 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaplacian Multi-scale Flow Matching for Generative Modeling
Feb 23, 2026In this paper, we present Laplacian multiscale flow matching (LapFlow), a novel framework that enhances flow matching by leveraging multi-scale representations for image generative modeling. Our approach decomposes images into Laplacian pyramid residuals and processes different scales in parallel through a mixture-of-transformers (MoT) architecture with causal attention mechanisms. Unlike previous cascaded approaches that require explicit renoising between scales, our model generates multi-scale representations in parallel, eliminating the need for bridging processes. The proposed multi-scale architecture not only improves generation quality but also accelerates the sampling process and promotes scaling flow matching methods. Through extensive experimentation on CelebA-HQ and ImageNet, we demonstrate that our method achieves superior sample quality with fewer GFLOPs and faster inference compared to single-scale and multi-scale flow matching baselines. The proposed model scales effectively to high-resolution generation (up to 1024$\times$1024) while maintaining lower computational overhead.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Clarify Before You Draw: Proactive Agents for Robust Text-to-CAD Generation
Feb 03, 2026Large language models have recently enabled text-to-CAD systems that synthesize parametric CAD programs (e.g., CadQuery) from natural language prompts. In practice, however, geometric descriptions can be under-specified or internally inconsistent: critical dimensions may be missing and constraints may conflict. Existing fine-tuned models tend to reactively follow user instructions and hallucinate dimensions when the text is ambiguous. To address this, we propose a proactive agentic framework for text-to-CadQuery generation, named ProCAD, that resolves specification issues before code synthesis. Our framework pairs a proactive clarifying agent, which audits the prompt and asks targeted clarification questions only when necessary to produce a self-consistent specification, with a CAD coding agent that translates the specification into an executable CadQuery program. We fine-tune the coding agent on a curated high-quality text-to-CadQuery dataset and train the clarifying agent via agentic SFT on clarification trajectories. Experiments show that proactive clarification significantly improves robustness to ambiguous prompts while keeping interaction overhead low. ProCAD outperforms frontier closed-source models, including Claude Sonnet 4.5, reducing the mean Chamfer distance by 79.9 percent and lowering the invalidity ratio from 4.8 percent to 0.9 percent. Our code and datasets will be made publicly available.
MV-S2V: Multi-View Subject-Consistent Video Generation
Jan 27, 2026Existing Subject-to-Video Generation (S2V) methods have achieved high-fidelity and subject-consistent video generation, yet remain constrained to single-view subject references. This limitation renders the S2V task reducible to an S2I + I2V pipeline, failing to exploit the full potential of video subject control. In this work, we propose and address the challenging Multi-View S2V (MV-S2V) task, which synthesizes videos from multiple reference views to enforce 3D-level subject consistency. Regarding the scarcity of training data, we first develop a synthetic data curation pipeline to generate highly customized synthetic data, complemented by a small-scale real-world captured dataset to boost the training of MV-S2V. Another key issue lies in the potential confusion between cross-subject and cross-view references in conditional generation. To overcome this, we further introduce Temporally Shifted RoPE (TS-RoPE) to distinguish between different subjects and distinct views of the same subject in reference conditioning. Our framework achieves superior 3D subject consistency w.r.t. multi-view reference images and high-quality visual outputs, establishing a new meaningful direction for subject-driven video generation. Our project page is available at: https://szy-young.github.io/mv-s2v
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
CETCAM: Camera-Controllable Video Generation via Consistent and Extensible Tokenization
Dec 22, 2025



Achieving precise camera control in video generation remains challenging, as existing methods often rely on camera pose annotations that are difficult to scale to large and dynamic datasets and are frequently inconsistent with depth estimation, leading to train-test discrepancies. We introduce CETCAM, a camera-controllable video generation framework that eliminates the need for camera annotations through a consistent and extensible tokenization scheme. CETCAM leverages recent advances in geometry foundation models, such as VGGT, to estimate depth and camera parameters and converts them into unified, geometry-aware tokens. These tokens are seamlessly integrated into a pretrained video diffusion backbone via lightweight context blocks. Trained in two progressive stages, CETCAM first learns robust camera controllability from diverse raw video data and then refines fine-grained visual quality using curated high-fidelity datasets. Extensive experiments across multiple benchmarks demonstrate state-of-the-art geometric consistency, temporal stability, and visual realism. Moreover, CETCAM exhibits strong adaptability to additional control modalities, including inpainting and layout control, highlighting its flexibility beyond camera control. The project page is available at https://sjtuytc.github.io/CETCam_project_page.github.io/.
Grounding and Enhancing Grid-based Models for Neural Fields
Apr 06, 2024Many contemporary studies utilize grid-based models for neural field representation, but a systematic analysis of grid-based models is still missing, hindering the improvement of those models. Therefore, this paper introduces a theoretical framework for grid-based models. This framework points out that these models' approximation and generalization behaviors are determined by grid tangent kernels (GTK), which are intrinsic properties of grid-based models. The proposed framework facilitates a consistent and systematic analysis of diverse grid-based models. Furthermore, the introduced framework motivates the development of a novel grid-based model named the Multiplicative Fourier Adaptive Grid (MulFAGrid). The numerical analysis demonstrates that MulFAGrid exhibits a lower generalization bound than its predecessors, indicating its robust generalization performance. Empirical studies reveal that MulFAGrid achieves state-of-the-art performance in various tasks, including 2D image fitting, 3D signed distance field (SDF) reconstruction, and novel view synthesis, demonstrating superior representation ability. The project website is available at https://sites.google.com/view/cvpr24-2034-submission/home.
CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model
Oct 10, 2023Code Large Language Models (Code LLMs) have gained significant attention in the industry due to their wide applications in the full lifecycle of software engineering. However, the effectiveness of existing models in understanding non-English inputs for multi-lingual code-related tasks is still far from well studied. This paper introduces CodeFuse-13B, an open-sourced pre-trained code LLM. It is specifically designed for code-related tasks with both English and Chinese prompts and supports over 40 programming languages. CodeFuse achieves its effectiveness by utilizing a high quality pre-training dataset that is carefully filtered by program analyzers and optimized during the training process. Extensive experiments are conducted using real-world usage scenarios, the industry-standard benchmark HumanEval-x, and the specially designed CodeFuseEval for Chinese prompts. To assess the effectiveness of CodeFuse, we actively collected valuable human feedback from the AntGroup's software development process where CodeFuse has been successfully deployed. The results demonstrate that CodeFuse-13B achieves a HumanEval pass@1 score of 37.10%, positioning it as one of the top multi-lingual code LLMs with similar parameter sizes. In practical scenarios, such as code generation, code translation, code comments, and testcase generation, CodeFuse performs better than other models when confronted with Chinese prompts.
End-to-end View Synthesis via NeRF Attention
Aug 01, 2022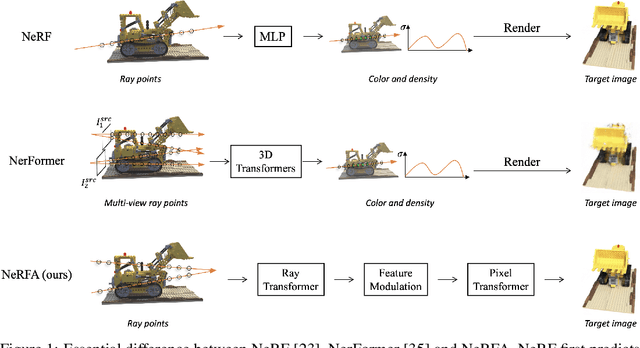
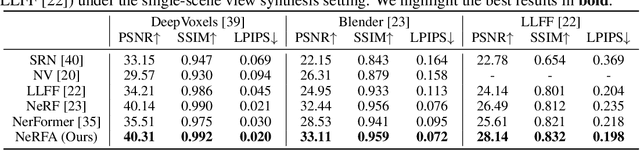
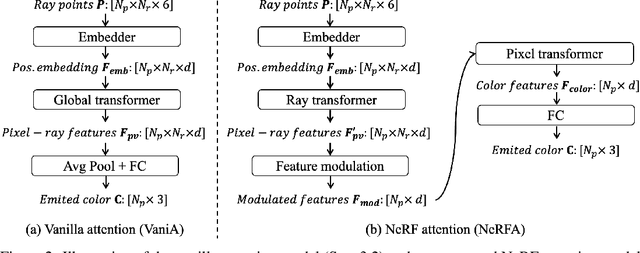
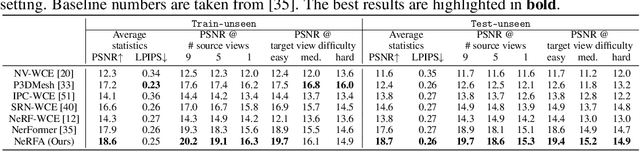
In this paper, we present a simple seq2seq formulation for view synthesis where we take a set of ray points as input and output colors corresponding to the rays. Directly applying a standard transformer on this seq2seq formulation has two limitations. First, the standard attention cannot successfully fit the volumetric rendering procedure, and therefore high-frequency components are missing in the synthesized views. Second, applying global attention to all rays and pixels is extremely inefficient. Inspired by the neural radiance field (NeRF), we propose the NeRF attention (NeRFA) to address the above problems. On the one hand, NeRFA considers the volumetric rendering equation as a soft feature modulation procedure. In this way, the feature modulation enhances the transformers with the NeRF-like inductive bias. On the other hand, NeRFA performs multi-stage attention to reduce the computational overhead. Furthermore, the NeRFA model adopts the ray and pixel transformers to learn the interactions between rays and pixels. NeRFA demonstrates superior performance over NeRF and NerFormer on four datasets: DeepVoxels, Blender, LLFF, and CO3D. Besides, NeRFA establishes a new state-of-the-art under two settings: the single-scene view synthesis and the category-centric novel view synthesis. The code will be made publicly available.