 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025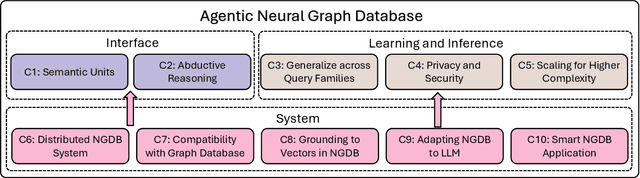
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Zero-Indexing Internet Search Augmented Generation for Large Language Models
Nov 29, 2024Retrieval augmented generation has emerged as an effective method to enhance large language model performance. This approach typically relies on an internal retrieval module that uses various indexing mechanisms to manage a static pre-processed corpus. However, such a paradigm often falls short when it is necessary to integrate the most up-to-date information that has not been updated into the corpus during generative inference time. In this paper, we explore an alternative approach that leverages standard search engine APIs to dynamically integrate the latest online information (without maintaining any index for any fixed corpus), thereby improving the quality of generated content. We design a collaborative LLM-based paradigm, where we include: (i) a parser-LLM that determines if the Internet augmented generation is demanded and extracts the search keywords if so with a single inference; (ii) a mixed ranking strategy that re-ranks the retrieved HTML files to eliminate bias introduced from the search engine API; and (iii) an extractor-LLM that can accurately and efficiently extract relevant information from the fresh content in each HTML file. We conduct extensive empirical studies to evaluate the performance of this Internet search augmented generation paradigm. The experimental results demonstrate that our method generates content with significantly improved quality. Our system has been successfully deployed in a production environment to serve 01.AI's generative inference requests.
TQA-Bench: Evaluating LLMs for Multi-Table Question Answering with Scalable Context and Symbolic Extension
Nov 29, 2024The advent of large language models (LLMs) has unlocked great opportunities in complex data management tasks, particularly in question answering (QA) over complicated multi-table relational data. Despite significant progress, systematically evaluating LLMs on multi-table QA remains a critical challenge due to the inherent complexity of analyzing heterogeneous table structures and potential large scale of serialized relational data. Existing benchmarks primarily focus on single-table QA, failing to capture the intricacies of reasoning across multiple relational tables, as required in real-world domains such as finance, healthcare, and e-commerce. To address this gap, we present TQA-Bench, a new multi-table QA benchmark designed to evaluate the capabilities of LLMs in tackling complex QA tasks over relational data. Our benchmark incorporates diverse relational database instances sourced from real-world public datasets and introduces a flexible sampling mechanism to create tasks with varying multi-table context lengths, ranging from 8K to 64K tokens. To ensure robustness and reliability, we integrate symbolic extensions into the evaluation framework, enabling the assessment of LLM reasoning capabilities beyond simple data retrieval or probabilistic pattern matching. We systematically evaluate a range of LLMs, both open-source and closed-source, spanning model scales from 7 billion to 70 billion parameters. Our extensive experiments reveal critical insights into the performance of LLMs in multi-table QA, highlighting both challenges and opportunities for advancing their application in complex, data-driven environments. Our benchmark implementation and results are available at https://github.com/Relaxed-System-Lab/TQA-Bench.
Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining
Oct 10, 2024



Efficient data selection is crucial to accelerate the pretraining of large language models (LLMs). While various methods have been proposed to enhance data efficiency, limited research has addressed the inherent conflicts between these approaches to achieve optimal data selection for LLM pretraining. To tackle this problem, we propose a novel multi-agent collaborative data selection mechanism. In this framework, each data selection method serves as an independent agent, and an agent console is designed to dynamically integrate the information from all agents throughout the LLM training process. We conduct extensive empirical studies to evaluate our multi-agent framework. The experimental results demonstrate that our approach significantly improves data efficiency, accelerates convergence in LLM training, and achieves an average performance gain of 10.5% across multiple language model benchmarks compared to the state-of-the-art methods.
Model-GLUE: Democratized LLM Scaling for A Large Model Zoo in the Wild
Oct 07, 2024



As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has garnered significant attention, which faces the challenge of decreasing performance when combining disparate models. Various techniques have been proposed for the aggregation of pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed. In light of this research gap, this paper introduces Model-GLUE, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate an strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization. Our methodology involves the clustering of mergeable models and optimal merging strategy selection, and the integration of clusters through a model mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, Model-GLUE shows an average performance enhancement of 5.61%, achieved without additional training. Codes are available at: https://github.com/Model-GLUE/Model-GLUE.
Locret: Enhancing Eviction in Long-Context LLM Inference with Trained Retaining Heads
Oct 02, 2024



Large language models (LLMs) have shown remarkable advances in supporting long-context comprehension and processing tasks. However, scaling the generation inference of LLMs to such long contexts incurs significant additional computation load, and demands a substantial GPU memory footprint to maintain the key-value (KV) cache of transformer-based LLMs. Existing KV cache compression methods, such as quantization, face memory bottlenecks as context length increases, while static-sized caches, such as eviction, suffer from inefficient policies. These limitations restrict deployment on consumer-grade devices like a single Nvidia 4090 GPU. To overcome this, we propose Locret, a framework for long-context LLM inference that introduces retaining heads to evaluate the causal importance of KV cache units, allowing for more accurate eviction within a fixed cache size. Locret is fine-tuned on top of the frozen backbone LLM using a minimal amount of data from standard long-context SFT datasets. During inference, we evict low-importance cache units along with a chunked prefill pattern, significantly reducing peak GPU memory usage. We conduct an extensive empirical study to evaluate Locret, where the experimental results show that Locret outperforms the recent competitive approaches, including InfLLM, Quantization, SirLLM, and MInference, in terms of memory efficiency and the quality of generated contents -- Locret achieves over a 20x and 8x KV cache compression ratio compared to the full KV cache for Phi-3-mini-128K and Llama-3.1-8B-instruct. Additionally, Locret can be combined with other methods, such as quantization and token merging. To our knowledge, Locret is the first framework capable of deploying Llama-3.1-8B or similar models on a single Nvidia 4090 GPU, enabling 128K long-context inference without compromising generation quality, and requiring little additional system optimizations.
On the Opportunities of (Re)-Exploring Atmospheric Science by Foundation Models: A Case Study
Jul 25, 2024



Most state-of-the-art AI applications in atmospheric science are based on classic deep learning approaches. However, such approaches cannot automatically integrate multiple complicated procedures to construct an intelligent agent, since each functionality is enabled by a separate model learned from independent climate datasets. The emergence of foundation models, especially multimodal foundation models, with their ability to process heterogeneous input data and execute complex tasks, offers a substantial opportunity to overcome this challenge. In this report, we want to explore a central question - how the state-of-the-art foundation model, i.e., GPT-4o, performs various atmospheric scientific tasks. Toward this end, we conduct a case study by categorizing the tasks into four main classes, including climate data processing, physical diagnosis, forecast and prediction, and adaptation and mitigation. For each task, we comprehensively evaluate the GPT-4o's performance along with a concrete discussion. We hope that this report may shed new light on future AI applications and research in atmospheric science.
A Survey of Multimodal Large Language Model from A Data-centric Perspective
May 26, 2024



Human beings perceive the world through diverse senses such as sight, smell, hearing, and touch. Similarly, multimodal large language models (MLLMs) enhance the capabilities of traditional large language models by integrating and processing data from multiple modalities including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for datasets and review benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Apr 09, 2024



In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
DeFT: Flash Tree-attention with IO-Awareness for Efficient Tree-search-based LLM Inference
Mar 30, 2024Decoding using tree search can greatly enhance the inference quality for transformer-based Large Language Models (LLMs). Depending on the guidance signal, it searches for the best path from root to leaf in the tree by forming LLM outputs to improve controllability, reasoning ability, alignment, et cetera. However, current tree decoding strategies and their inference systems do not suit each other well due to redundancy in computation, memory footprints, and memory access, resulting in inefficient inference. To address this issue, we propose DeFT, an IO-aware tree attention algorithm that maintains memory-efficient attention calculation with low memory footprints in two stages: (1) QKV Preparation: we propose a KV-Guided Tree Split strategy to group QKV wisely for high utilization of GPUs and reduction of memory reads/writes for the KV cache between GPU global memory and on-chip shared memory as much as possible; (2) Attention Calculation: we calculate partial attention of each QKV groups in a fused kernel then apply a Tree-topology-aware Global Reduction strategy to get final attention. Thanks to a reduction in KV cache IO by 3.6-4.5$\times$, along with an additional reduction in IO for $\mathbf{Q} \mathbf{K}^\top$ and Softmax equivalent to 25% of the total KV cache IO, DeFT can achieve a speedup of 1.7-2.4$\times$ in end-to-end latency across two practical reasoning tasks over the SOTA attention algorithms.