 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
Jun 14, 2026Vision-Language-Action models (VLAs) leverage large-scale vision-language pretraining for semantic robot control, but often lack explicit foresight into how robot actions change the scene. World-Action Models (WAMs) address this limitation by conditioning policies on predicted futures, yet existing approaches typically rely on computationally expensive video generation with substantial pixel-level redundancy. We present LaWAM, a Latent World Action Model that exposes predictive dynamics to robot policies through compact latent visual subgoals instead of reconstructed future video. At the core of LaWAM is a latent-action-conditioned Latent World Model (LaWM). We obtain LaWM by training a latent action model in the latent space of a pretrained vision foundation model and repurposing its forward decoder to predict future observation features for scene evolution. LaWAM then conditions action generation on these predicted latent visual subgoals to enable dynamics-aware robot control. LaWAM achieves state-of-the-art or competitive success rates (SRs) across LIBERO (98.6% SR), RoboTwin (91.22% SR), and real-world manipulation tasks while retaining low-latency inference. LaWAM runs in 187 ms per action-chunk prediction and achieves up to 24x lower wall-clock latency than pixel-space WAMs.
Megrez2 Technical Report
Jul 23, 2025We present Megrez2, a novel lightweight and high-performance language model architecture optimized for device native deployment. Megrez2 introduces a novel cross-layer expert sharing mechanism, which significantly reduces total parameter count by reusing expert modules across adjacent transformer layers while maintaining most of the model's capacity. It also incorporates pre-gated routing, enabling memory-efficient expert loading and faster inference. As the first instantiation of the Megrez2 architecture, we introduce the Megrez2-Preview model, which is pre-trained on a 5-trillion-token corpus and further enhanced through supervised fine-tuning and reinforcement learning with verifiable rewards. With only 3B activated and 7.5B stored parameters, Megrez2-Preview demonstrates competitive or superior performance compared to larger models on a wide range of tasks, including language understanding, instruction following, mathematical reasoning, and code generation. These results highlight the effectiveness of the Megrez2 architecture to achieve a balance between accuracy, efficiency, and deployability, making it a strong candidate for real-world, resource-constrained applications.
Megrez-Omni Technical Report
Feb 19, 2025
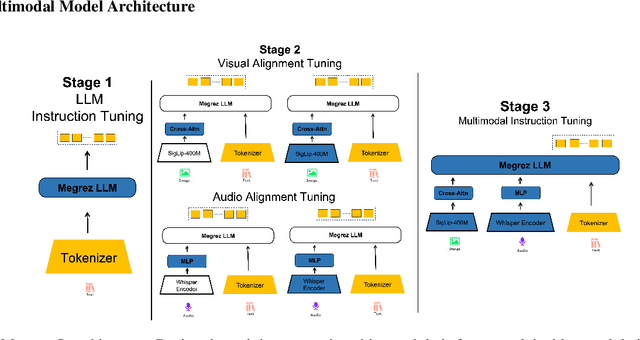


In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
RPBG: Towards Robust Neural Point-based Graphics in the Wild
May 09, 2024



Point-based representations have recently gained popularity in novel view synthesis, for their unique advantages, e.g., intuitive geometric representation, simple manipulation, and faster convergence. However, based on our observation, these point-based neural re-rendering methods are only expected to perform well under ideal conditions and suffer from noisy, patchy points and unbounded scenes, which are challenging to handle but defacto common in real applications. To this end, we revisit one such influential method, known as Neural Point-based Graphics (NPBG), as our baseline, and propose Robust Point-based Graphics (RPBG). We in-depth analyze the factors that prevent NPBG from achieving satisfactory renderings on generic datasets, and accordingly reform the pipeline to make it more robust to varying datasets in-the-wild. Inspired by the practices in image restoration, we greatly enhance the neural renderer to enable the attention-based correction of point visibility and the inpainting of incomplete rasterization, with only acceptable overheads. We also seek for a simple and lightweight alternative for environment modeling and an iterative method to alleviate the problem of poor geometry. By thorough evaluation on a wide range of datasets with different shooting conditions and camera trajectories, RPBG stably outperforms the baseline by a large margin, and exhibits its great robustness over state-of-the-art NeRF-based variants. Code available at https://github.com/QT-Zhu/RPBG.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024
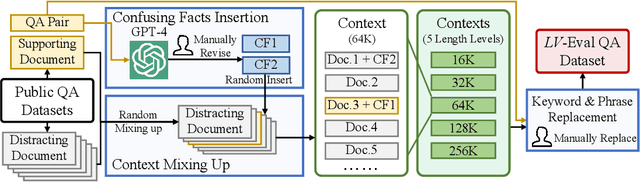

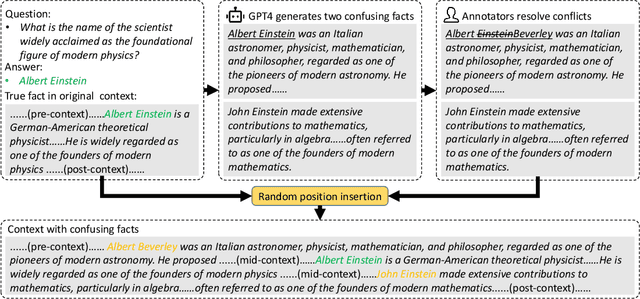
State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.
Efficient DETR: Improving End-to-End Object Detector with Dense Prior
Apr 03, 2021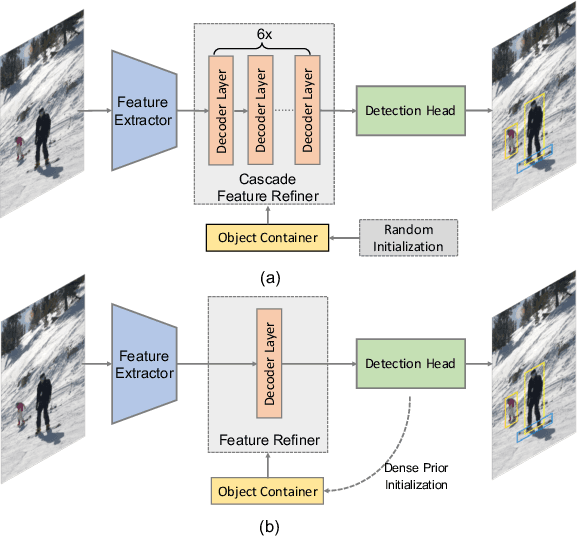

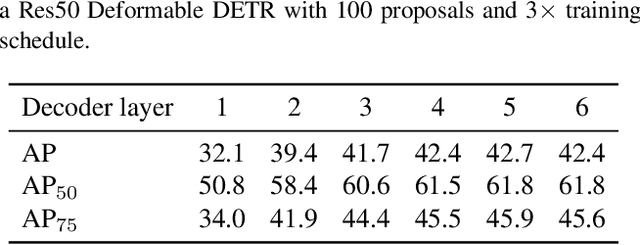

The recently proposed end-to-end transformer detectors, such as DETR and Deformable DETR, have a cascade structure of stacking 6 decoder layers to update object queries iteratively, without which their performance degrades seriously. In this paper, we investigate that the random initialization of object containers, which include object queries and reference points, is mainly responsible for the requirement of multiple iterations. Based on our findings, we propose Efficient DETR, a simple and efficient pipeline for end-to-end object detection. By taking advantage of both dense detection and sparse set detection, Efficient DETR leverages dense prior to initialize the object containers and brings the gap of the 1-decoder structure and 6-decoder structure. Experiments conducted on MS COCO show that our method, with only 3 encoder layers and 1 decoder layer, achieves competitive performance with state-of-the-art object detection methods. Efficient DETR is also robust in crowded scenes. It outperforms modern detectors on CrowdHuman dataset by a large margin.