 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
Megrez-Omni Technical Report
Feb 19, 2025
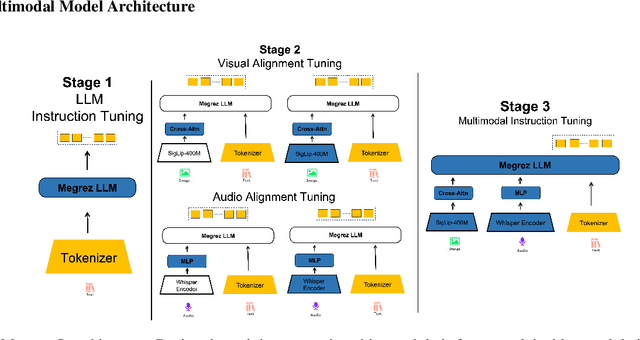


In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
Tracking Objects as Pixel-wise Distributions
Jul 15, 2022
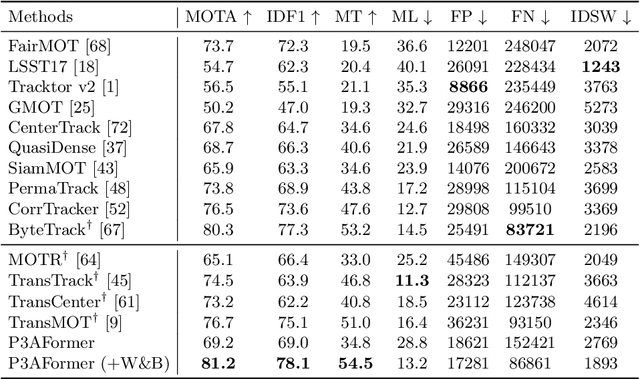
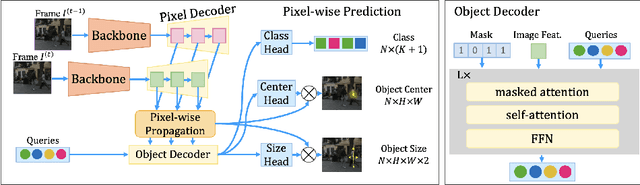
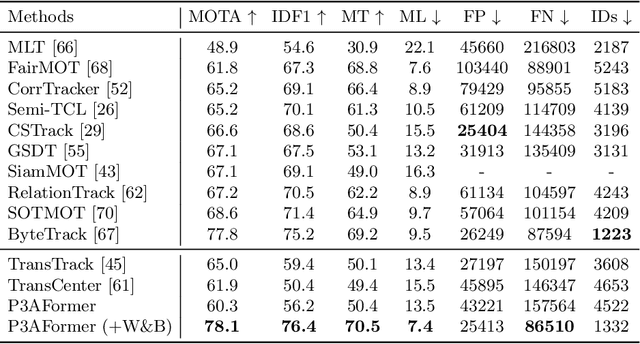
Multi-object tracking (MOT) requires detecting and associating objects through frames. Unlike tracking via detected bounding boxes or tracking objects as points, we propose tracking objects as pixel-wise distributions. We instantiate this idea on a transformer-based architecture, P3AFormer, with pixel-wise propagation, prediction, and association. P3AFormer propagates pixel-wise features guided by flow information to pass messages between frames. Furthermore, P3AFormer adopts a meta-architecture to produce multi-scale object feature maps. During inference, a pixel-wise association procedure is proposed to recover object connections through frames based on the pixel-wise prediction. P3AFormer yields 81.2\% in terms of MOTA on the MOT17 benchmark -- the first among all transformer networks to reach 80\% MOTA in literature. P3AFormer also outperforms state-of-the-arts on the MOT20 and KITTI benchmarks.
Learning Context-Aware Embedding for Person Search
Nov 29, 2021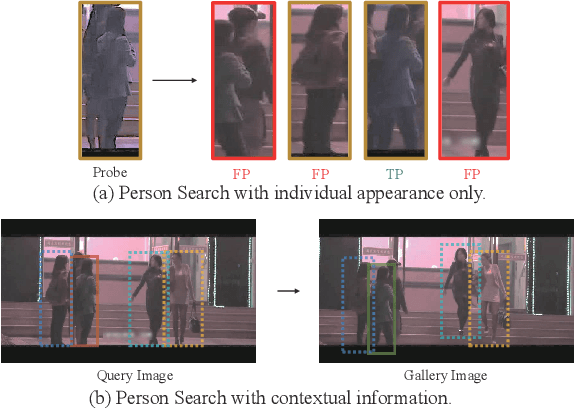
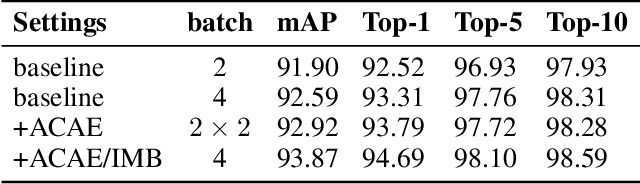
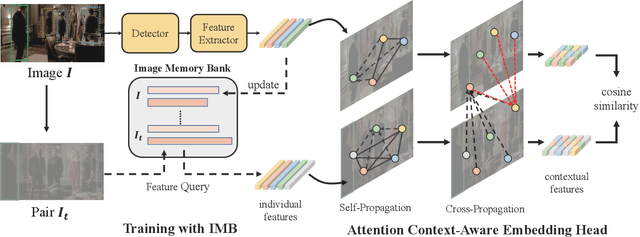
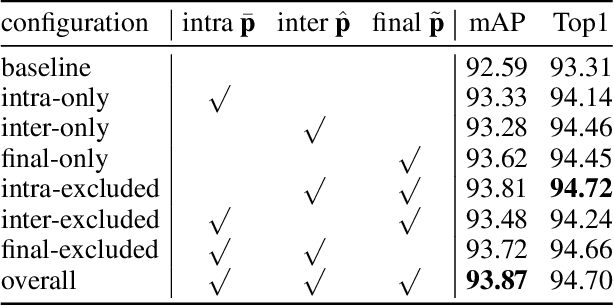
Person Search is a relevant task that aims to jointly solve Person Detection and Person Re-identification(re-ID). Though most previous methods focus on learning robust individual features for retrieval, it's still hard to distinguish confusing persons because of illumination, large pose variance, and occlusion. Contextual information is practically available in person search task which benefits searching in terms of reducing confusion. To this end, we present a novel contextual feature head named Attention Context-Aware Embedding(ACAE) which enhances contextual information. ACAE repeatedly reviews the person features within and across images to find similar pedestrian patterns, allowing it to implicitly learn to find possible co-travelers and efficiently model contextual relevant instances' relations. Moreover, we propose Image Memory Bank to improve the training efficiency. Experimentally, ACAE shows extensive promotion when built on different one-step methods. Our overall methods achieve state-of-the-art results compared with previous one-step methods.
Trajectory Factory: Tracklet Cleaving and Re-connection by Deep Siamese Bi-GRU for Multiple Object Tracking
Apr 12, 2018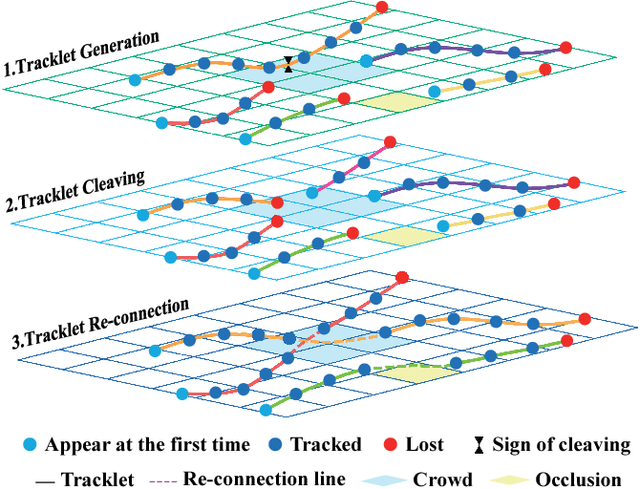
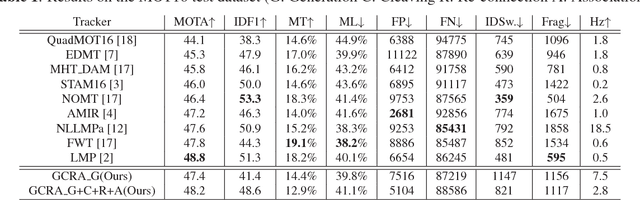
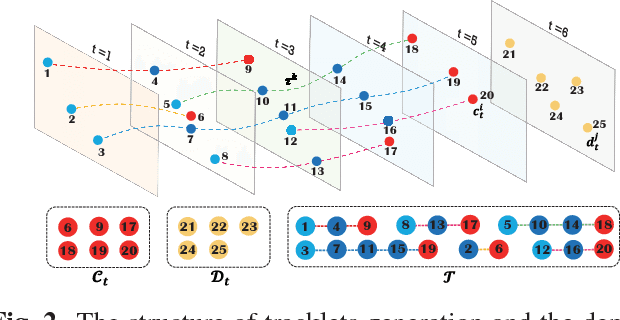
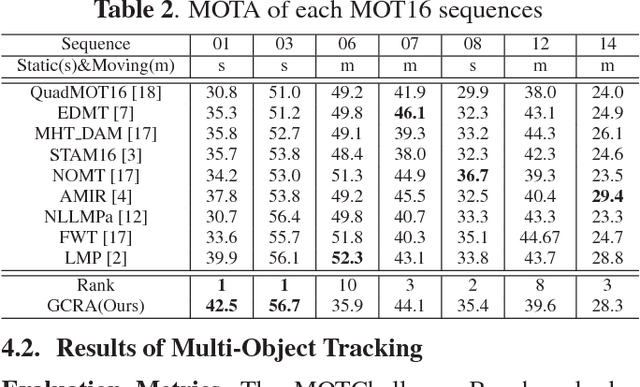
Multi-Object Tracking (MOT) is a challenging task in the complex scene such as surveillance and autonomous driving. In this paper, we propose a novel tracklet processing method to cleave and re-connect tracklets on crowd or long-term occlusion by Siamese Bi-Gated Recurrent Unit (GRU). The tracklet generation utilizes object features extracted by CNN and RNN to create the high-confidence tracklet candidates in sparse scenario. Due to mis-tracking in the generation process, the tracklets from different objects are split into several sub-tracklets by a bidirectional GRU. After that, a Siamese GRU based tracklet re-connection method is applied to link the sub-tracklets which belong to the same object to form a whole trajectory. In addition, we extract the tracklet images from existing MOT datasets and propose a novel dataset to train our networks. The proposed dataset contains more than 95160 pedestrian images. It has 793 different persons in it. On average, there are 120 images for each person with positions and sizes. Experimental results demonstrate the advantages of our model over the state-of-the-art methods on MOT16.