 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSampling: Search for Effective Data Sampling Schedules
May 28, 2021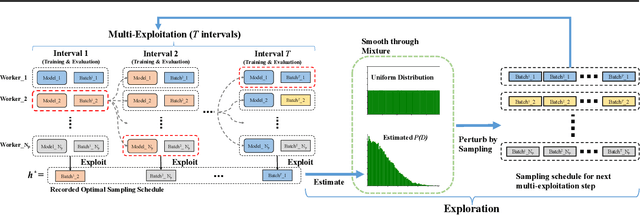
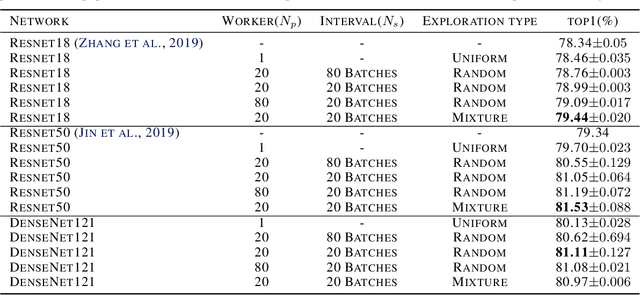

Data sampling acts as a pivotal role in training deep learning models. However, an effective sampling schedule is difficult to learn due to the inherently high dimension of parameters in learning the sampling schedule. In this paper, we propose an AutoSampling method to automatically learn sampling schedules for model training, which consists of the multi-exploitation step aiming for optimal local sampling schedules and the exploration step for the ideal sampling distribution. More specifically, we achieve sampling schedule search with shortened exploitation cycle to provide enough supervision. In addition, we periodically estimate the sampling distribution from the learned sampling schedules and perturb it to search in the distribution space. The combination of two searches allows us to learn a robust sampling schedule. We apply our AutoSampling method to a variety of image classification tasks illustrating the effectiveness of the proposed method.
* Automl for sampling firstly without any assumpation
Action Segmentation with Mixed Temporal Domain Adaptation
Apr 16, 2021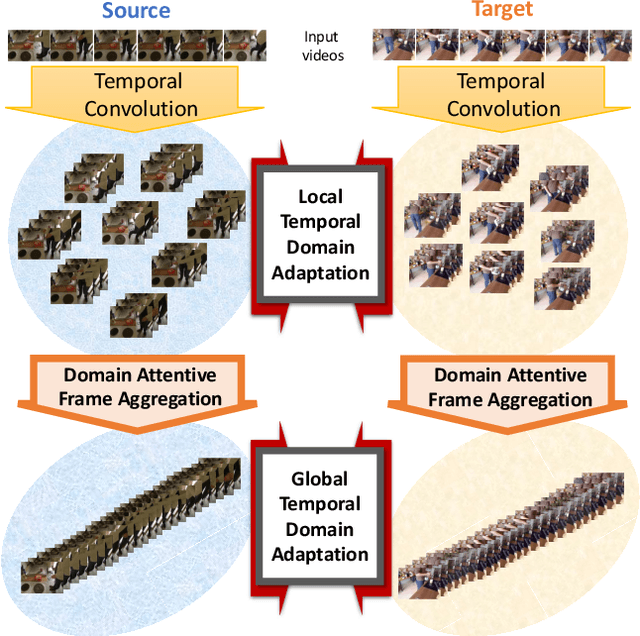
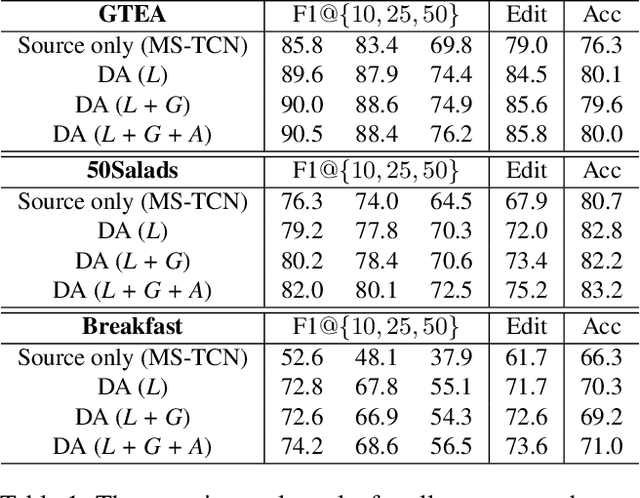
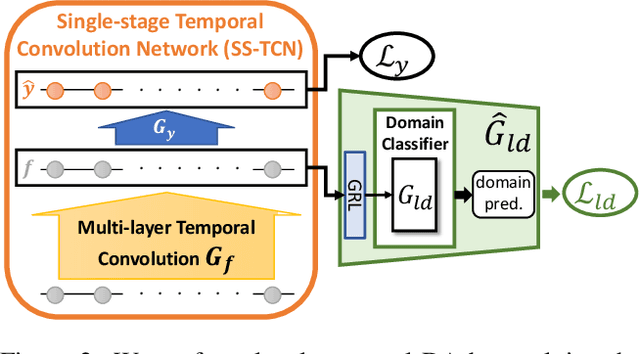
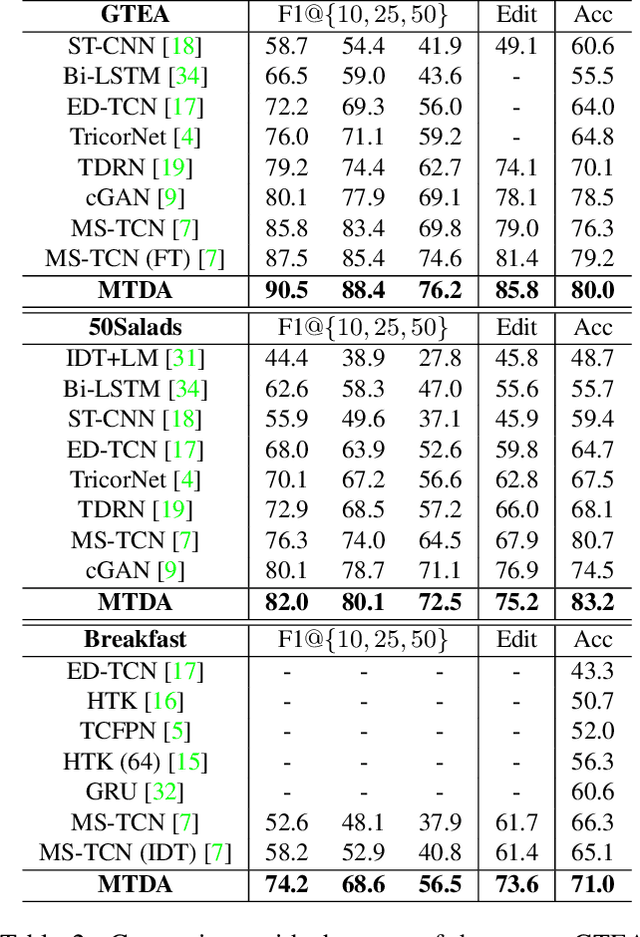
The main progress for action segmentation comes from densely-annotated data for fully-supervised learning. Since manual annotation for frame-level actions is time-consuming and challenging, we propose to exploit auxiliary unlabeled videos, which are much easier to obtain, by shaping this problem as a domain adaptation (DA) problem. Although various DA techniques have been proposed in recent years, most of them have been developed only for the spatial direction. Therefore, we propose Mixed Temporal Domain Adaptation (MTDA) to jointly align frame- and video-level embedded feature spaces across domains, and further integrate with the domain attention mechanism to focus on aligning the frame-level features with higher domain discrepancy, leading to more effective domain adaptation. Finally, we evaluate our proposed methods on three challenging datasets (GTEA, 50Salads, and Breakfast), and validate that MTDA outperforms the current state-of-the-art methods on all three datasets by large margins (e.g. 6.4% gain on F1@50 and 6.8% gain on the edit score for GTEA).
No Need for Interactions: Robust Model-Based Imitation Learning using Neural ODE
Apr 03, 2021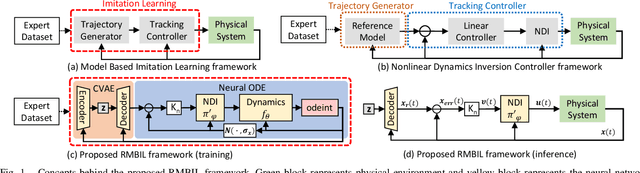
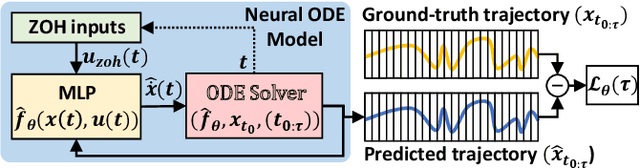
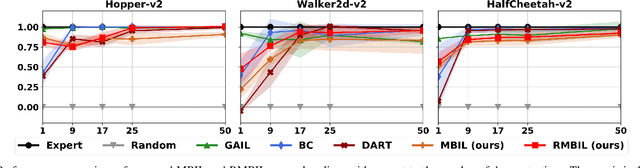
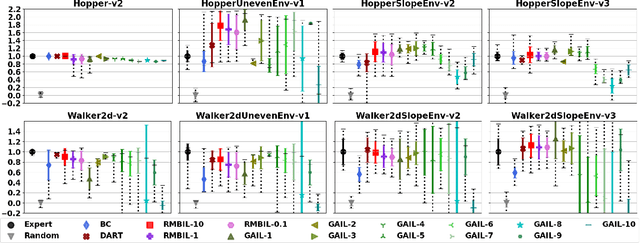
Interactions with either environments or expert policies during training are needed for most of the current imitation learning (IL) algorithms. For IL problems with no interactions, a typical approach is Behavior Cloning (BC). However, BC-like methods tend to be affected by distribution shift. To mitigate this problem, we come up with a Robust Model-Based Imitation Learning (RMBIL) framework that casts imitation learning as an end-to-end differentiable nonlinear closed-loop tracking problem. RMBIL applies Neural ODE to learn a precise multi-step dynamics and a robust tracking controller via Nonlinear Dynamics Inversion (NDI) algorithm. Then, the learned NDI controller will be combined with a trajectory generator, a conditional VAE, to imitate an expert's behavior. Theoretical derivation shows that the controller network can approximate an NDI when minimizing the training loss of Neural ODE. Experiments on Mujoco tasks also demonstrate that RMBIL is competitive to the state-of-the-art generative adversarial method (GAIL) and achieves at least 30% performance gain over BC in uneven surfaces.
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
Mar 24, 2021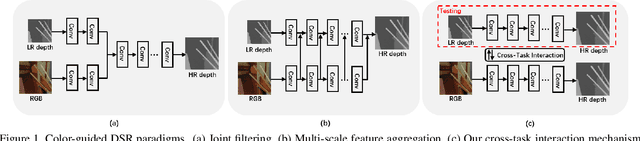
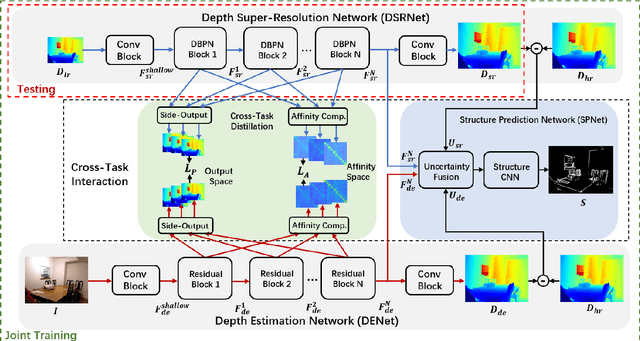
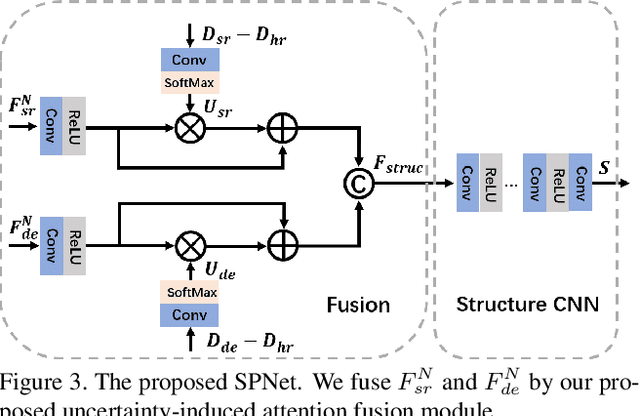

Existing color-guided depth super-resolution (DSR) approaches require paired RGB-D data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, we explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Our key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, we construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross task knowledge transfer. First, we design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, we advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that our scheme achieves superior performance in comparison with other DSR methods.
MetaCorrection: Domain-aware Meta Loss Correction for Unsupervised Domain Adaptation in Semantic Segmentation
Mar 09, 2021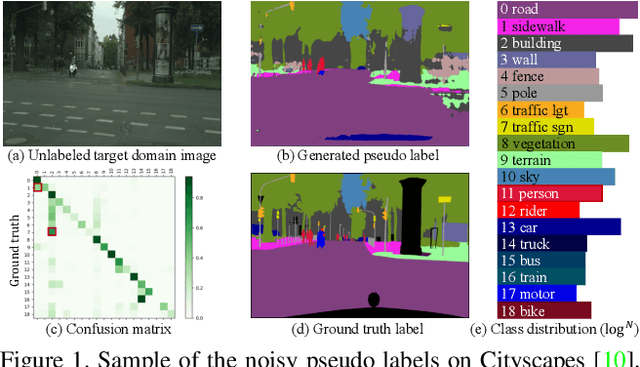
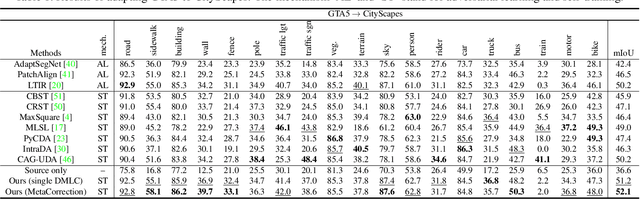
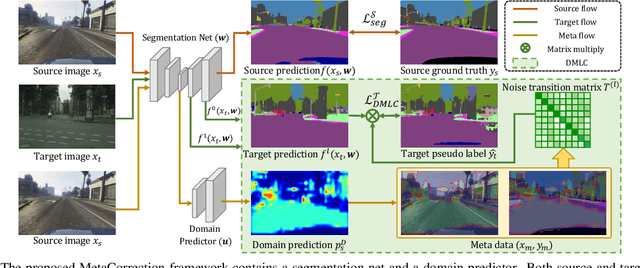
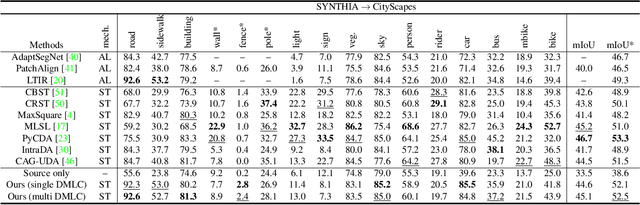
Unsupervised domain adaptation (UDA) aims to transfer the knowledge from the labeled source domain to the unlabeled target domain. Existing self-training based UDA approaches assign pseudo labels for target data and treat them as ground truth labels to fully leverage unlabeled target data for model adaptation. However, the generated pseudo labels from the model optimized on the source domain inevitably contain noise due to the domain gap. To tackle this issue, we advance a MetaCorrection framework, where a Domain-aware Meta-learning strategy is devised to benefit Loss Correction (DMLC) for UDA semantic segmentation. In particular, we model the noise distribution of pseudo labels in target domain by introducing a noise transition matrix (NTM) and construct meta data set with domain-invariant source data to guide the estimation of NTM. Through the risk minimization on the meta data set, the optimized NTM thus can correct the noisy issues in pseudo labels and enhance the generalization ability of the model on the target data. Considering the capacity gap between shallow and deep features, we further employ the proposed DMLC strategy to provide matched and compatible supervision signals for different level features, thereby ensuring deep adaptation. Extensive experimental results highlight the effectiveness of our method against existing state-of-the-art methods on three benchmarks.
A Unified Joint Maximum Mean Discrepancy for Domain Adaptation
Jan 25, 2021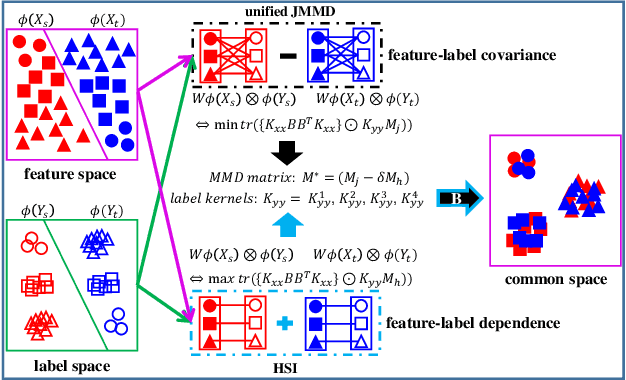
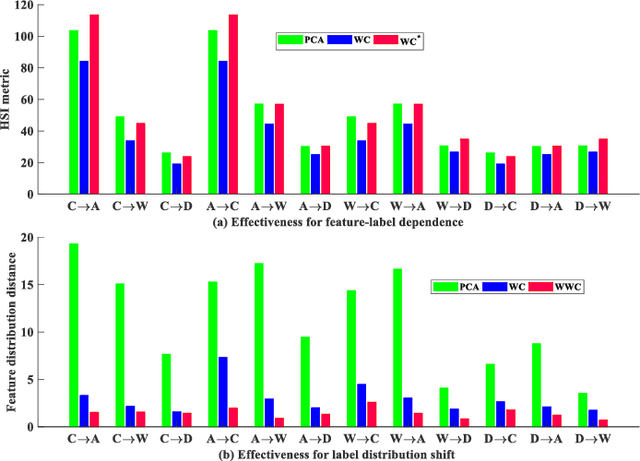
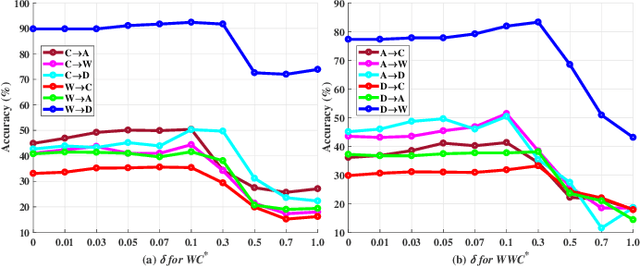
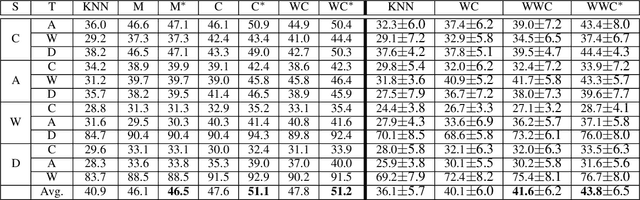
Domain adaptation has received a lot of attention in recent years, and many algorithms have been proposed with impressive progress. However, it is still not fully explored concerning the joint probability distribution (P(X, Y)) distance for this problem, since its empirical estimation derived from the maximum mean discrepancy (joint maximum mean discrepancy, JMMD) will involve complex tensor-product operator that is hard to manipulate. To solve this issue, this paper theoretically derives a unified form of JMMD that is easy to optimize, and proves that the marginal, class conditional and weighted class conditional probability distribution distances are our special cases with different label kernels, among which the weighted class conditional one not only can realize feature alignment across domains in the category level, but also deal with imbalance dataset using the class prior probabilities. From the revealed unified JMMD, we illustrate that JMMD degrades the feature-label dependence (discriminability) that benefits to classification, and it is sensitive to the label distribution shift when the label kernel is the weighted class conditional one. Therefore, we leverage Hilbert Schmidt independence criterion and propose a novel MMD matrix to promote the dependence, and devise a novel label kernel that is robust to label distribution shift. Finally, we conduct extensive experiments on several cross-domain datasets to demonstrate the validity and effectiveness of the revealed theoretical results.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
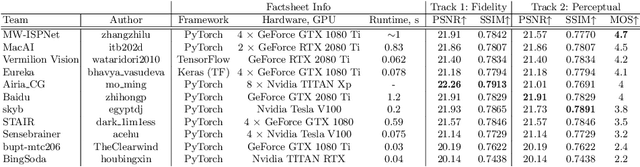
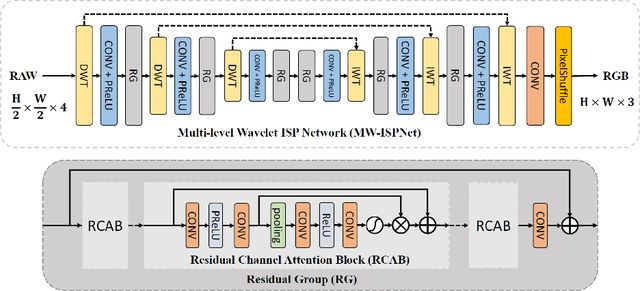
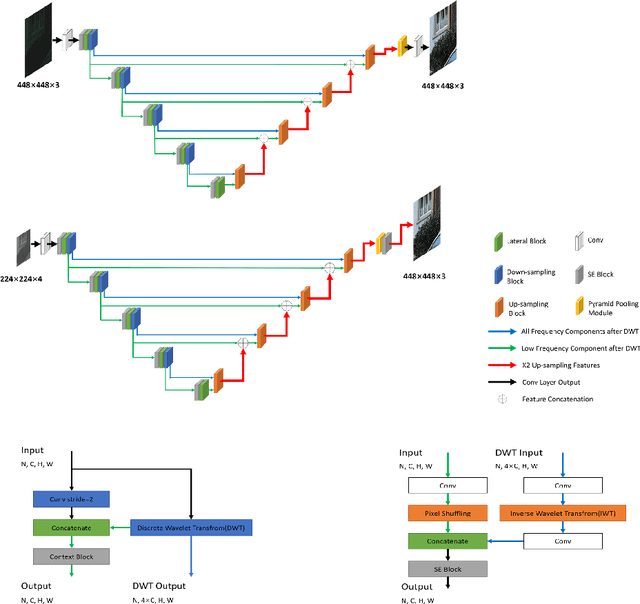
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
AutoPruning for Deep Neural Network with Dynamic Channel Masking
Nov 02, 2020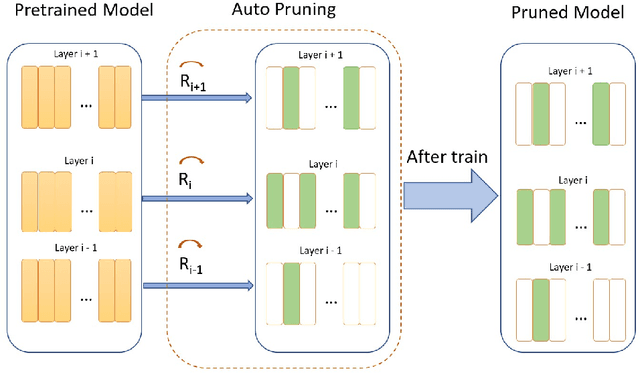
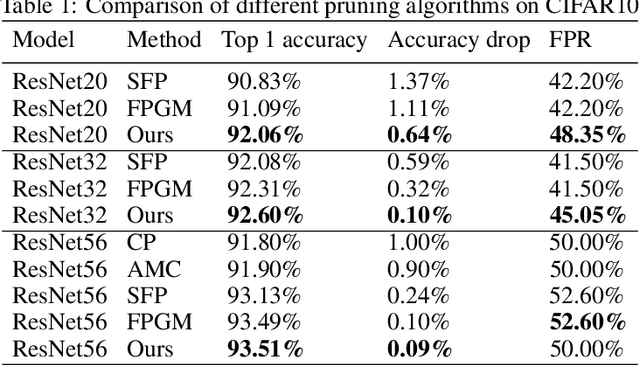
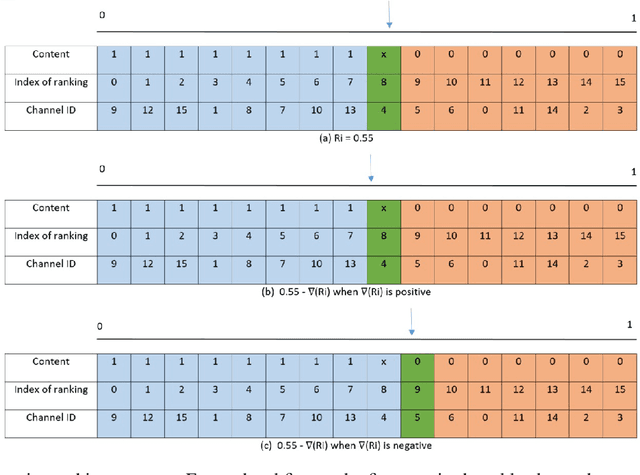
Modern deep neural network models are large and computationally intensive. One typical solution to this issue is model pruning. However, most current pruning algorithms depend on hand crafted rules or domain expertise. To overcome this problem, we propose a learning based auto pruning algorithm for deep neural network, which is inspired by recent automatic machine learning(AutoML). A two objectives' problem that aims for the the weights and the best channels for each layer is first formulated. An alternative optimization approach is then proposed to derive the optimal channel numbers and weights simultaneously. In the process of pruning, we utilize a searchable hyperparameter, remaining ratio, to denote the number of channels in each convolution layer, and then a dynamic masking process is proposed to describe the corresponding channel evolution. To control the trade-off between the accuracy of a model and the pruning ratio of floating point operations, a novel loss function is further introduced. Preliminary experimental results on benchmark datasets demonstrate that our scheme achieves competitive results for neural network pruning.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020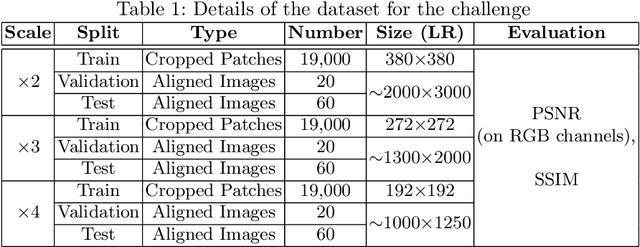
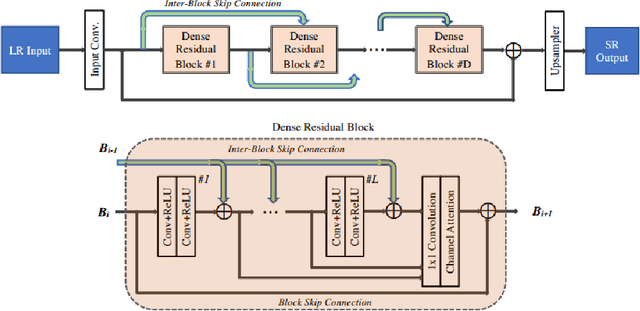
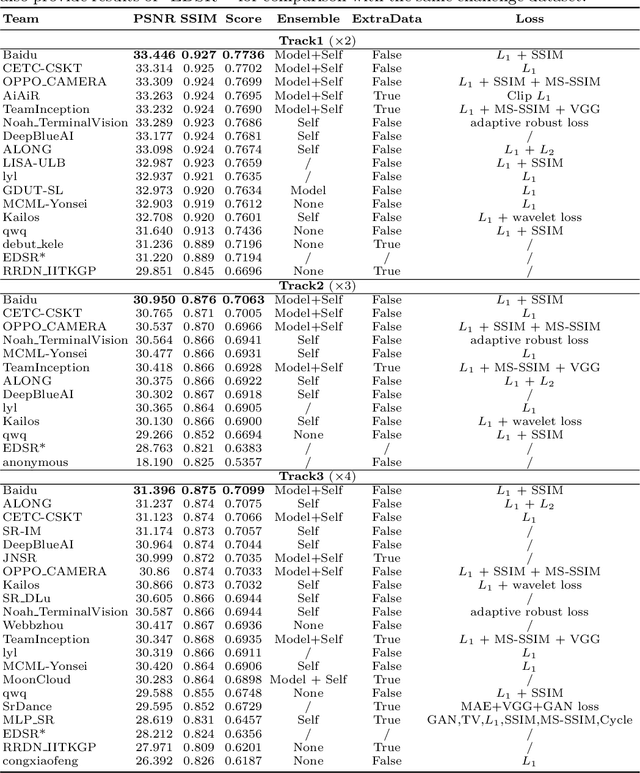
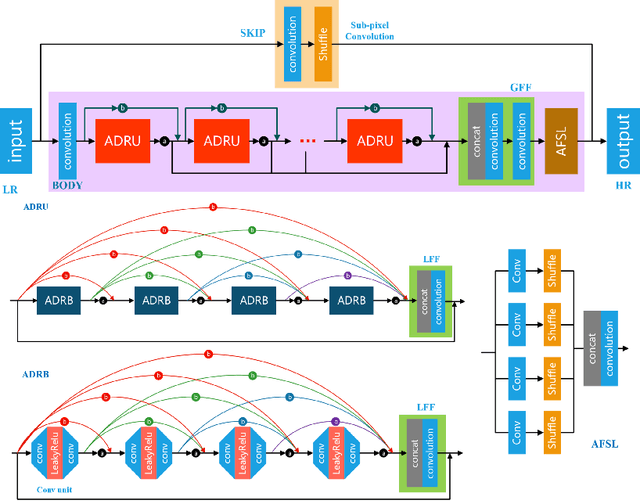
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.
SAMOT: Switcher-Aware Multi-Object Tracking and Still Another MOT Measure
Sep 22, 2020
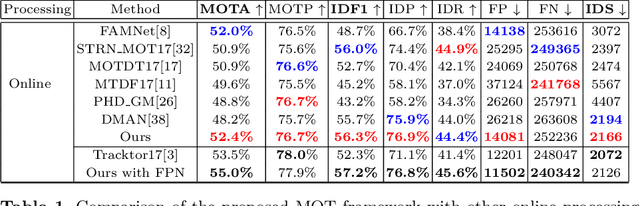
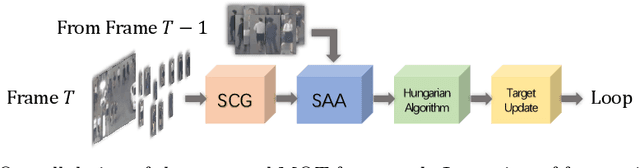
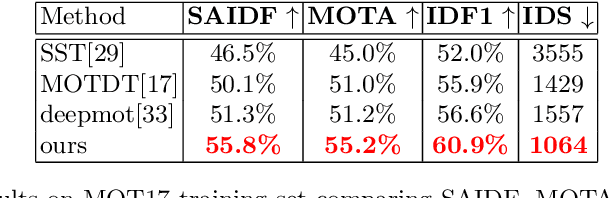
Multi-Object Tracking (MOT) is a popular topic in computer vision. However, identity issue, i.e., an object is wrongly associated with another object of a different identity, still remains to be a challenging problem. To address it, switchers, i.e., confusing targets thatmay cause identity issues, should be focused. Based on this motivation,this paper proposes a novel switcher-aware framework for multi-object tracking, which consists of Spatial Conflict Graph model (SCG) and Switcher-Aware Association (SAA). The SCG eliminates spatial switch-ers within one frame by building a conflict graph and working out the optimal subgraph. The SAA utilizes additional information from potential temporal switcher across frames, enabling more accurate data association. Besides, we propose a new MOT evaluation measure, Still Another IDF score (SAIDF), aiming to focus more on identity issues.This new measure may overcome some problems of the previous measures and provide a better insight for identity issues in MOT. Finally,the proposed framework is tested under both the traditional measures and the new measure we proposed. Extensive experiments show that ourmethod achieves competitive results on all measure.