacts that guide downstream work and enable iterative refinement. We validate this approach on IEEE SciVis Contests spanning multiple science and engineering fields. These contests serve as ideal proving grounds because they encode real-world complexity: ambiguous requirements, diverse data modalities, design trade-offs, and task-driven validation. Given only the data and target tasks, our system autonomously produces functional single-page VIS Apps with verified linked-view behavior, highly customized to domain experts' specified tasks and needs.
VisionCreator-R1: A Reflection-Enhanced Native Visual-Generation Agentic Model
Mar 09, 2026Visual content generation has advanced from single-image to multi-image workflows, yet existing agents remain largely plan-driven and lack systematic reflection mechanisms to correct mid-trajectory visual errors. To address this limitation, we propose VisionCreator-R1, a native visual generation agent with explicit reflection, together with a Reflection-Plan Co-Optimization (RPCO) training methodology. Through extensive experiments and trajectory-level analysis, we uncover reflection-plan optimization asymmetry in reinforcement learning (RL): planning can be reliably optimized via plan rewards, while reflection learning is hindered by noisy credit assignment. Guided by this insight, our RPCO first trains on the self-constructed VCR-SFT dataset with reflection-strong single-image trajectories and planning-strong multi-image trajectories, then co-optimization on VCR-RL dataset via RL. This yields our unified VisionCreator-R1 agent, which consistently outperforms Gemini2.5Pro on existing benchmarks and our VCR-bench covering single-image and multi-image tasks.
Re-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
An Evaluation-Centric Paradigm for Scientific Visualization Agents
Sep 18, 2025
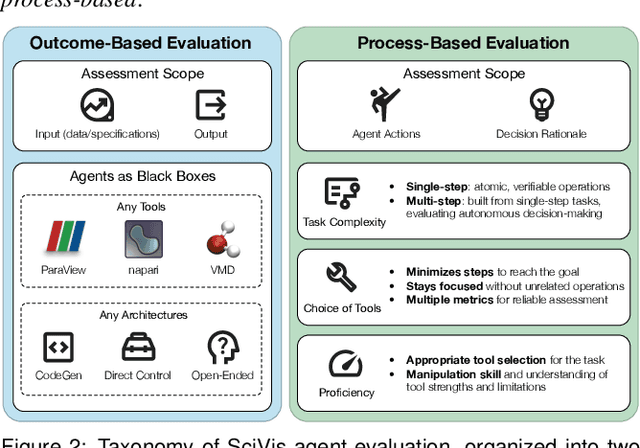
Recent advances in multi-modal large language models (MLLMs) have enabled increasingly sophisticated autonomous visualization agents capable of translating user intentions into data visualizations. However, measuring progress and comparing different agents remains challenging, particularly in scientific visualization (SciVis), due to the absence of comprehensive, large-scale benchmarks for evaluating real-world capabilities. This position paper examines the various types of evaluation required for SciVis agents, outlines the associated challenges, provides a simple proof-of-concept evaluation example, and discusses how evaluation benchmarks can facilitate agent self-improvement. We advocate for a broader collaboration to develop a SciVis agentic evaluation benchmark that would not only assess existing capabilities but also drive innovation and stimulate future development in the field.
Directly Aligning the Full Diffusion Trajectory with Fine-Grained Human Preference
Sep 09, 2025Recent studies have demonstrated the effectiveness of directly aligning diffusion models with human preferences using differentiable reward. However, they exhibit two primary challenges: (1) they rely on multistep denoising with gradient computation for reward scoring, which is computationally expensive, thus restricting optimization to only a few diffusion steps; (2) they often need continuous offline adaptation of reward models in order to achieve desired aesthetic quality, such as photorealism or precise lighting effects. To address the limitation of multistep denoising, we propose Direct-Align, a method that predefines a noise prior to effectively recover original images from any time steps via interpolation, leveraging the equation that diffusion states are interpolations between noise and target images, which effectively avoids over-optimization in late timesteps. Furthermore, we introduce Semantic Relative Preference Optimization (SRPO), in which rewards are formulated as text-conditioned signals. This approach enables online adjustment of rewards in response to positive and negative prompt augmentation, thereby reducing the reliance on offline reward fine-tuning. By fine-tuning the FLUX model with optimized denoising and online reward adjustment, we improve its human-evaluated realism and aesthetic quality by over 3x.
Pref-GRPO: Pairwise Preference Reward-based GRPO for Stable Text-to-Image Reinforcement Learning
Aug 28, 2025Recent advancements highlight the importance of GRPO-based reinforcement learning methods and benchmarking in enhancing text-to-image (T2I) generation. However, current methods using pointwise reward models (RM) for scoring generated images are susceptible to reward hacking. We reveal that this happens when minimal score differences between images are amplified after normalization, creating illusory advantages that drive the model to over-optimize for trivial gains, ultimately destabilizing the image generation process. To address this, we propose Pref-GRPO, a pairwise preference reward-based GRPO method that shifts the optimization objective from score maximization to preference fitting, ensuring more stable training. In Pref-GRPO, images are pairwise compared within each group using preference RM, and the win rate is used as the reward signal. Extensive experiments demonstrate that PREF-GRPO differentiates subtle image quality differences, providing more stable advantages and mitigating reward hacking. Additionally, existing T2I benchmarks are limited by coarse evaluation criteria, hindering comprehensive model assessment. To solve this, we introduce UniGenBench, a unified T2I benchmark comprising 600 prompts across 5 main themes and 20 subthemes. It evaluates semantic consistency through 10 primary and 27 sub-criteria, leveraging MLLM for benchmark construction and evaluation. Our benchmarks uncover the strengths and weaknesses of both open and closed-source T2I models and validate the effectiveness of Pref-GRPO.
TRKT: Weakly Supervised Dynamic Scene Graph Generation with Temporal-enhanced Relation-aware Knowledge Transferring
Aug 07, 2025Dynamic Scene Graph Generation (DSGG) aims to create a scene graph for each video frame by detecting objects and predicting their relationships. Weakly Supervised DSGG (WS-DSGG) reduces annotation workload by using an unlocalized scene graph from a single frame per video for training. Existing WS-DSGG methods depend on an off-the-shelf external object detector to generate pseudo labels for subsequent DSGG training. However, detectors trained on static, object-centric images struggle in dynamic, relation-aware scenarios required for DSGG, leading to inaccurate localization and low-confidence proposals. To address the challenges posed by external object detectors in WS-DSGG, we propose a Temporal-enhanced Relation-aware Knowledge Transferring (TRKT) method, which leverages knowledge to enhance detection in relation-aware dynamic scenarios. TRKT is built on two key components:(1)Relation-aware knowledge mining: we first employ object and relation class decoders that generate category-specific attention maps to highlight both object regions and interactive areas. Then we propose an Inter-frame Attention Augmentation strategy that exploits optical flow for neighboring frames to enhance the attention maps, making them motion-aware and robust to motion blur. This step yields relation- and motion-aware knowledge mining for WS-DSGG. (2) we introduce a Dual-stream Fusion Module that integrates category-specific attention maps into external detections to refine object localization and boost confidence scores for object proposals. Extensive experiments demonstrate that TRKT achieves state-of-the-art performance on Action Genome dataset. Our code is avaliable at https://github.com/XZPKU/TRKT.git.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning
May 06, 2025Recent advances in multimodal Reward Models (RMs) have shown significant promise in delivering reward signals to align vision models with human preferences. However, current RMs are generally restricted to providing direct responses or engaging in shallow reasoning processes with limited depth, often leading to inaccurate reward signals. We posit that incorporating explicit long chains of thought (CoT) into the reward reasoning process can significantly strengthen their reliability and robustness. Furthermore, we believe that once RMs internalize CoT reasoning, their direct response accuracy can also be improved through implicit reasoning capabilities. To this end, this paper proposes UnifiedReward-Think, the first unified multimodal CoT-based reward model, capable of multi-dimensional, step-by-step long-chain reasoning for both visual understanding and generation reward tasks. Specifically, we adopt an exploration-driven reinforcement fine-tuning approach to elicit and incentivize the model's latent complex reasoning ability: (1) We first use a small amount of image generation preference data to distill the reasoning process of GPT-4o, which is then used for the model's cold start to learn the format and structure of CoT reasoning. (2) Subsequently, by leveraging the model's prior knowledge and generalization capabilities, we prepare large-scale unified multimodal preference data to elicit the model's reasoning process across various vision tasks. During this phase, correct reasoning outputs are retained for rejection sampling to refine the model (3) while incorrect predicted samples are finally used for Group Relative Policy Optimization (GRPO) based reinforcement fine-tuning, enabling the model to explore diverse reasoning paths and optimize for correct and robust solutions. Extensive experiments across various vision reward tasks demonstrate the superiority of our model.